 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARREST: Adversarial Resilient Regulation Enhancing Safety and Truth in Large Language Models
Jan 07, 2026Human cognition, driven by complex neurochemical processes, oscillates between imagination and reality and learns to self-correct whenever such subtle drifts lead to hallucinations or unsafe associations. In recent years, LLMs have demonstrated remarkable performance in a wide range of tasks. However, they still lack human cognition to balance factuality and safety. Bearing the resemblance, we argue that both factual and safety failures in LLMs arise from a representational misalignment in their latent activation space, rather than addressing those as entirely separate alignment issues. We hypothesize that an external network, trained to understand the fluctuations, can selectively intervene in the model to regulate falsehood into truthfulness and unsafe output into safe output without fine-tuning the model parameters themselves. Reflecting the hypothesis, we propose ARREST (Adversarial Resilient Regulation Enhancing Safety and Truth), a unified framework that identifies and corrects drifted features, engaging both soft and hard refusals in addition to factual corrections. Our empirical results show that ARREST not only regulates misalignment but is also more versatile compared to the RLHF-aligned models in generating soft refusals due to adversarial training. We make our codebase available at https://github.com/sharanya-dasgupta001/ARREST.
HalluShift++: Bridging Language and Vision through Internal Representation Shifts for Hierarchical Hallucinations in MLLMs
Dec 08, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in vision-language understanding tasks. While these models often produce linguistically coherent output, they often suffer from hallucinations, generating descriptions that are factually inconsistent with the visual content, potentially leading to adverse consequences. Therefore, the assessment of hallucinations in MLLM has become increasingly crucial in the model development process. Contemporary methodologies predominantly depend on external LLM evaluators, which are themselves susceptible to hallucinations and may present challenges in terms of domain adaptation. In this study, we propose the hypothesis that hallucination manifests as measurable irregularities within the internal layer dynamics of MLLMs, not merely due to distributional shifts but also in the context of layer-wise analysis of specific assumptions. By incorporating such modifications, \textsc{\textsc{HalluShift++}} broadens the efficacy of hallucination detection from text-based large language models (LLMs) to encompass multimodal scenarios. Our codebase is available at https://github.com/C0mRD/HalluShift_Plus.
Revealing the Ancient Beauty: Digital Reconstruction of Temple Tiles using Computer Vision
Jul 16, 2025



Modern digitised approaches have dramatically changed the preservation and restoration of cultural treasures, integrating computer scientists into multidisciplinary projects with ease. Machine learning, deep learning, and computer vision techniques have revolutionised developing sectors like 3D reconstruction, picture inpainting,IoT-based methods, genetic algorithms, and image processing with the integration of computer scientists into multidisciplinary initiatives. We suggest three cutting-edge techniques in recognition of the special qualities of Indian monuments, which are famous for their architectural skill and aesthetic appeal. First is the Fractal Convolution methodology, a segmentation method based on image processing that successfully reveals subtle architectural patterns within these irreplaceable cultural buildings. The second is a revolutionary Self-Sensitive Tile Filling (SSTF) method created especially for West Bengal's mesmerising Bankura Terracotta Temples with a brand-new data augmentation method called MosaicSlice on the third. Furthermore, we delve deeper into the Super Resolution strategy to upscale the images without losing significant amount of quality. Our methods allow for the development of seamless region-filling and highly detailed tiles while maintaining authenticity using a novel data augmentation strategy within affordable costs introducing automation. By providing effective solutions that preserve the delicate balance between tradition and innovation, this study improves the subject and eventually ensures unrivalled efficiency and aesthetic excellence in cultural heritage protection. The suggested approaches advance the field into an era of unmatched efficiency and aesthetic quality while carefully upholding the delicate equilibrium between tradition and innovation.
HalluShift: Measuring Distribution Shifts towards Hallucination Detection in LLMs
Apr 13, 2025



Large Language Models (LLMs) have recently garnered widespread attention due to their adeptness at generating innovative responses to the given prompts across a multitude of domains. However, LLMs often suffer from the inherent limitation of hallucinations and generate incorrect information while maintaining well-structured and coherent responses. In this work, we hypothesize that hallucinations stem from the internal dynamics of LLMs. Our observations indicate that, during passage generation, LLMs tend to deviate from factual accuracy in subtle parts of responses, eventually shifting toward misinformation. This phenomenon bears a resemblance to human cognition, where individuals may hallucinate while maintaining logical coherence, embedding uncertainty within minor segments of their speech. To investigate this further, we introduce an innovative approach, HalluShift, designed to analyze the distribution shifts in the internal state space and token probabilities of the LLM-generated responses. Our method attains superior performance compared to existing baselines across various benchmark datasets. Our codebase is available at https://github.com/sharanya-dasgupta001/hallushift.
On Robust Cross Domain Alignment
Dec 20, 2024



The Gromov-Wasserstein (GW) distance is an effective measure of alignment between distributions supported on distinct ambient spaces. Calculating essentially the mutual departure from isometry, it has found vast usage in domain translation and network analysis. It has long been shown to be vulnerable to contamination in the underlying measures. All efforts to introduce robustness in GW have been inspired by similar techniques in optimal transport (OT), which predominantly advocate partial mass transport or unbalancing. In contrast, the cross-domain alignment problem being fundamentally different from OT, demands specific solutions to tackle diverse applications and contamination regimes. Deriving from robust statistics, we discuss three contextually novel techniques to robustify GW and its variants. For each method, we explore metric properties and robustness guarantees along with their co-dependencies and individual relations with the GW distance. For a comprehensive view, we empirically validate their superior resilience to contamination under real machine learning tasks against state-of-the-art methods.
Fortifying Fully Convolutional Generative Adversarial Networks for Image Super-Resolution Using Divergence Measures
Apr 09, 2024Super-Resolution (SR) is a time-hallowed image processing problem that aims to improve the quality of a Low-Resolution (LR) sample up to the standard of its High-Resolution (HR) counterpart. We aim to address this by introducing Super-Resolution Generator (SuRGe), a fully-convolutional Generative Adversarial Network (GAN)-based architecture for SR. We show that distinct convolutional features obtained at increasing depths of a GAN generator can be optimally combined by a set of learnable convex weights to improve the quality of generated SR samples. In the process, we employ the Jensen-Shannon and the Gromov-Wasserstein losses respectively between the SR-HR and LR-SR pairs of distributions to further aid the generator of SuRGe to better exploit the available information in an attempt to improve SR. Moreover, we train the discriminator of SuRGe with the Wasserstein loss with gradient penalty, to primarily prevent mode collapse. The proposed SuRGe, as an end-to-end GAN workflow tailor-made for super-resolution, offers improved performance while maintaining low inference time. The efficacy of SuRGe is substantiated by its superior performance compared to 18 state-of-the-art contenders on 10 benchmark datasets.
Concurrent Density Estimation with Wasserstein Autoencoders: Some Statistical Insights
Dec 11, 2023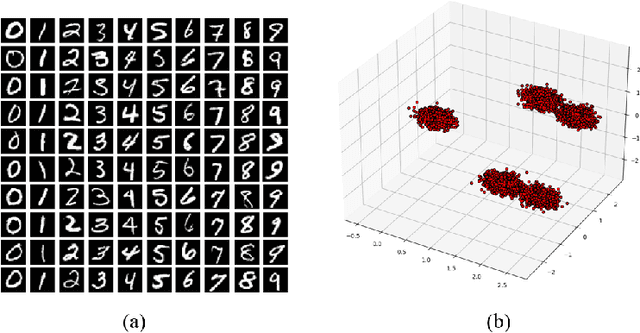
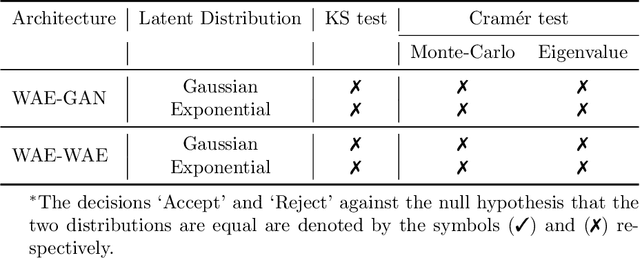
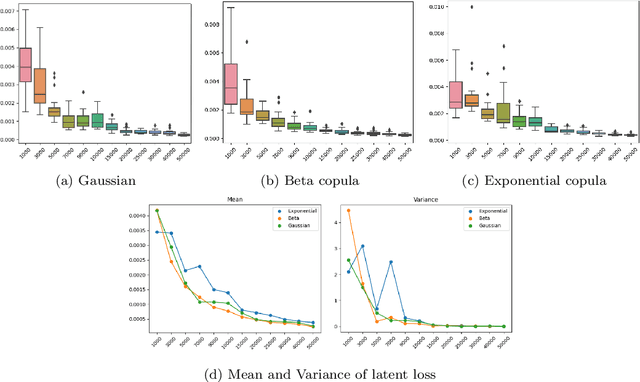
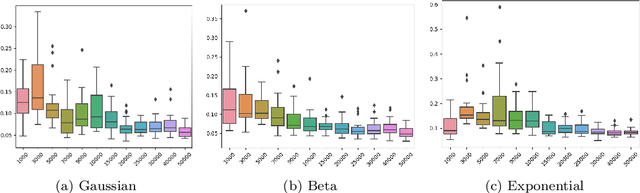
Variational Autoencoders (VAEs) have been a pioneering force in the realm of deep generative models. Amongst its legions of progenies, Wasserstein Autoencoders (WAEs) stand out in particular due to the dual offering of heightened generative quality and a strong theoretical backbone. WAEs consist of an encoding and a decoding network forming a bottleneck with the prime objective of generating new samples resembling the ones it was catered to. In the process, they aim to achieve a target latent representation of the encoded data. Our work is an attempt to offer a theoretical understanding of the machinery behind WAEs. From a statistical viewpoint, we pose the problem as concurrent density estimation tasks based on neural network-induced transformations. This allows us to establish deterministic upper bounds on the realized errors WAEs commit. We also analyze the propagation of these stochastic errors in the presence of adversaries. As a result, both the large sample properties of the reconstructed distribution and the resilience of WAE models are explored.
Handwritten Digit Recognition Using Improved Bounding Box Recognition Technique
Nov 10, 2021
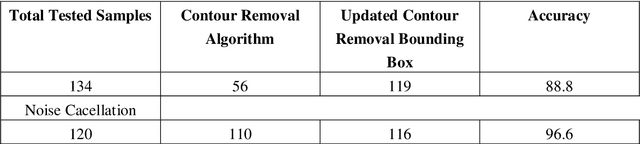
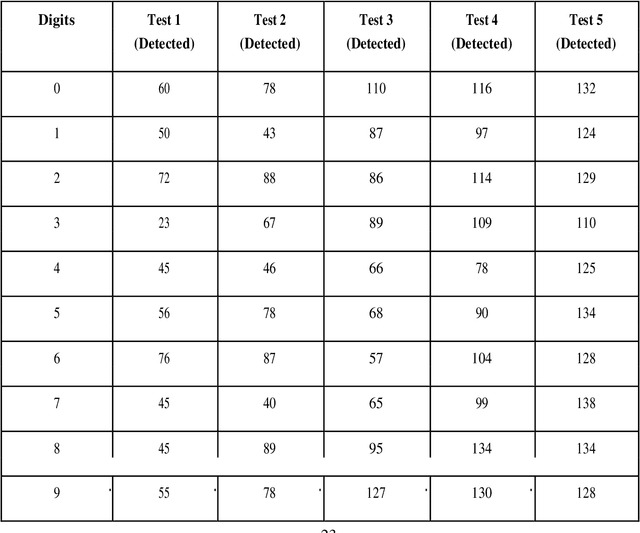
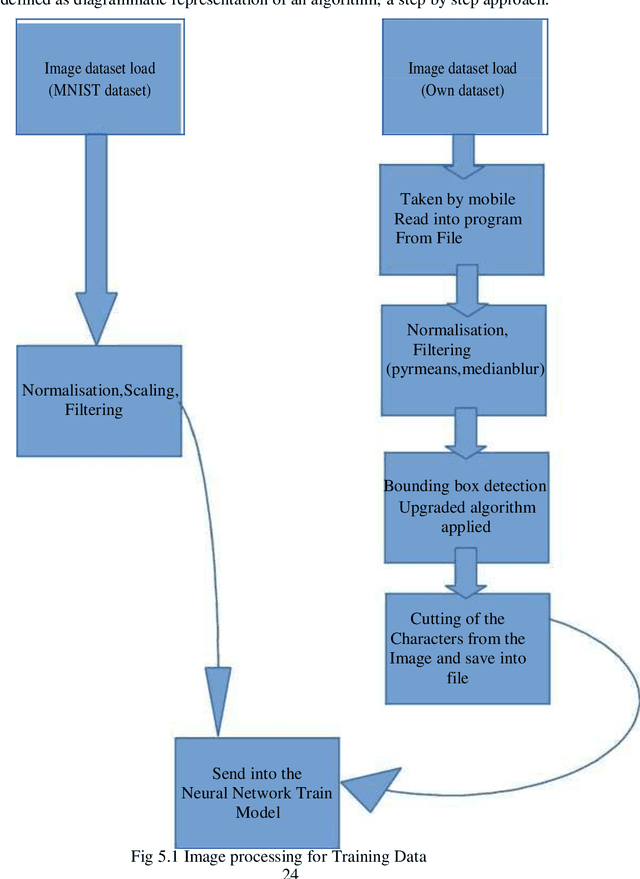
The project comes with the technique of OCR (Optical Character Recognition) which includes various research sides of computer science. The project is to take a picture of a character and process it up to recognize the image of that character like a human brain recognize the various digits. The project contains the deep idea of the Image Processing techniques and the big research area of machine learning and the building block of the machine learning called Neural Network. There are two different parts of the project. Training part comes with the idea of to train a child by giving various sets of similar characters but not the totally same and to say them the output of this is this. Like this idea one has to train the newly built neural network with so many characters. This part contains some new algorithm which is self-created and upgraded as the project need. The testing part contains the testing of a new dataset .This part always comes after the part of the training .At first one has to teach the child how to recognize the character .Then one has to take the test whether he has given right answer or not. If not, one has to train him harder by giving new dataset and new entries. Just like that one has to test the algorithm also. There are many parts of statistical modeling and optimization techniques which come into the project requiring a lot of modeling concept of statistics like optimizer technique and filtering process, that how the mathematics and prediction behind that filtering or the algorithms comes after or which result one actually needs to and ultimately for the prediction of a predictive model creation. Machine learning algorithm is built by concepts of prediction and programming.
COVID-19 Face Mask Recognition with Advanced Face Cut Algorithm for Human Safety Measures
Oct 08, 2021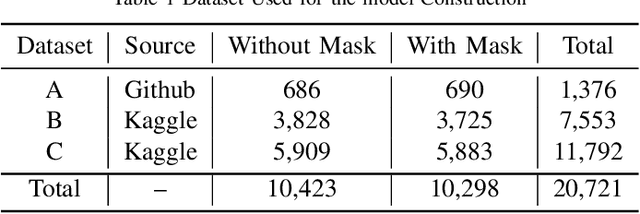


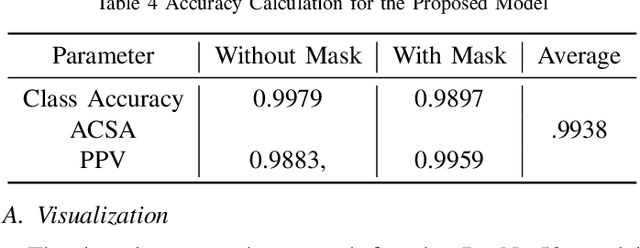
In the last year, the outbreak of COVID-19 has deployed computer vision and machine learning algorithms in various fields to enhance human life interactions. COVID-19 is a highly contaminated disease that affects mainly the respiratory organs of the human body. We must wear a mask in this situation as the virus can be contaminated through the air and a non-masked person can be affected. Our proposal deploys a computer vision and deep learning framework to recognize face masks from images or videos. We have implemented a Boundary dependent face cut recognition algorithm that can cut the face from the image using 27 landmarks and then the preprocessed image can further be sent to the deep learning ResNet50 model. The experimental result shows a significant advancement of 3.4 percent compared to the YOLOV3 mask recognition architecture in just 10 epochs.