 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Hallucination in Large Vision-Language Models based on Context-Aware Object Similarities
Jan 25, 2025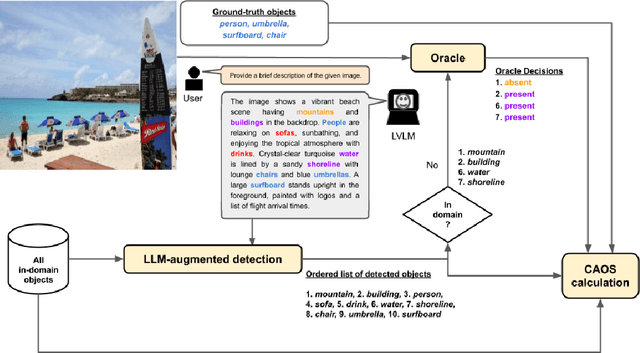
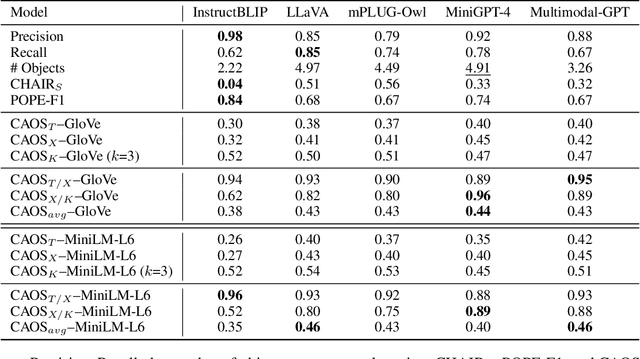
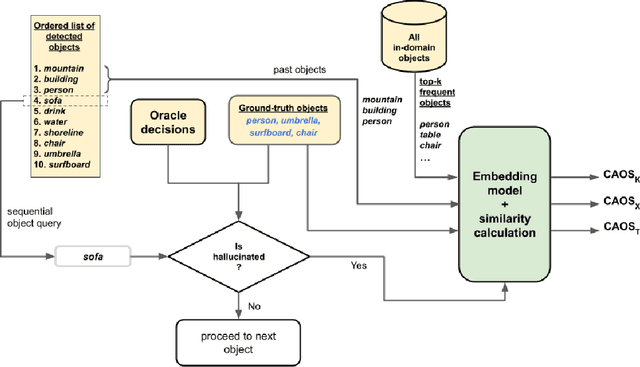
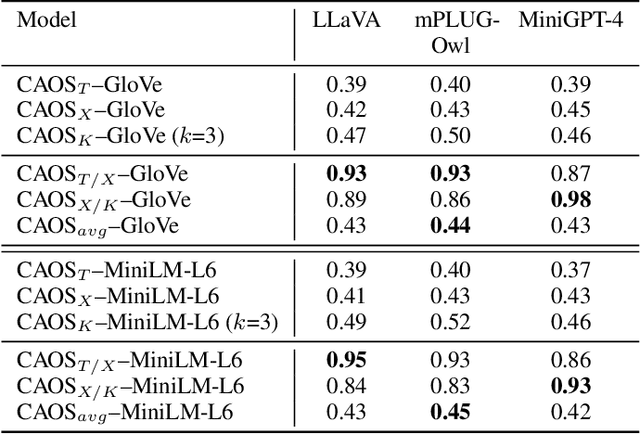
Despite their impressive performance on multi-modal tasks, large vision-language models (LVLMs) tend to suffer from hallucinations. An important type is object hallucination, where LVLMs generate objects that are inconsistent with the images shown to the model. Existing works typically attempt to quantify object hallucinations by detecting and measuring the fraction of hallucinated objects in generated captions. Additionally, more recent work also measures object hallucinations by directly querying the LVLM with binary questions about the presence of likely hallucinated objects based on object statistics like top-k frequent objects and top-k co-occurring objects. In this paper, we present Context-Aware Object Similarities (CAOS), a novel approach for evaluating object hallucination in LVLMs using object statistics as well as the generated captions. CAOS uniquely integrates object statistics with semantic relationships between objects in captions and ground-truth data. Moreover, existing approaches usually only detect and measure hallucinations belonging to a predetermined set of in-domain objects (typically the set of all ground-truth objects for the training dataset) and ignore generated objects that are not part of this set, leading to under-evaluation. To address this, we further employ language model--based object recognition to detect potentially out-of-domain hallucinated objects and use an ensemble of LVLMs for verifying the presence of such objects in the query image. CAOS also examines the sequential dynamics of object generation, shedding light on how the order of object appearance influences hallucinations, and employs word embedding models to analyze the semantic reasons behind hallucinations. CAOS aims to offer a nuanced understanding of the hallucination tendencies of LVLMs by providing a systematic framework to identify and interpret object hallucinations.
Identifying acute illness phenotypes via deep temporal interpolation and clustering network on physiologic signatures
Jul 27, 2023Initial hours of hospital admission impact clinical trajectory, but early clinical decisions often suffer due to data paucity. With clustering analysis for vital signs within six hours of admission, patient phenotypes with distinct pathophysiological signatures and outcomes may support early clinical decisions. We created a single-center, longitudinal EHR dataset for 75,762 adults admitted to a tertiary care center for 6+ hours. We proposed a deep temporal interpolation and clustering network to extract latent representations from sparse, irregularly sampled vital sign data and derived distinct patient phenotypes in a training cohort (n=41,502). Model and hyper-parameters were chosen based on a validation cohort (n=17,415). Test cohort (n=16,845) was used to analyze reproducibility and correlation with biomarkers. The training, validation, and testing cohorts had similar distributions of age (54-55 yrs), sex (55% female), race, comorbidities, and illness severity. Four clusters were identified. Phenotype A (18%) had most comorbid disease with higher rate of prolonged respiratory insufficiency, acute kidney injury, sepsis, and three-year mortality. Phenotypes B (33%) and C (31%) had diffuse patterns of mild organ dysfunction. Phenotype B had favorable short-term outcomes but second-highest three-year mortality. Phenotype C had favorable clinical outcomes. Phenotype D (17%) had early/persistent hypotension, high rate of early surgery, and substantial biomarker rate of inflammation but second-lowest three-year mortality. After comparing phenotypes' SOFA scores, clustering results did not simply repeat other acuity assessments. In a heterogeneous cohort, four phenotypes with distinct categories of disease and outcomes were identified by a deep temporal interpolation and clustering network. This tool may impact triage decisions and clinical decision-support under time constraints.
Interval Bound Propagation$\unicode{x2013}$aided Few$\unicode{x002d}$shot Learning
Apr 08, 2022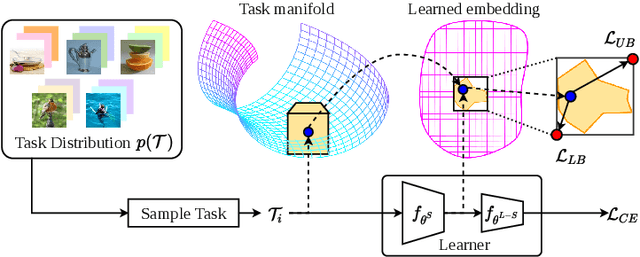
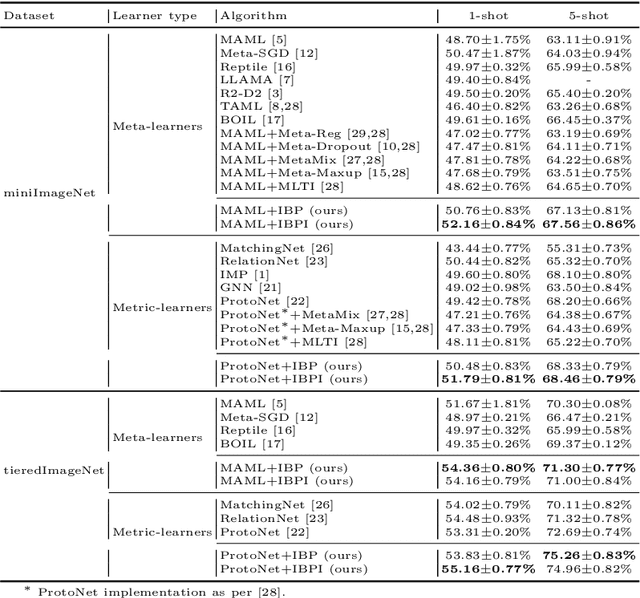
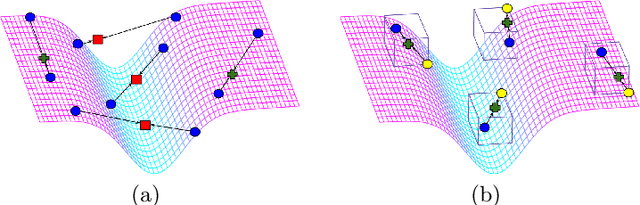
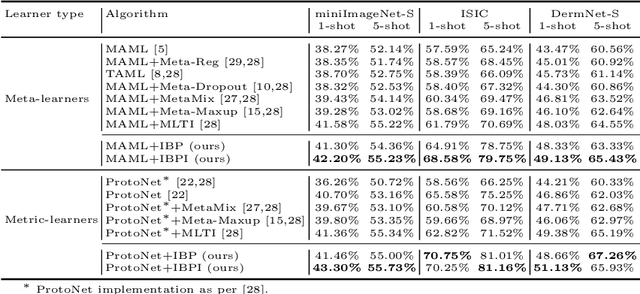
Few-shot learning aims to transfer the knowledge acquired from training on a diverse set of tasks, from a given task distribution, to generalize to unseen tasks, from the same distribution, with a limited amount of labeled data. The underlying requirement for effective few-shot generalization is to learn a good representation of the task manifold. One way to encourage this is to preserve local neighborhoods in the feature space learned by the few-shot learner. To this end, we introduce the notion of interval bounds from the provably robust training literature to few-shot learning. The interval bounds are used to characterize neighborhoods around the training tasks. These neighborhoods can then be preserved by minimizing the distance between a task and its respective bounds. We further introduce a novel strategy to artificially form new tasks for training by interpolating between the available tasks and their respective interval bounds, to aid in cases with a scarcity of tasks. We apply our framework to both model-agnostic meta-learning as well as prototype-based metric-learning paradigms. The efficacy of our proposed approach is evident from the improved performance on several datasets from diverse domains in comparison to a sizable number of recent competitors.
Counterfactual Representation Learning with Balancing Weights
Oct 23, 2020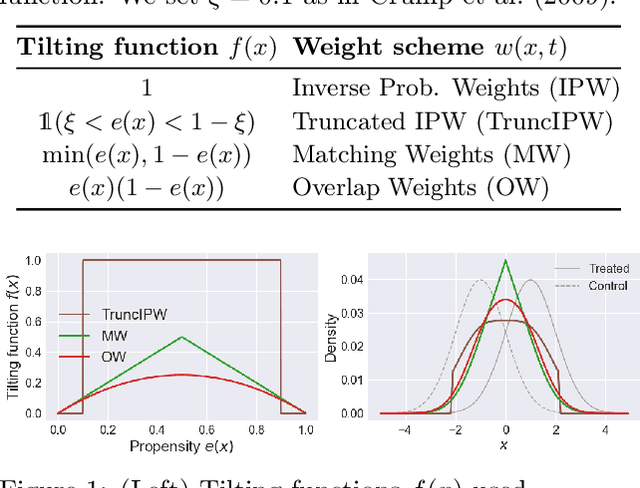
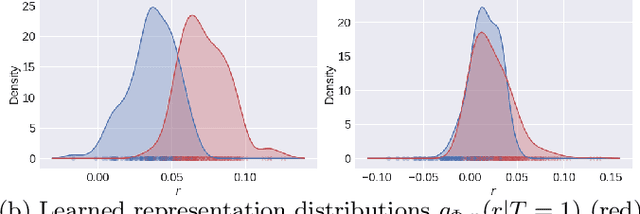
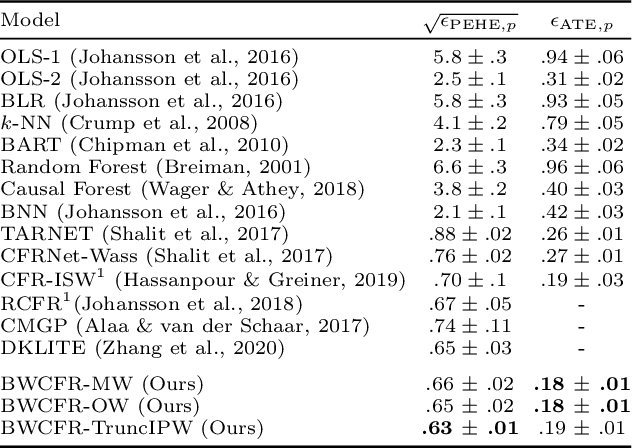
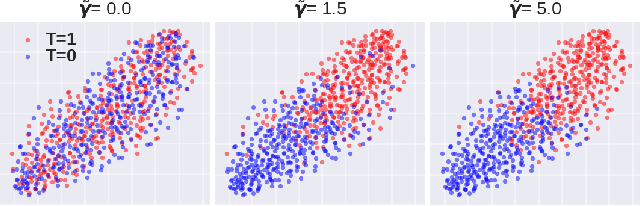
A key to causal inference with observational data is achieving balance in predictive features associated with each treatment type. Recent literature has explored representation learning to achieve this goal. In this work, we discuss the pitfalls of these strategies - such as a steep trade-off between achieving balance and predictive power - and present a remedy via the integration of balancing weights in causal learning. Specifically, we theoretically link balance to the quality of propensity estimation, emphasize the importance of identifying a proper target population, and elaborate on the complementary roles of feature balancing and weight adjustments. Using these concepts, we then develop an algorithm for flexible, scalable and accurate estimation of causal effects. Finally, we show how the learned weighted representations may serve to facilitate alternative causal learning procedures with appealing statistical features. We conduct an extensive set of experiments on both synthetic examples and standard benchmarks, and report encouraging results relative to state-of-the-art baselines.
Double Robust Representation Learning for Counterfactual Prediction
Oct 16, 2020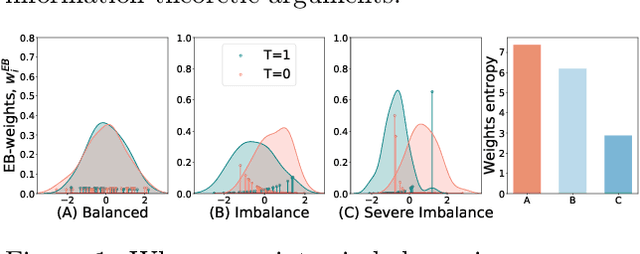
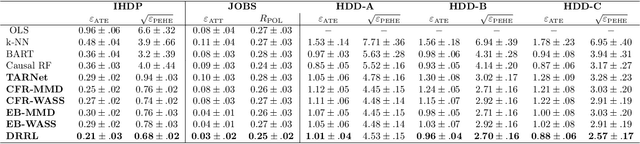
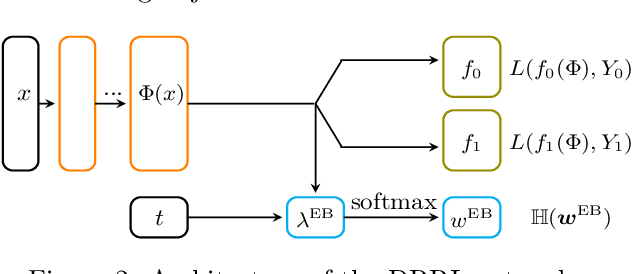

Causal inference, or counterfactual prediction, is central to decision making in healthcare, policy and social sciences. To de-bias causal estimators with high-dimensional data in observational studies, recent advances suggest the importance of combining machine learning models for both the propensity score and the outcome function. We propose a novel scalable method to learn double-robust representations for counterfactual predictions, leading to consistent causal estimation if the model for either the propensity score or the outcome, but not necessarily both, is correctly specified. Specifically, we use the entropy balancing method to learn the weights that minimize the Jensen-Shannon divergence of the representation between the treated and control groups, based on which we make robust and efficient counterfactual predictions for both individual and average treatment effects. We provide theoretical justifications for the proposed method. The algorithm shows competitive performance with the state-of-the-art on real world and synthetic data.
RetiNerveNet: Using Recursive Deep Learning to Estimate Pointwise 24-2 Visual Field Data based on Retinal Structure
Oct 15, 2020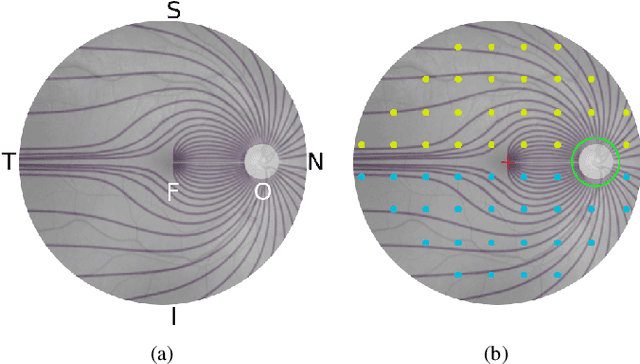
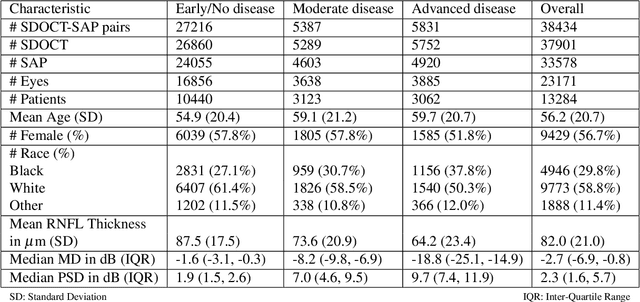
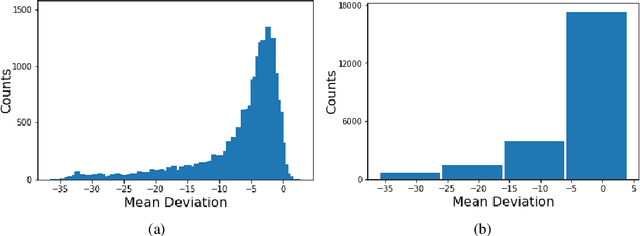
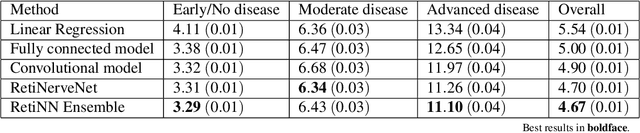
Glaucoma is the leading cause of irreversible blindness in the world, affecting over 70 million people. The cumbersome Standard Automated Perimetry (SAP) test is most frequently used to detect visual loss due to glaucoma. Due to the SAP test's innate difficulty and its high test-retest variability, we propose the RetiNerveNet, a deep convolutional recursive neural network for obtaining estimates of the SAP visual field. RetiNerveNet uses information from the more objective Spectral-Domain Optical Coherence Tomography (SDOCT). RetiNerveNet attempts to trace-back the arcuate convergence of the retinal nerve fibers, starting from the Retinal Nerve Fiber Layer (RNFL) thickness around the optic disc, to estimate individual age-corrected 24-2 SAP values. Recursive passes through the proposed network sequentially yield estimates of the visual locations progressively farther from the optic disc. The proposed network is able to obtain more accurate estimates of the individual visual field values, compared to a number of baselines, implying its utility as a proxy for SAP. We further augment RetiNerveNet to additionally predict the SAP Mean Deviation values and also create an ensemble of RetiNerveNets that further improves the performance, by increasingly weighting-up underrepresented parts of the training data.
Appropriateness of Performance Indices for Imbalanced Data Classification: An Analysis
Aug 26, 2020
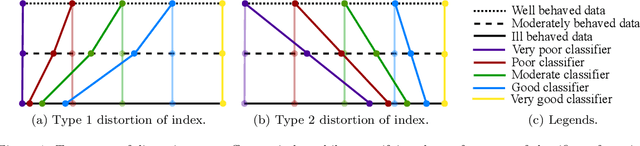
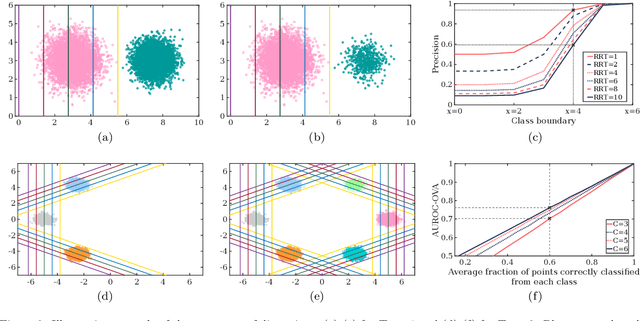
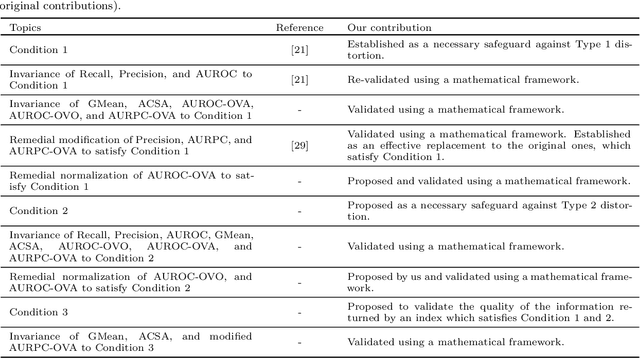
Indices quantifying the performance of classifiers under class-imbalance, often suffer from distortions depending on the constitution of the test set or the class-specific classification accuracy, creating difficulties in assessing the merit of the classifier. We identify two fundamental conditions that a performance index must satisfy to be respectively resilient to altering number of testing instances from each class and the number of classes in the test set. In light of these conditions, under the effect of class imbalance, we theoretically analyze four indices commonly used for evaluating binary classifiers and five popular indices for multi-class classifiers. For indices violating any of the conditions, we also suggest remedial modification and normalization. We further investigate the capability of the indices to retain information about the classification performance over all the classes, even when the classifier exhibits extreme performance on some classes. Simulation studies are performed on high dimensional deep representations of subset of the ImageNet dataset using four state-of-the-art classifiers tailored for handling class imbalance. Finally, based on our theoretical findings and empirical evidence, we recommend the appropriate indices that should be used to evaluate the performance of classifiers in presence of class-imbalance.
* Published in Pattern Recognition (Elsevier)
One Sparse Perturbation to Fool them All, almost Always!
Apr 30, 2020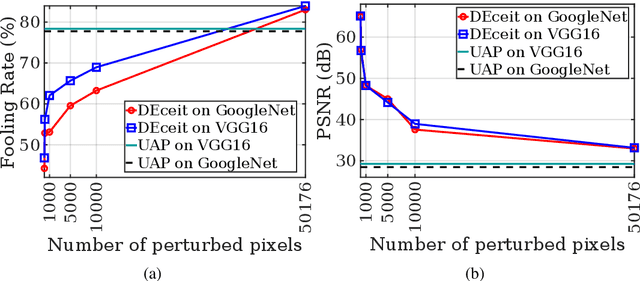
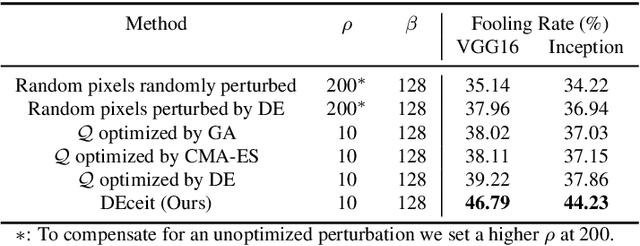
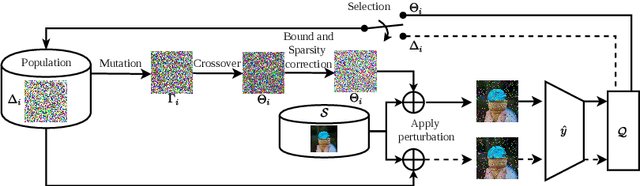
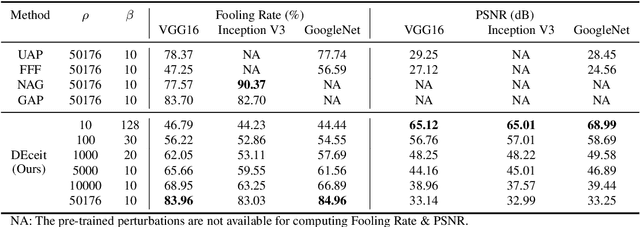
Constructing adversarial perturbations for deep neural networks is an important direction of research. Crafting image-dependent adversarial perturbations using white-box feedback has hitherto been the norm for such adversarial attacks. However, black-box attacks are much more practical for real-world applications. Universal perturbations applicable across multiple images are gaining popularity due to their innate generalizability. There have also been efforts to restrict the perturbations to a few pixels in the image. This helps to retain visual similarity with the original images making such attacks hard to detect. This paper marks an important step which combines all these directions of research. We propose the DEceit algorithm for constructing effective universal pixel-restricted perturbations using only black-box feedback from the target network. We conduct empirical investigations using the ImageNet validation set on the state-of-the-art deep neural classifiers by varying the number of pixels to be perturbed from a meagre 10 pixels to as high as all pixels in the image. We find that perturbing only about 10% of the pixels in an image using DEceit achieves a commendable and highly transferable Fooling Rate while retaining the visual quality. We further demonstrate that DEceit can be successfully applied to image dependent attacks as well. In both sets of experiments, we outperformed several state-of-the-art methods.
Application of Deep Interpolation Network for Clustering of Physiologic Time Series
Apr 27, 2020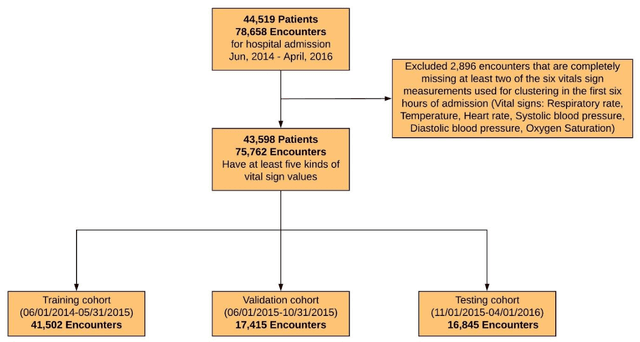
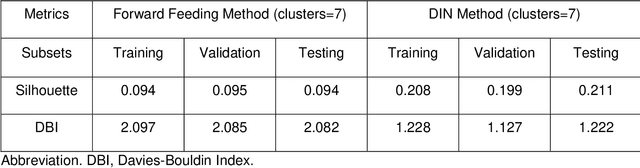
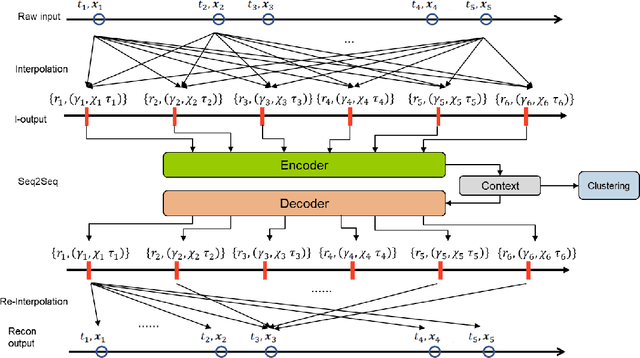

Background: During the early stages of hospital admission, clinicians must use limited information to make diagnostic and treatment decisions as patient acuity evolves. However, it is common that the time series vital sign information from patients to be both sparse and irregularly collected, which poses a significant challenge for machine / deep learning techniques to analyze and facilitate the clinicians to improve the human health outcome. To deal with this problem, We propose a novel deep interpolation network to extract latent representations from sparse and irregularly sampled time-series vital signs measured within six hours of hospital admission. Methods: We created a single-center longitudinal dataset of electronic health record data for all (n=75,762) adult patient admissions to a tertiary care center lasting six hours or longer, using 55% of the dataset for training, 23% for validation, and 22% for testing. All raw time series within six hours of hospital admission were extracted for six vital signs (systolic blood pressure, diastolic blood pressure, heart rate, temperature, blood oxygen saturation, and respiratory rate). A deep interpolation network is proposed to learn from such irregular and sparse multivariate time series data to extract the fixed low-dimensional latent patterns. We use k-means clustering algorithm to clusters the patient admissions resulting into 7 clusters. Findings: Training, validation, and testing cohorts had similar age (55-57 years), sex (55% female), and admission vital signs. Seven distinct clusters were identified. M Interpretation: In a heterogeneous cohort of hospitalized patients, a deep interpolation network extracted representations from vital sign data measured within six hours of hospital admission. This approach may have important implications for clinical decision-support under time constraints and uncertainty.
Interpretable Multi-Task Deep Neural Networks for Dynamic Predictions of Postoperative Complications
Apr 27, 2020
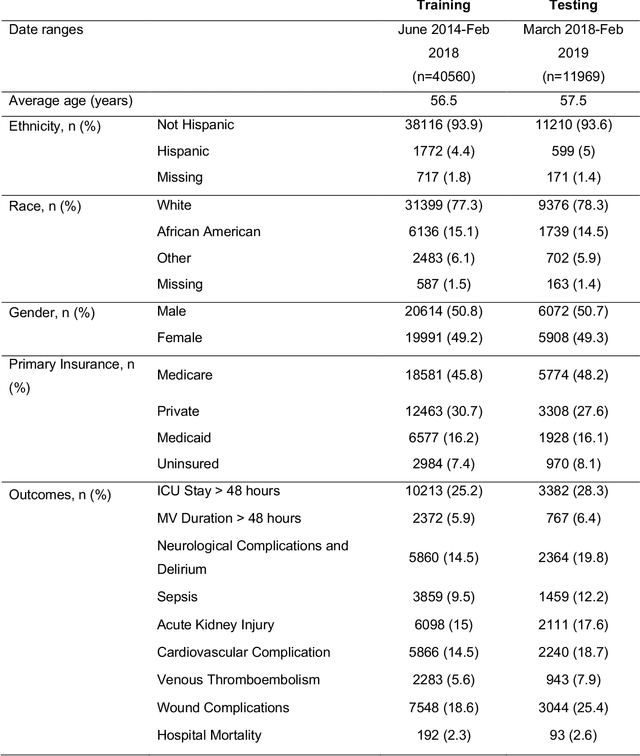
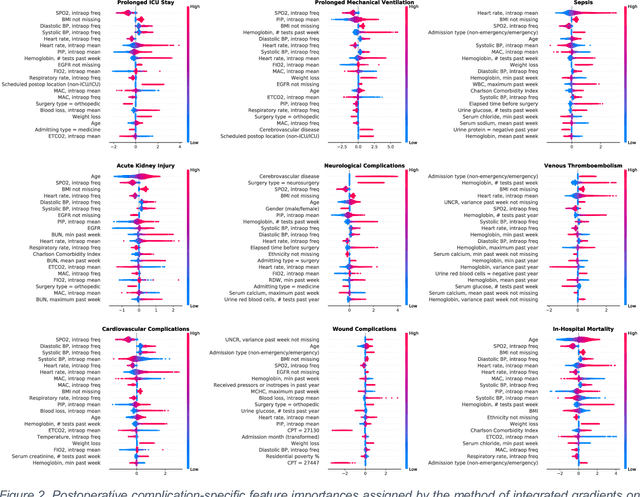
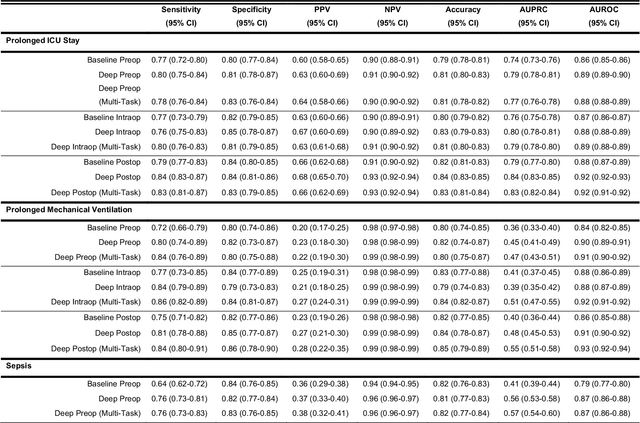
Accurate prediction of postoperative complications can inform shared decisions between patients and surgeons regarding the appropriateness of surgery, preoperative risk-reduction strategies, and postoperative resource use. Traditional predictive analytic tools are hindered by suboptimal performance and usability. We hypothesized that novel deep learning techniques would outperform logistic regression models in predicting postoperative complications. In a single-center longitudinal cohort of 43,943 adult patients undergoing 52,529 major inpatient surgeries, deep learning yielded greater discrimination than logistic regression for all nine complications. Predictive performance was strongest when leveraging the full spectrum of preoperative and intraoperative physiologic time-series electronic health record data. A single multi-task deep learning model yielded greater performance than separate models trained on individual complications. Integrated gradients interpretability mechanisms demonstrated the substantial importance of missing data. Interpretable, multi-task deep neural networks made accurate, patient-level predictions that harbor the potential to augment surgical decision-making.