 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Diffusion Guided Refinement of 3D Scenes
Mar 19, 2025Reconstructing 3D scenes from a single image is a fundamentally ill-posed task due to the severely under-constrained nature of the problem. Consequently, when the scene is rendered from novel camera views, existing single image to 3D reconstruction methods render incoherent and blurry views. This problem is exacerbated when the unseen regions are far away from the input camera. In this work, we address these inherent limitations in existing single image-to-3D scene feedforward networks. To alleviate the poor performance due to insufficient information beyond the input image's view, we leverage a strong generative prior in the form of a pre-trained latent video diffusion model, for iterative refinement of a coarse scene represented by optimizable Gaussian parameters. To ensure that the style and texture of the generated images align with that of the input image, we incorporate on-the-fly Fourier-style transfer between the generated images and the input image. Additionally, we design a semantic uncertainty quantification module that calculates the per-pixel entropy and yields uncertainty maps used to guide the refinement process from the most confident pixels while discarding the remaining highly uncertain ones. We conduct extensive experiments on real-world scene datasets, including in-domain RealEstate-10K and out-of-domain KITTI-v2, showing that our approach can provide more realistic and high-fidelity novel view synthesis results compared to existing state-of-the-art methods.
Conformal Prediction and MLLM aided Uncertainty Quantification in Scene Graph Generation
Mar 18, 2025Scene Graph Generation (SGG) aims to represent visual scenes by identifying objects and their pairwise relationships, providing a structured understanding of image content. However, inherent challenges like long-tailed class distributions and prediction variability necessitate uncertainty quantification in SGG for its practical viability. In this paper, we introduce a novel Conformal Prediction (CP) based framework, adaptive to any existing SGG method, for quantifying their predictive uncertainty by constructing well-calibrated prediction sets over their generated scene graphs. These scene graph prediction sets are designed to achieve statistically rigorous coverage guarantees. Additionally, to ensure these prediction sets contain the most practically interpretable scene graphs, we design an effective MLLM-based post-processing strategy for selecting the most visually and semantically plausible scene graphs within these prediction sets. We show that our proposed approach can produce diverse possible scene graphs from an image, assess the reliability of SGG methods, and improve overall SGG performance.
Active Learning Guided Federated Online Adaptation: Applications in Medical Image Segmentation
Dec 08, 2023Data privacy, storage, and distribution shifts are major bottlenecks in medical image analysis. Data cannot be shared across patients, physicians, and facilities due to privacy concerns, usually requiring each patient's data to be analyzed in a discreet setting at a near real-time pace. However, one would like to take advantage of the accumulated knowledge across healthcare facilities as the computational systems analyze data of more and more patients while incorporating feedback provided by physicians to improve accuracy. Motivated by these, we propose a method for medical image segmentation that adapts to each incoming data batch (online adaptation), incorporates physician feedback through active learning, and assimilates knowledge across facilities in a federated setup. Combining an online adaptation scheme at test time with an efficient sampling strategy with budgeted annotation helps bridge the gap between the source and the incoming stream of target domain data. A federated setup allows collaborative aggregation of knowledge across distinct distributed models without needing to share the data across different models. This facilitates the improvement of performance over time by accumulating knowledge across users. Towards achieving these goals, we propose a computationally amicable, privacy-preserving image segmentation technique \textbf{DrFRODA} that uses federated learning to adapt the model in an online manner with feedback from doctors in the loop. Our experiments on publicly available datasets show that the proposed distributed active learning-based online adaptation method outperforms unsupervised online adaptation methods and shows competitive results with offline active learning-based adaptation methods.
Unbiased Scene Graph Generation in Videos
Apr 06, 2023The task of dynamic scene graph generation (SGG) from videos is complicated and challenging due to the inherent dynamics of a scene, temporal fluctuation of model predictions, and the long-tailed distribution of the visual relationships in addition to the already existing challenges in image-based SGG. Existing methods for dynamic SGG have primarily focused on capturing spatio-temporal context using complex architectures without addressing the challenges mentioned above, especially the long-tailed distribution of relationships. This often leads to the generation of biased scene graphs. To address these challenges, we introduce a new framework called TEMPURA: TEmporal consistency and Memory Prototype guided UnceRtainty Attenuation for unbiased dynamic SGG. TEMPURA employs object-level temporal consistencies via transformer-based sequence modeling, learns to synthesize unbiased relationship representations using memory-guided training, and attenuates the predictive uncertainty of visual relations using a Gaussian Mixture Model (GMM). Extensive experiments demonstrate that our method achieves significant (up to 10% in some cases) performance gain over existing methods highlighting its superiority in generating more unbiased scene graphs.
Learning Few-shot Open-set Classifiers using Exemplar Reconstruction
Jul 31, 2021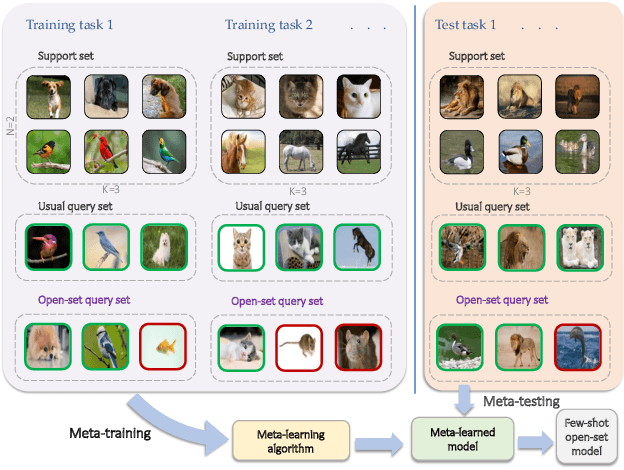
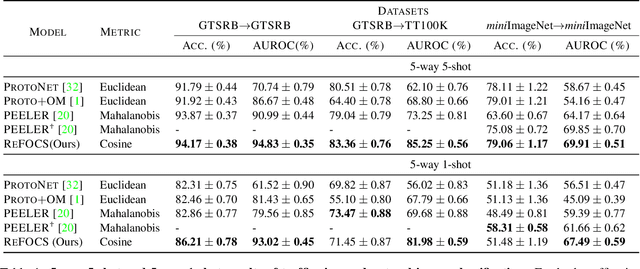
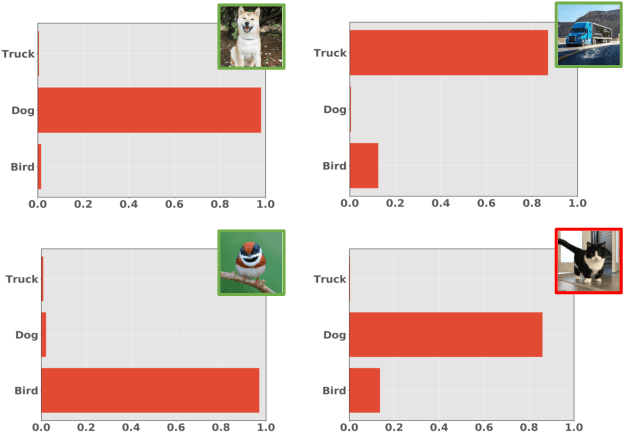

We study the problem of how to identify samples from unseen categories (open-set classification) when there are only a few samples given from the seen categories (few-shot setting). The challenge of learning a good abstraction for a class with very few samples makes it extremely difficult to detect samples from the unseen categories; consequently, open-set recognition has received minimal attention in the few-shot setting. Most open-set few-shot classification methods regularize the softmax score to indicate uniform probability for open class samples but we argue that this approach is often inaccurate, especially at a fine-grained level. Instead, we propose a novel exemplar reconstruction-based meta-learning strategy for jointly detecting open class samples, as well as, categorizing samples from seen classes via metric-based classification. The exemplars, which act as representatives of a class, can either be provided in the training dataset or estimated in the feature domain. Our framework, named Reconstructing Exemplar based Few-shot Open-set ClaSsifier (ReFOCS), is tested on a wide variety of datasets and the experimental results clearly highlight our method as the new state of the art.
Diversifying Support Vector Machines for Boosting using Kernel Perturbation: Applications to Class Imbalance and Small Disjuncts
Dec 22, 2017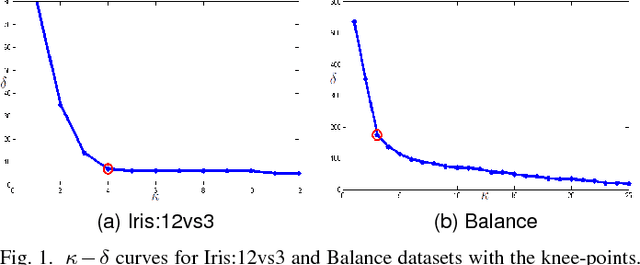
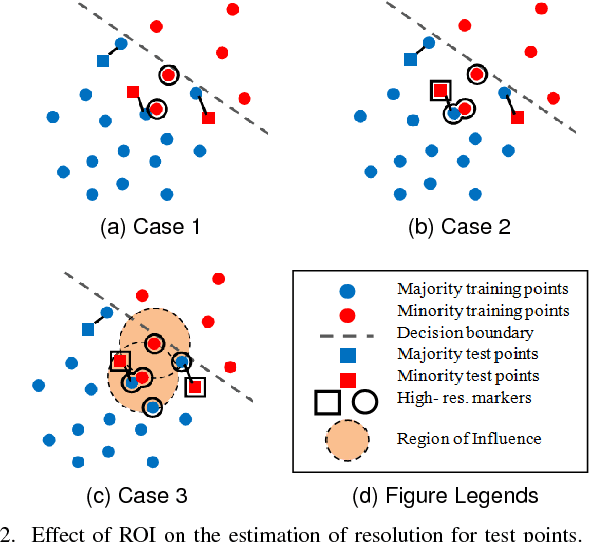
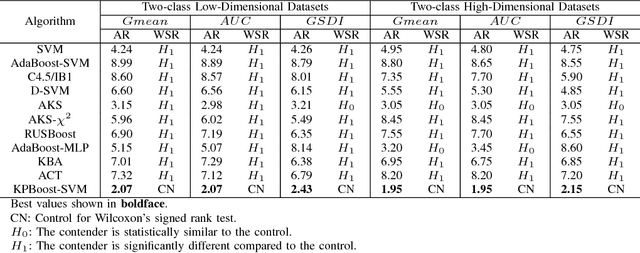
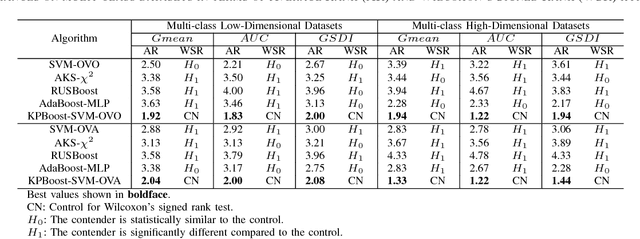
The diversification (generating slightly varying separating discriminators) of Support Vector Machines (SVMs) for boosting has proven to be a challenge due to the strong learning nature of SVMs. Based on the insight that perturbing the SVM kernel may help in diversifying SVMs, we propose two kernel perturbation based boosting schemes where the kernel is modified in each round so as to increase the resolution of the kernel-induced Reimannian metric in the vicinity of the datapoints misclassified in the previous round. We propose a method for identifying the disjuncts in a dataset, dispelling the dependence on rule-based learning methods for identifying the disjuncts. We also present a new performance measure called Geometric Small Disjunct Index (GSDI) to quantify the performance on small disjuncts for balanced as well as class imbalanced datasets. Experimental comparison with a variety of state-of-the-art algorithms is carried out using the best classifiers of each type selected by a new approach inspired by multi-criteria decision making. The proposed method is found to outperform the contending state-of-the-art methods on different datasets (ranging from mildly imbalanced to highly imbalanced and characterized by varying number of disjuncts) in terms of three different performance indices (including the proposed GSDI).