 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Diffusion Guided Refinement of 3D Scenes
Mar 19, 2025Reconstructing 3D scenes from a single image is a fundamentally ill-posed task due to the severely under-constrained nature of the problem. Consequently, when the scene is rendered from novel camera views, existing single image to 3D reconstruction methods render incoherent and blurry views. This problem is exacerbated when the unseen regions are far away from the input camera. In this work, we address these inherent limitations in existing single image-to-3D scene feedforward networks. To alleviate the poor performance due to insufficient information beyond the input image's view, we leverage a strong generative prior in the form of a pre-trained latent video diffusion model, for iterative refinement of a coarse scene represented by optimizable Gaussian parameters. To ensure that the style and texture of the generated images align with that of the input image, we incorporate on-the-fly Fourier-style transfer between the generated images and the input image. Additionally, we design a semantic uncertainty quantification module that calculates the per-pixel entropy and yields uncertainty maps used to guide the refinement process from the most confident pixels while discarding the remaining highly uncertain ones. We conduct extensive experiments on real-world scene datasets, including in-domain RealEstate-10K and out-of-domain KITTI-v2, showing that our approach can provide more realistic and high-fidelity novel view synthesis results compared to existing state-of-the-art methods.
Unbiased Scene Graph Generation in Videos
Apr 06, 2023The task of dynamic scene graph generation (SGG) from videos is complicated and challenging due to the inherent dynamics of a scene, temporal fluctuation of model predictions, and the long-tailed distribution of the visual relationships in addition to the already existing challenges in image-based SGG. Existing methods for dynamic SGG have primarily focused on capturing spatio-temporal context using complex architectures without addressing the challenges mentioned above, especially the long-tailed distribution of relationships. This often leads to the generation of biased scene graphs. To address these challenges, we introduce a new framework called TEMPURA: TEmporal consistency and Memory Prototype guided UnceRtainty Attenuation for unbiased dynamic SGG. TEMPURA employs object-level temporal consistencies via transformer-based sequence modeling, learns to synthesize unbiased relationship representations using memory-guided training, and attenuates the predictive uncertainty of visual relations using a Gaussian Mixture Model (GMM). Extensive experiments demonstrate that our method achieves significant (up to 10% in some cases) performance gain over existing methods highlighting its superiority in generating more unbiased scene graphs.
Adversarial Perturbations Against Real-Time Video Classification Systems
Jul 02, 2018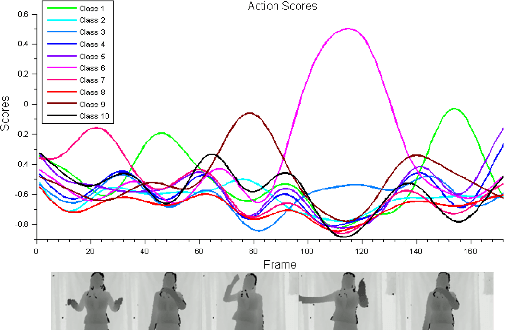

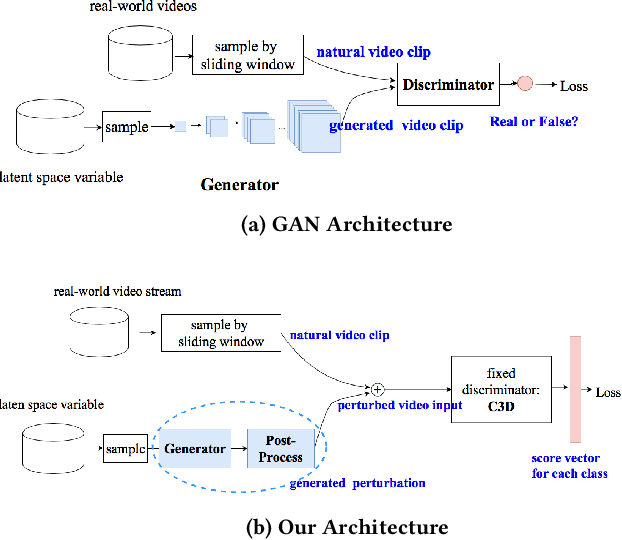
Recent research has demonstrated the brittleness of machine learning systems to adversarial perturbations. However, the studies have been mostly limited to perturbations on images and more generally, classification that does not deal with temporally varying inputs. In this paper we ask "Are adversarial perturbations possible in real-time video classification systems and if so, what properties must they satisfy?" Such systems find application in surveillance applications, smart vehicles, and smart elderly care and thus, misclassification could be particularly harmful (e.g., a mishap at an elderly care facility may be missed). We show that accounting for temporal structure is key to generating adversarial examples in such systems. We exploit recent advances in generative adversarial network (GAN) architectures to account for temporal correlations and generate adversarial samples that can cause misclassification rates of over 80% for targeted activities. More importantly, the samples also leave other activities largely unaffected making them extremely stealthy. Finally, we also surprisingly find that in many scenarios, the same perturbation can be applied to every frame in a video clip that makes the adversary's ability to achieve misclassification relatively easy.