 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppearance-guided Attentive Self-Paced Learning for Unsupervised Salient Object Detection
Paper and Code


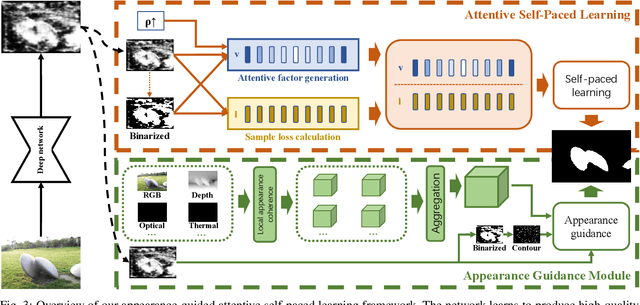
Existing Deep-Learning-based (DL-based) Unsupervised Salient Object Detection (USOD) methods learn saliency information in images based on the prior knowledge of traditional saliency methods and pretrained deep networks. However, these methods employ a simple learning strategy to train deep networks and therefore cannot properly incorporate the "hidden" information of the training samples into the learning process. Moreover, appearance information, which is crucial for segmenting objects, is only used as post-process after the network training process. To address these two issues, we propose a novel appearance-guided attentive self-paced learning framework for unsupervised salient object detection. The proposed framework integrates both self-paced learning (SPL) and appearance guidance into a unified learning framework. Specifically, for the first issue, we propose an Attentive Self-Paced Learning (ASPL) paradigm that organizes the training samples in a meaningful order to excavate gradually more detailed saliency information. Our ASPL facilitates our framework capable of automatically producing soft attention weights that measure the learning difficulty of training samples in a purely self-learning way. For the second issue, we propose an Appearance Guidance Module (AGM), which formulates the local appearance contrast of each pixel as the probability of saliency boundary and finds the potential boundary of the target objects by maximizing the probability. Furthermore, we further extend our framework to other multi-modality SOD tasks by aggregating the appearance vectors of other modality data, such as depth map, thermal image or optical flow. Extensive experiments on RGB, RGB-D, RGB-T and video SOD benchmarks prove that our framework achieves state-of-the-art performance against existing USOD methods and is comparable to the latest supervised SOD methods.