 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Deep Models for Salient Object Detection
Paper and Code
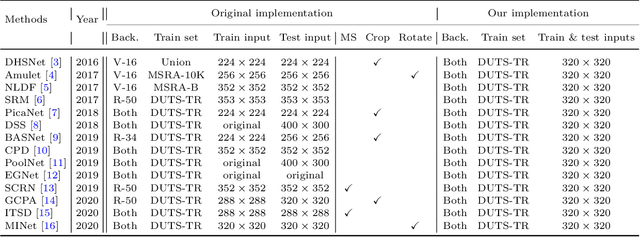

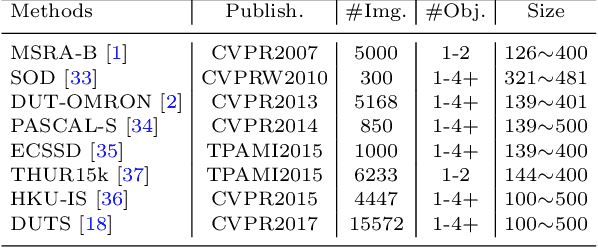

In recent years, deep network-based methods have continuously refreshed state-of-the-art performance on Salient Object Detection (SOD) task. However, the performance discrepancy caused by different implementation details may conceal the real progress in this task. Making an impartial comparison is required for future researches. To meet this need, we construct a general SALient Object Detection (SALOD) benchmark to conduct a comprehensive comparison among several representative SOD methods. Specifically, we re-implement 14 representative SOD methods by using consistent settings for training. Moreover, two additional protocols are set up in our benchmark to investigate the robustness of existing methods in some limited conditions. In the first protocol, we enlarge the difference between objectness distributions of train and test sets to evaluate the robustness of these SOD methods. In the second protocol, we build multiple train subsets with different scales to validate whether these methods can extract discriminative features from only a few samples. In the above experiments, we find that existing loss functions usually specialized in some metrics but reported inferior results on the others. Therefore, we propose a novel Edge-Aware (EA) loss that promotes deep networks to learn more discriminative features by integrating both pixel- and image-level supervision signals. Experiments prove that our EA loss reports more robust performances compared to existing losses.