 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFortifying Fully Convolutional Generative Adversarial Networks for Image Super-Resolution Using Divergence Measures
Apr 09, 2024Super-Resolution (SR) is a time-hallowed image processing problem that aims to improve the quality of a Low-Resolution (LR) sample up to the standard of its High-Resolution (HR) counterpart. We aim to address this by introducing Super-Resolution Generator (SuRGe), a fully-convolutional Generative Adversarial Network (GAN)-based architecture for SR. We show that distinct convolutional features obtained at increasing depths of a GAN generator can be optimally combined by a set of learnable convex weights to improve the quality of generated SR samples. In the process, we employ the Jensen-Shannon and the Gromov-Wasserstein losses respectively between the SR-HR and LR-SR pairs of distributions to further aid the generator of SuRGe to better exploit the available information in an attempt to improve SR. Moreover, we train the discriminator of SuRGe with the Wasserstein loss with gradient penalty, to primarily prevent mode collapse. The proposed SuRGe, as an end-to-end GAN workflow tailor-made for super-resolution, offers improved performance while maintaining low inference time. The efficacy of SuRGe is substantiated by its superior performance compared to 18 state-of-the-art contenders on 10 benchmark datasets.
Interval Bound Propagation$\unicode{x2013}$aided Few$\unicode{x002d}$shot Learning
Apr 08, 2022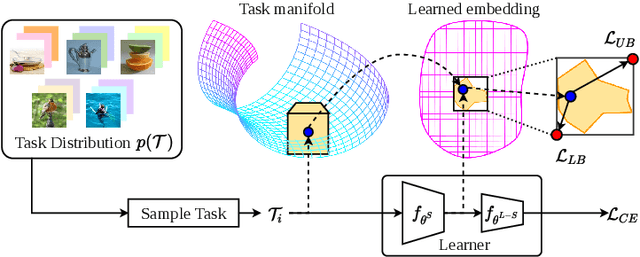
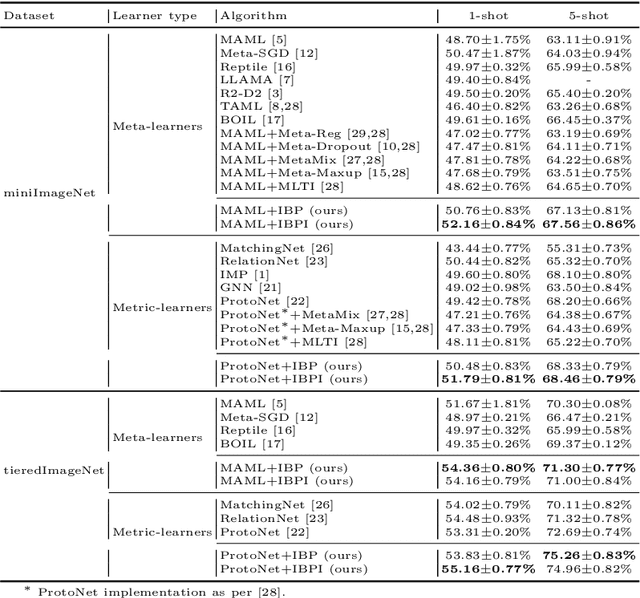
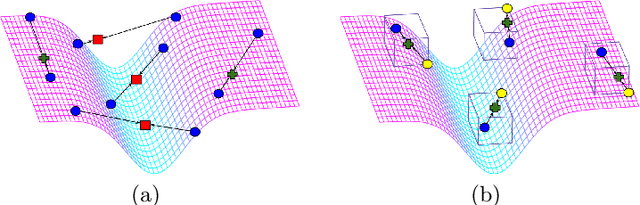
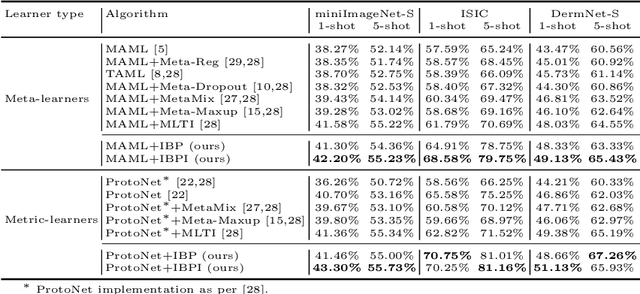
Few-shot learning aims to transfer the knowledge acquired from training on a diverse set of tasks, from a given task distribution, to generalize to unseen tasks, from the same distribution, with a limited amount of labeled data. The underlying requirement for effective few-shot generalization is to learn a good representation of the task manifold. One way to encourage this is to preserve local neighborhoods in the feature space learned by the few-shot learner. To this end, we introduce the notion of interval bounds from the provably robust training literature to few-shot learning. The interval bounds are used to characterize neighborhoods around the training tasks. These neighborhoods can then be preserved by minimizing the distance between a task and its respective bounds. We further introduce a novel strategy to artificially form new tasks for training by interpolating between the available tasks and their respective interval bounds, to aid in cases with a scarcity of tasks. We apply our framework to both model-agnostic meta-learning as well as prototype-based metric-learning paradigms. The efficacy of our proposed approach is evident from the improved performance on several datasets from diverse domains in comparison to a sizable number of recent competitors.
Appropriateness of Performance Indices for Imbalanced Data Classification: An Analysis
Aug 26, 2020
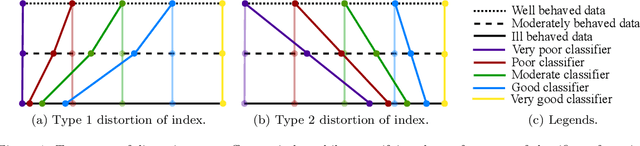
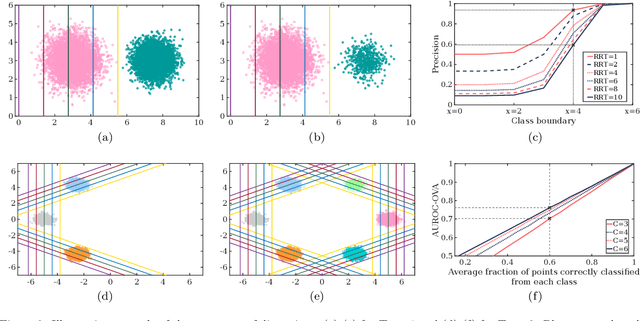
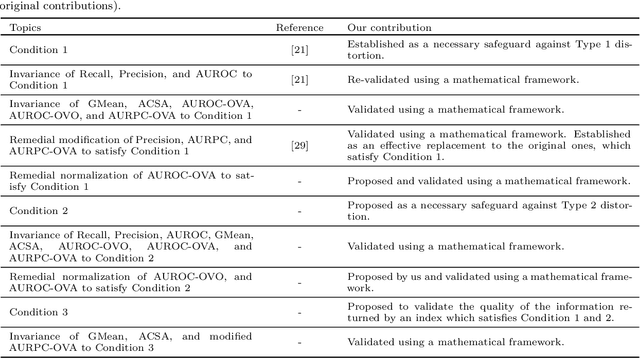
Indices quantifying the performance of classifiers under class-imbalance, often suffer from distortions depending on the constitution of the test set or the class-specific classification accuracy, creating difficulties in assessing the merit of the classifier. We identify two fundamental conditions that a performance index must satisfy to be respectively resilient to altering number of testing instances from each class and the number of classes in the test set. In light of these conditions, under the effect of class imbalance, we theoretically analyze four indices commonly used for evaluating binary classifiers and five popular indices for multi-class classifiers. For indices violating any of the conditions, we also suggest remedial modification and normalization. We further investigate the capability of the indices to retain information about the classification performance over all the classes, even when the classifier exhibits extreme performance on some classes. Simulation studies are performed on high dimensional deep representations of subset of the ImageNet dataset using four state-of-the-art classifiers tailored for handling class imbalance. Finally, based on our theoretical findings and empirical evidence, we recommend the appropriate indices that should be used to evaluate the performance of classifiers in presence of class-imbalance.
* Published in Pattern Recognition (Elsevier)
One Sparse Perturbation to Fool them All, almost Always!
Apr 30, 2020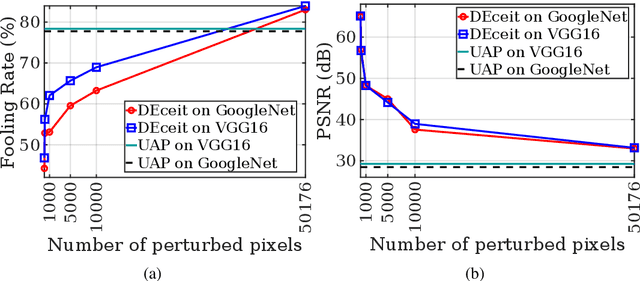
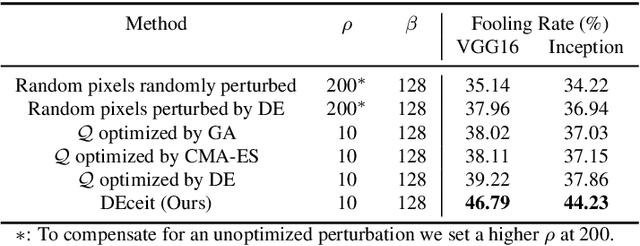
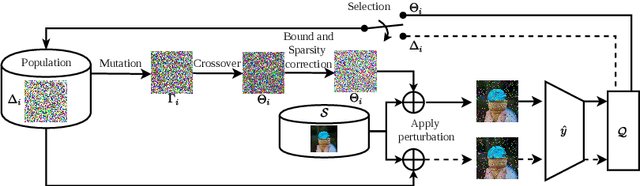
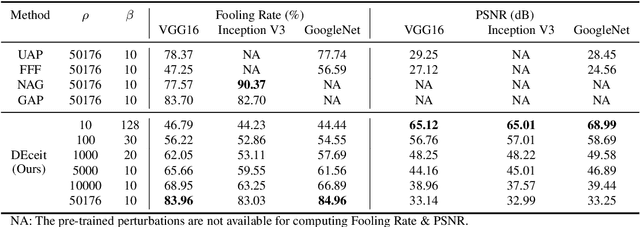
Constructing adversarial perturbations for deep neural networks is an important direction of research. Crafting image-dependent adversarial perturbations using white-box feedback has hitherto been the norm for such adversarial attacks. However, black-box attacks are much more practical for real-world applications. Universal perturbations applicable across multiple images are gaining popularity due to their innate generalizability. There have also been efforts to restrict the perturbations to a few pixels in the image. This helps to retain visual similarity with the original images making such attacks hard to detect. This paper marks an important step which combines all these directions of research. We propose the DEceit algorithm for constructing effective universal pixel-restricted perturbations using only black-box feedback from the target network. We conduct empirical investigations using the ImageNet validation set on the state-of-the-art deep neural classifiers by varying the number of pixels to be perturbed from a meagre 10 pixels to as high as all pixels in the image. We find that perturbing only about 10% of the pixels in an image using DEceit achieves a commendable and highly transferable Fooling Rate while retaining the visual quality. We further demonstrate that DEceit can be successfully applied to image dependent attacks as well. In both sets of experiments, we outperformed several state-of-the-art methods.
Generative Adversarial Minority Oversampling
Apr 03, 2019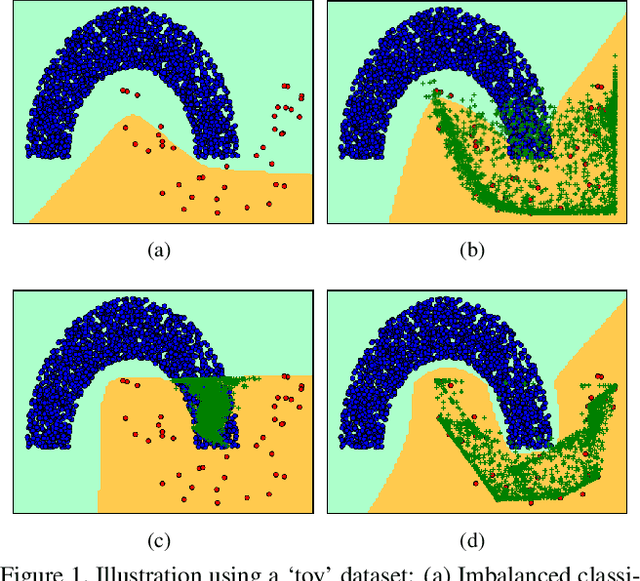
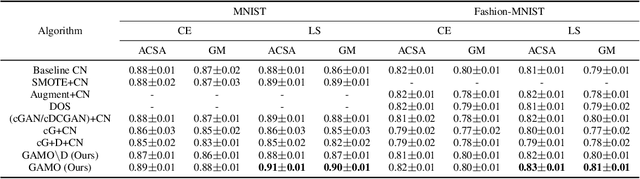
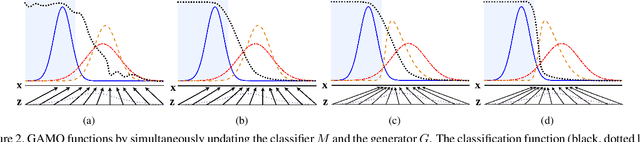
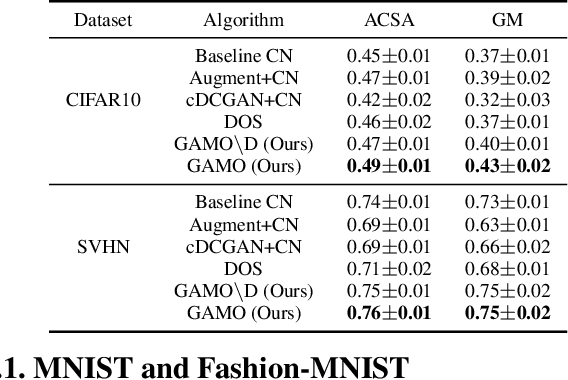
Class imbalance is a long-standing problem relevant to a number of real-world applications of deep learning. Oversampling techniques, which are effective for handling class imbalance in classical learning systems, can not be directly applied to end-to-end deep learning systems. We propose a three-player adversarial game between a convex generator, a multi-class classifier network, and a real/fake discriminator to perform oversampling in deep learning systems. The convex generator generates new samples from the minority classes as convex combinations of existing instances, aiming to fool both the discriminator as well as the classifier into misclassifying the generated samples. Consequently, the artificial samples are generated at critical locations near the peripheries of the classes. This, in turn, adjusts the classifier induced boundaries in a way which is more likely to reduce misclassification from the minority classes. Extensive experiments on multiple class imbalanced image datasets establish the efficacy of our proposal.
Diversifying Support Vector Machines for Boosting using Kernel Perturbation: Applications to Class Imbalance and Small Disjuncts
Dec 22, 2017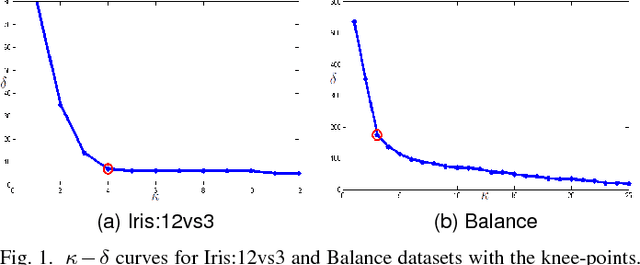
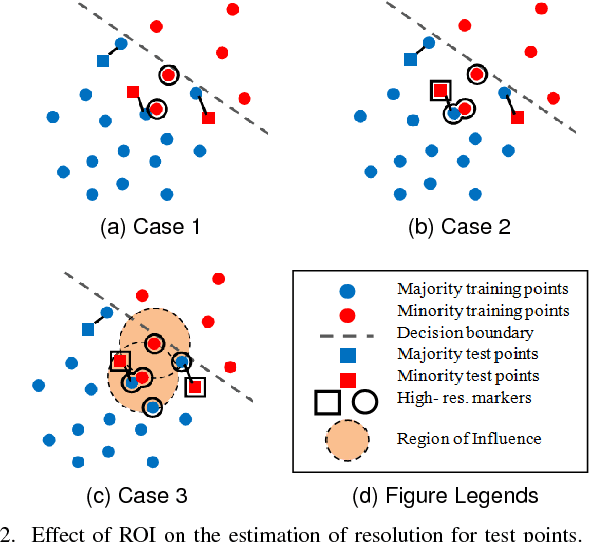
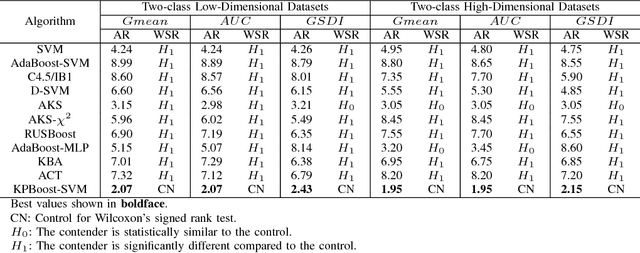
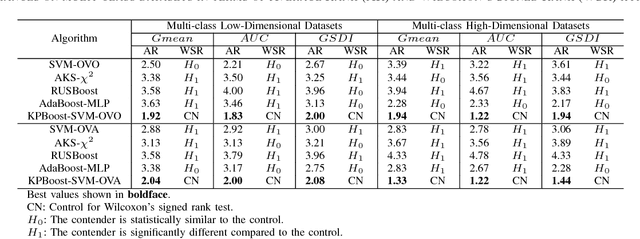
The diversification (generating slightly varying separating discriminators) of Support Vector Machines (SVMs) for boosting has proven to be a challenge due to the strong learning nature of SVMs. Based on the insight that perturbing the SVM kernel may help in diversifying SVMs, we propose two kernel perturbation based boosting schemes where the kernel is modified in each round so as to increase the resolution of the kernel-induced Reimannian metric in the vicinity of the datapoints misclassified in the previous round. We propose a method for identifying the disjuncts in a dataset, dispelling the dependence on rule-based learning methods for identifying the disjuncts. We also present a new performance measure called Geometric Small Disjunct Index (GSDI) to quantify the performance on small disjuncts for balanced as well as class imbalanced datasets. Experimental comparison with a variety of state-of-the-art algorithms is carried out using the best classifiers of each type selected by a new approach inspired by multi-criteria decision making. The proposed method is found to outperform the contending state-of-the-art methods on different datasets (ranging from mildly imbalanced to highly imbalanced and characterized by varying number of disjuncts) in terms of three different performance indices (including the proposed GSDI).