 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Learning-Based Multiple Abnormality Prediction with Large-Scale Chest Computed Tomography Volumes
Paper and Code
Feb 17, 2020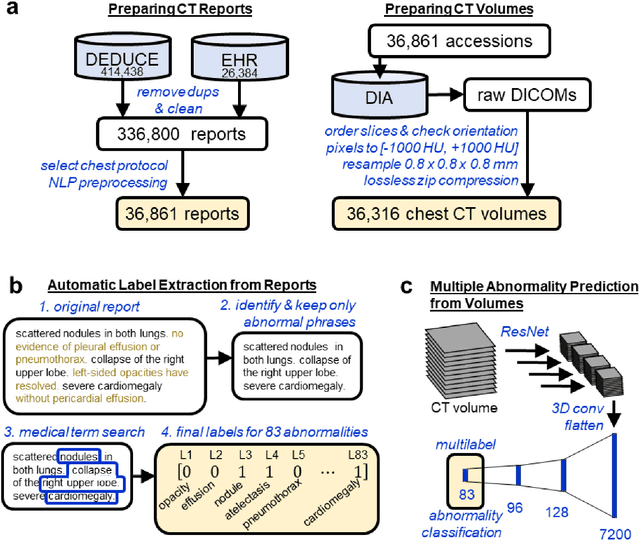

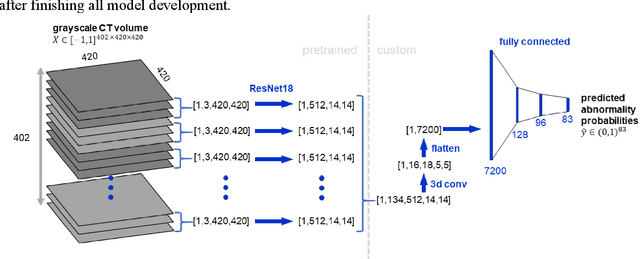
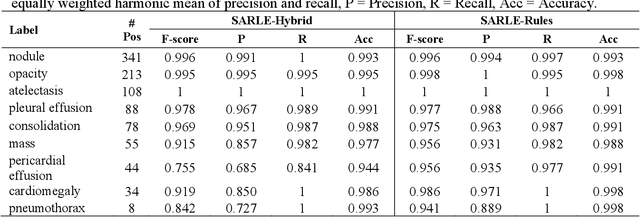
Machine learning models for radiology benefit from large-scale data sets with high quality labels for abnormalities. We curated and analyzed a chest computed tomography (CT) data set of 36,316 volumes from 19,993 unique patients. This is the largest multiply-annotated volumetric medical imaging data set reported. To annotate this data set, we developed a rule-based method for automatically extracting abnormality labels from free-text radiology reports with an average F-score of 0.976 (min 0.941, max 1.0). We also developed a model for multi-organ, multi-disease classification of chest CT volumes that uses a deep convolutional neural network (CNN). This model reached a classification performance of AUROC greater than 0.90 for 18 abnormalities, with an average AUROC of 0.773 for all 83 abnormalities, demonstrating the feasibility of learning from unfiltered whole volume CT data. We show that training on more labels improves performance significantly: for a subset of 9 labels - nodule, opacity, atelectasis, pleural effusion, consolidation, mass, pericardial effusion, cardiomegaly, and pneumothorax - the model's average AUROC increased by 10% when the number of training labels was increased from 9 to all 83. All code for volume preprocessing, automated label extraction, and the volume abnormality prediction model will be made publicly available. The 36,316 CT volumes and labels will also be made publicly available pending institutional approval.