 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudents Need More Attention: BERT-based AttentionModel for Small Data with Application to AutomaticPatient Message Triage
Paper and Code
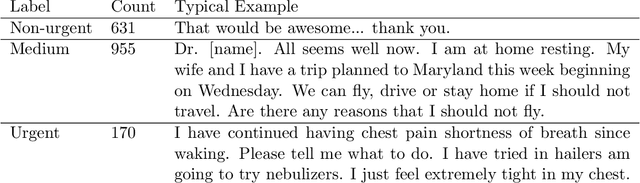
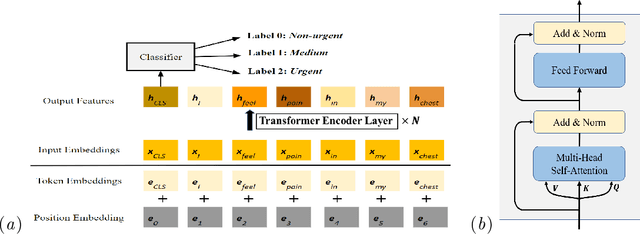

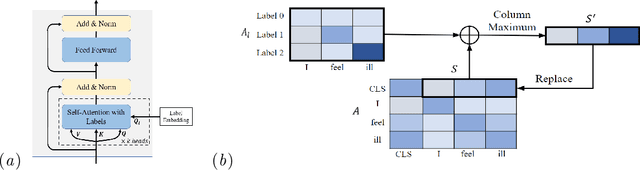
Small and imbalanced datasets commonly seen in healthcare represent a challenge when training classifiers based on deep learning models. So motivated, we propose a novel framework based on BioBERT (Bidirectional Encoder Representations from Transformers forBiomedical TextMining). Specifically, (i) we introduce Label Embeddings for Self-Attention in each layer of BERT, which we call LESA-BERT, and (ii) by distilling LESA-BERT to smaller variants, we aim to reduce overfitting and model size when working on small datasets. As an application, our framework is utilized to build a model for patient portal message triage that classifies the urgency of a message into three categories: non-urgent, medium and urgent. Experiments demonstrate that our approach can outperform several strong baseline classifiers by a significant margin of 4.3% in terms of macro F1 score. The code for this project is publicly available at \url{https://github.com/shijing001/text_classifiers}.