 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetiNerveNet: Using Recursive Deep Learning to Estimate Pointwise 24-2 Visual Field Data based on Retinal Structure
Oct 15, 2020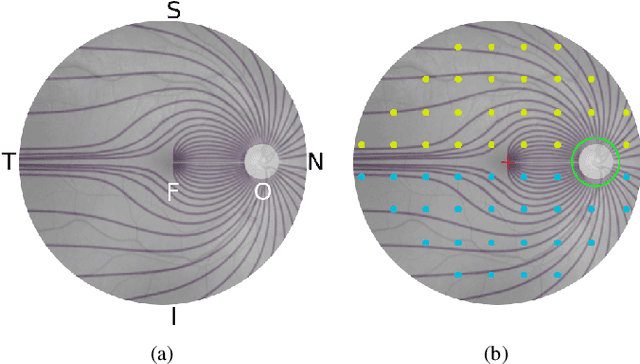
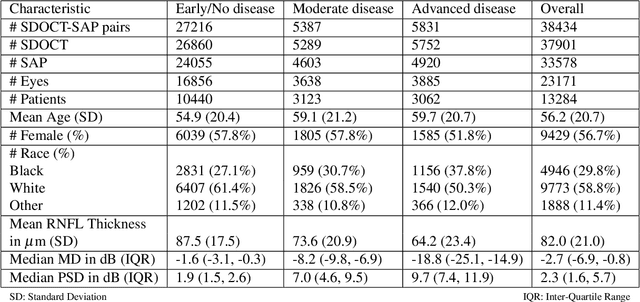
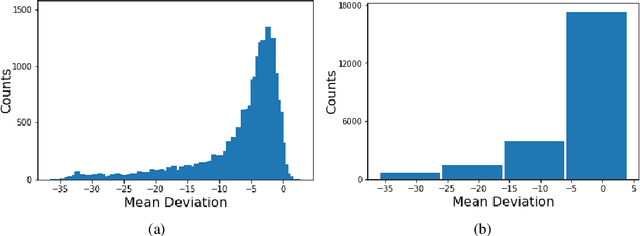
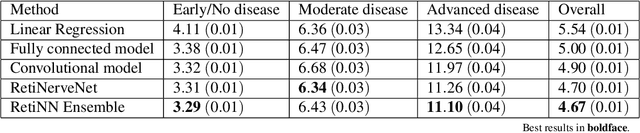
Glaucoma is the leading cause of irreversible blindness in the world, affecting over 70 million people. The cumbersome Standard Automated Perimetry (SAP) test is most frequently used to detect visual loss due to glaucoma. Due to the SAP test's innate difficulty and its high test-retest variability, we propose the RetiNerveNet, a deep convolutional recursive neural network for obtaining estimates of the SAP visual field. RetiNerveNet uses information from the more objective Spectral-Domain Optical Coherence Tomography (SDOCT). RetiNerveNet attempts to trace-back the arcuate convergence of the retinal nerve fibers, starting from the Retinal Nerve Fiber Layer (RNFL) thickness around the optic disc, to estimate individual age-corrected 24-2 SAP values. Recursive passes through the proposed network sequentially yield estimates of the visual locations progressively farther from the optic disc. The proposed network is able to obtain more accurate estimates of the individual visual field values, compared to a number of baselines, implying its utility as a proxy for SAP. We further augment RetiNerveNet to additionally predict the SAP Mean Deviation values and also create an ensemble of RetiNerveNets that further improves the performance, by increasingly weighting-up underrepresented parts of the training data.
Students Need More Attention: BERT-based AttentionModel for Small Data with Application to AutomaticPatient Message Triage
Jun 22, 2020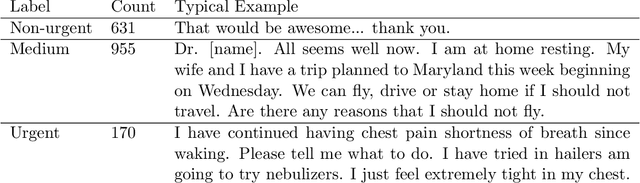
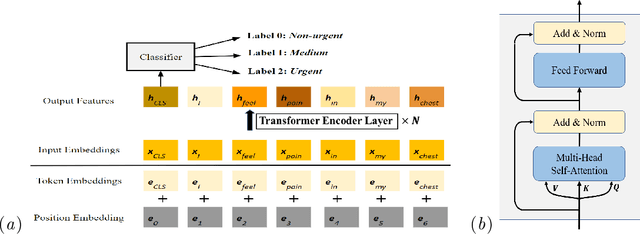

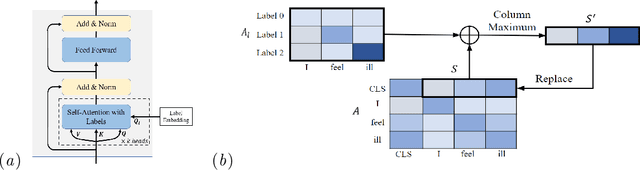
Small and imbalanced datasets commonly seen in healthcare represent a challenge when training classifiers based on deep learning models. So motivated, we propose a novel framework based on BioBERT (Bidirectional Encoder Representations from Transformers forBiomedical TextMining). Specifically, (i) we introduce Label Embeddings for Self-Attention in each layer of BERT, which we call LESA-BERT, and (ii) by distilling LESA-BERT to smaller variants, we aim to reduce overfitting and model size when working on small datasets. As an application, our framework is utilized to build a model for patient portal message triage that classifies the urgency of a message into three categories: non-urgent, medium and urgent. Experiments demonstrate that our approach can outperform several strong baseline classifiers by a significant margin of 4.3% in terms of macro F1 score. The code for this project is publicly available at \url{https://github.com/shijing001/text_classifiers}.
Machine-Learning-Based Multiple Abnormality Prediction with Large-Scale Chest Computed Tomography Volumes
Feb 17, 2020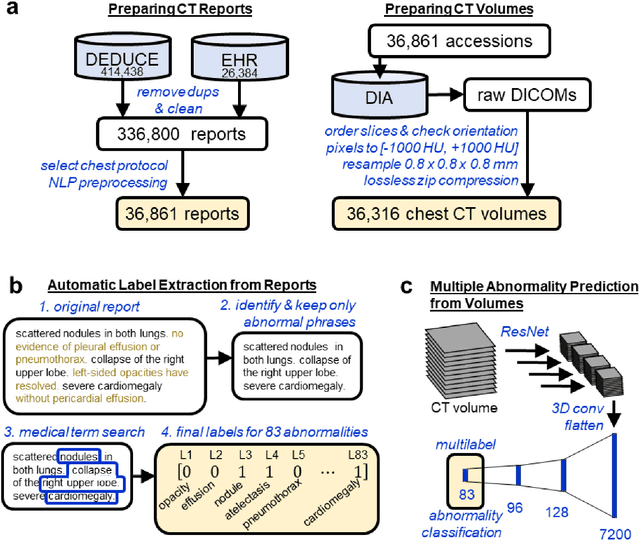

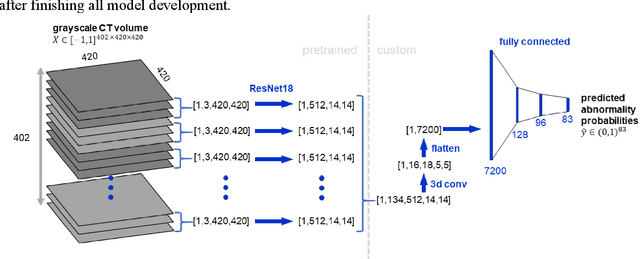
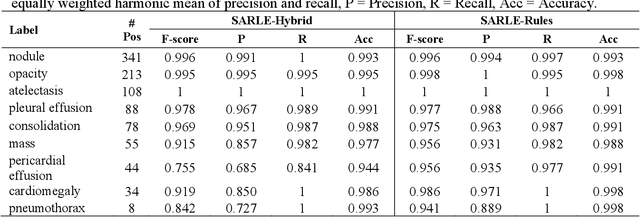
Machine learning models for radiology benefit from large-scale data sets with high quality labels for abnormalities. We curated and analyzed a chest computed tomography (CT) data set of 36,316 volumes from 19,993 unique patients. This is the largest multiply-annotated volumetric medical imaging data set reported. To annotate this data set, we developed a rule-based method for automatically extracting abnormality labels from free-text radiology reports with an average F-score of 0.976 (min 0.941, max 1.0). We also developed a model for multi-organ, multi-disease classification of chest CT volumes that uses a deep convolutional neural network (CNN). This model reached a classification performance of AUROC greater than 0.90 for 18 abnormalities, with an average AUROC of 0.773 for all 83 abnormalities, demonstrating the feasibility of learning from unfiltered whole volume CT data. We show that training on more labels improves performance significantly: for a subset of 9 labels - nodule, opacity, atelectasis, pleural effusion, consolidation, mass, pericardial effusion, cardiomegaly, and pneumothorax - the model's average AUROC increased by 10% when the number of training labels was increased from 9 to all 83. All code for volume preprocessing, automated label extraction, and the volume abnormality prediction model will be made publicly available. The 36,316 CT volumes and labels will also be made publicly available pending institutional approval.
A Deep-Learning Algorithm for Thyroid Malignancy Prediction From Whole Slide Cytopathology Images
Apr 26, 2019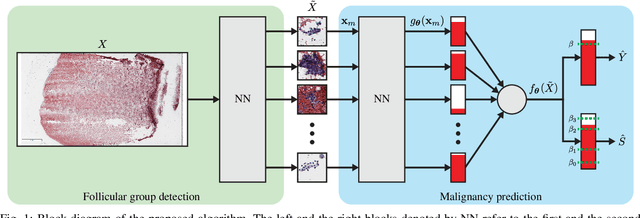
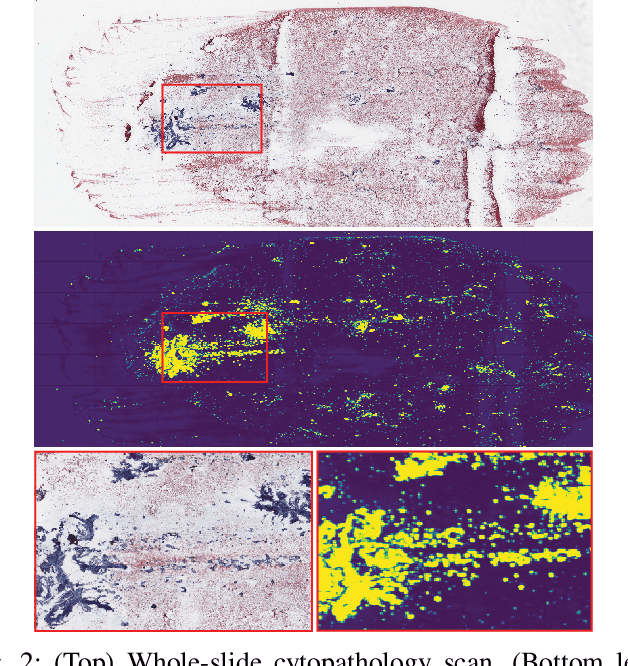
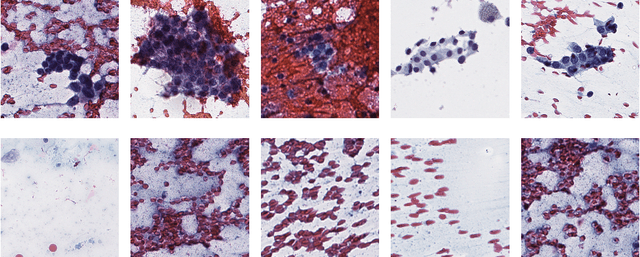
We consider thyroid-malignancy prediction from ultra-high-resolution whole-slide cytopathology images. We propose a deep-learning-based algorithm that is inspired by the way a cytopathologist diagnoses the slides. The algorithm identifies diagnostically relevant image regions and assigns them local malignancy scores, that in turn are incorporated into a global malignancy prediction. We discuss the relation of our deep-learning-based approach to multiple-instance learning (MIL) and describe how it deviates from classical MIL methods by the use of a supervised procedure to extract relevant regions from the whole-slide. The analysis of our algorithm further reveals a close relation to hypothesis testing, which, along with unique characteristics of thyroid cytopathology, allows us to devise an improved training strategy. We further propose an ordinal regression framework for the simultaneous prediction of thyroid malignancy and an ordered diagnostic score acting as a regularizer, which further improves the predictions of the network. Experimental results demonstrate that the proposed algorithm outperforms several competing methods, achieving performance comparable to human experts.
Thyroid Cancer Malignancy Prediction From Whole Slide Cytopathology Images
Mar 29, 2019



We consider preoperative prediction of thyroid cancer based on ultra-high-resolution whole-slide cytopathology images. Inspired by how human experts perform diagnosis, our approach first identifies and classifies diagnostic image regions containing informative thyroid cells, which only comprise a tiny fraction of the entire image. These local estimates are then aggregated into a single prediction of thyroid malignancy. Several unique characteristics of thyroid cytopathology guide our deep-learning-based approach. While our method is closely related to multiple-instance learning, it deviates from these methods by using a supervised procedure to extract diagnostically relevant regions. Moreover, we propose to simultaneously predict thyroid malignancy, as well as a diagnostic score assigned by a human expert, which further allows us to devise an improved training strategy. Experimental results show that the proposed algorithm achieves performance comparable to human experts, and demonstrate the potential of using the algorithm for screening and as an assistive tool for the improved diagnosis of indeterminate cases.
Kernel-based Sensor Fusion with Application to Audio-Visual Voice Activity Detection
Apr 11, 2016
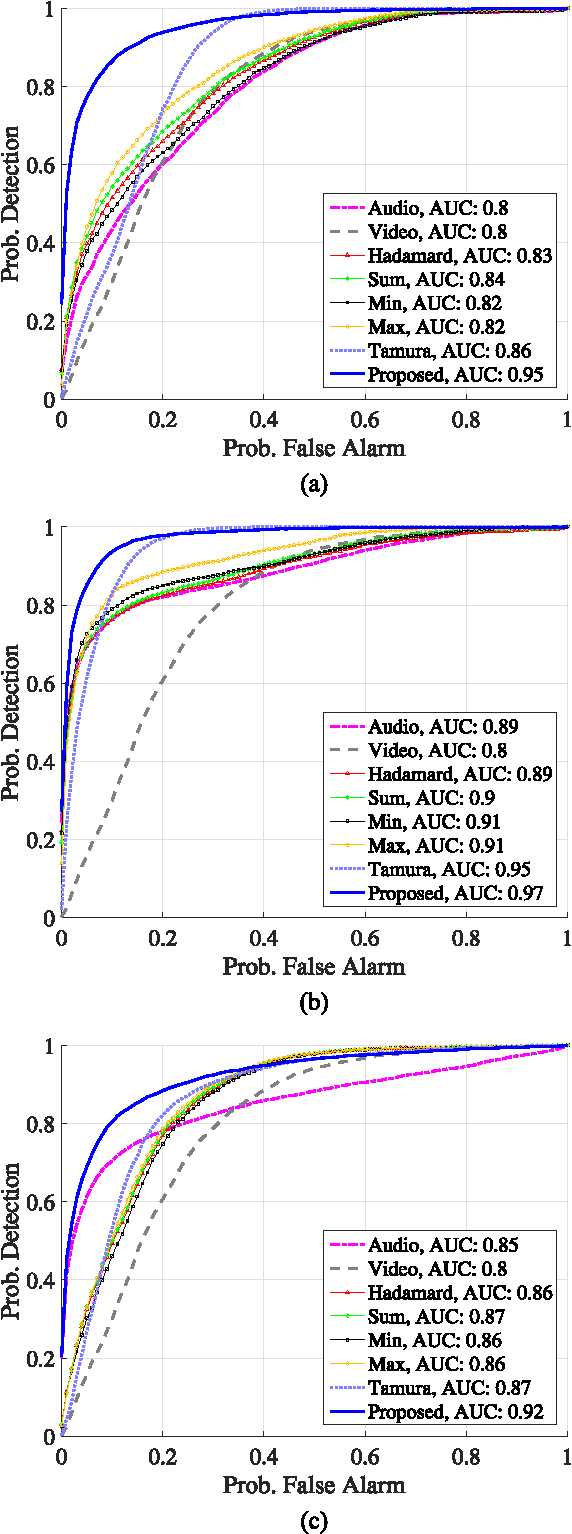
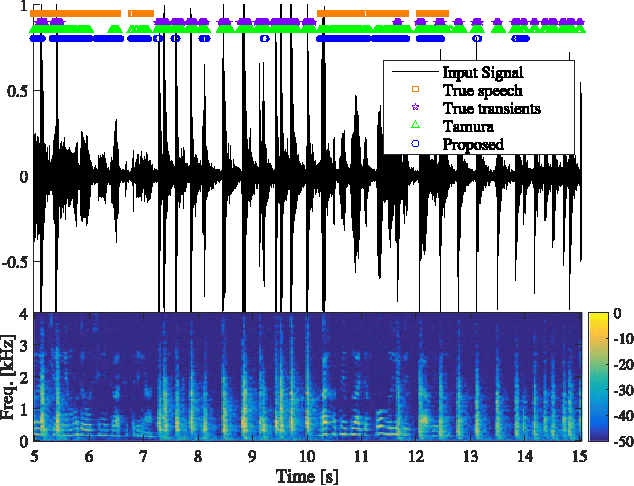
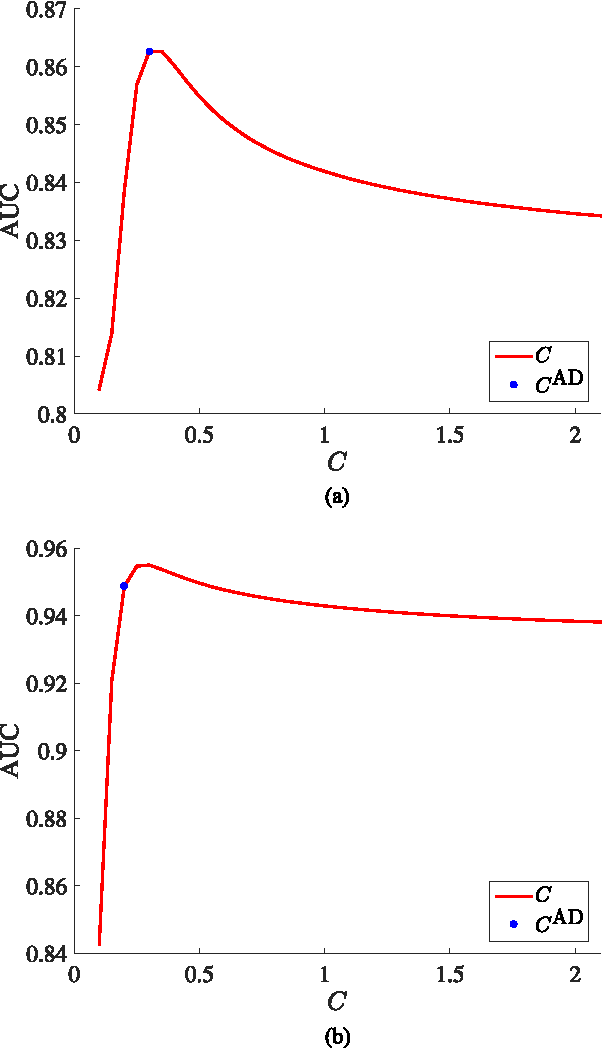
In this paper, we address the problem of multiple view data fusion in the presence of noise and interferences. Recent studies have approached this problem using kernel methods, by relying particularly on a product of kernels constructed separately for each view. From a graph theory point of view, we analyze this fusion approach in a discrete setting. More specifically, based on a statistical model for the connectivity between data points, we propose an algorithm for the selection of the kernel bandwidth, a parameter, which, as we show, has important implications on the robustness of this fusion approach to interferences. Then, we consider the fusion of audio-visual speech signals measured by a single microphone and by a video camera pointed to the face of the speaker. Specifically, we address the task of voice activity detection, i.e., the detection of speech and non-speech segments, in the presence of structured interferences such as keyboard taps and office noise. We propose an algorithm for voice activity detection based on the audio-visual signal. Simulation results show that the proposed algorithm outperforms competing fusion and voice activity detection approaches. In addition, we demonstrate that a proper selection of the kernel bandwidth indeed leads to improved performance.