 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Alignment of Medical Vision-Language Models for Grounded Radiology Report Generation
Dec 18, 2025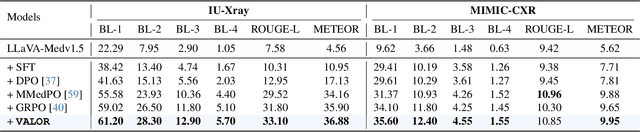
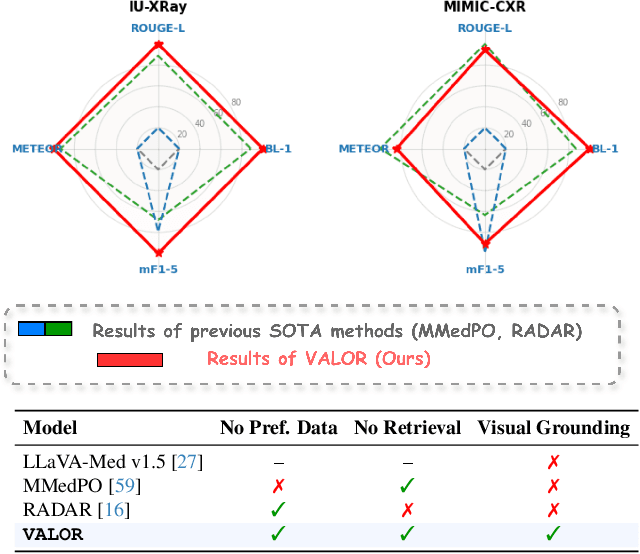
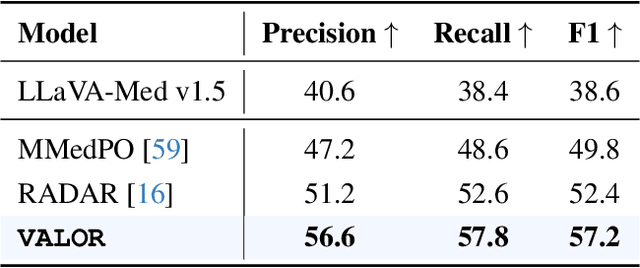
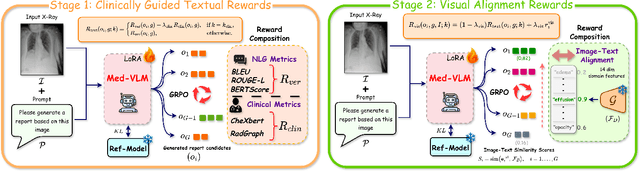
Radiology Report Generation (RRG) is a critical step toward automating healthcare workflows, facilitating accurate patient assessments, and reducing the workload of medical professionals. Despite recent progress in Large Medical Vision-Language Models (Med-VLMs), generating radiology reports that are both visually grounded and clinically accurate remains a significant challenge. Existing approaches often rely on large labeled corpora for pre-training, costly task-specific preference data, or retrieval-based methods. However, these strategies do not adequately mitigate hallucinations arising from poor cross-modal alignment between visual and linguistic representations. To address these limitations, we propose VALOR:Visual Alignment of Medical Vision-Language Models for GrOunded Radiology Report Generation. Our method introduces a reinforcement learning-based post-alignment framework utilizing Group-Relative Proximal Optimization (GRPO). The training proceeds in two stages: (1) improving the Med-VLM with textual rewards to encourage clinically precise terminology, and (2) aligning the vision projection module of the textually grounded model with disease findings, thereby guiding attention toward image re gions most relevant to the diagnostic task. Extensive experiments on multiple benchmarks demonstrate that VALOR substantially improves factual accuracy and visual grounding, achieving significant performance gains over state-of-the-art report generation methods.
Leveraging Synthetic Adult Datasets for Unsupervised Infant Pose Estimation
Apr 08, 2025Human pose estimation is a critical tool across a variety of healthcare applications. Despite significant progress in pose estimation algorithms targeting adults, such developments for infants remain limited. Existing algorithms for infant pose estimation, despite achieving commendable performance, depend on fully supervised approaches that require large amounts of labeled data. These algorithms also struggle with poor generalizability under distribution shifts. To address these challenges, we introduce SHIFT: Leveraging SyntHetic Adult Datasets for Unsupervised InFanT Pose Estimation, which leverages the pseudo-labeling-based Mean-Teacher framework to compensate for the lack of labeled data and addresses distribution shifts by enforcing consistency between the student and the teacher pseudo-labels. Additionally, to penalize implausible predictions obtained from the mean-teacher framework, we incorporate an infant manifold pose prior. To enhance SHIFT's self-occlusion perception ability, we propose a novel visibility consistency module for improved alignment of the predicted poses with the original image. Extensive experiments on multiple benchmarks show that SHIFT significantly outperforms existing state-of-the-art unsupervised domain adaptation (UDA) pose estimation methods by 5% and supervised infant pose estimation methods by a margin of 16%. The project page is available at: https://sarosijbose.github.io/SHIFT.
Uncertainty-Aware Diffusion Guided Refinement of 3D Scenes
Mar 19, 2025Reconstructing 3D scenes from a single image is a fundamentally ill-posed task due to the severely under-constrained nature of the problem. Consequently, when the scene is rendered from novel camera views, existing single image to 3D reconstruction methods render incoherent and blurry views. This problem is exacerbated when the unseen regions are far away from the input camera. In this work, we address these inherent limitations in existing single image-to-3D scene feedforward networks. To alleviate the poor performance due to insufficient information beyond the input image's view, we leverage a strong generative prior in the form of a pre-trained latent video diffusion model, for iterative refinement of a coarse scene represented by optimizable Gaussian parameters. To ensure that the style and texture of the generated images align with that of the input image, we incorporate on-the-fly Fourier-style transfer between the generated images and the input image. Additionally, we design a semantic uncertainty quantification module that calculates the per-pixel entropy and yields uncertainty maps used to guide the refinement process from the most confident pixels while discarding the remaining highly uncertain ones. We conduct extensive experiments on real-world scene datasets, including in-domain RealEstate-10K and out-of-domain KITTI-v2, showing that our approach can provide more realistic and high-fidelity novel view synthesis results compared to existing state-of-the-art methods.
Conformal Prediction and MLLM aided Uncertainty Quantification in Scene Graph Generation
Mar 18, 2025Scene Graph Generation (SGG) aims to represent visual scenes by identifying objects and their pairwise relationships, providing a structured understanding of image content. However, inherent challenges like long-tailed class distributions and prediction variability necessitate uncertainty quantification in SGG for its practical viability. In this paper, we introduce a novel Conformal Prediction (CP) based framework, adaptive to any existing SGG method, for quantifying their predictive uncertainty by constructing well-calibrated prediction sets over their generated scene graphs. These scene graph prediction sets are designed to achieve statistically rigorous coverage guarantees. Additionally, to ensure these prediction sets contain the most practically interpretable scene graphs, we design an effective MLLM-based post-processing strategy for selecting the most visually and semantically plausible scene graphs within these prediction sets. We show that our proposed approach can produce diverse possible scene graphs from an image, assess the reliability of SGG methods, and improve overall SGG performance.
Unsupervised Domain Adaptation for Occlusion Resilient Human Pose Estimation
Jan 06, 2025



Occlusions are a significant challenge to human pose estimation algorithms, often resulting in inaccurate and anatomically implausible poses. Although current occlusion-robust human pose estimation algorithms exhibit impressive performance on existing datasets, their success is largely attributed to supervised training and the availability of additional information, such as multiple views or temporal continuity. Furthermore, these algorithms typically suffer from performance degradation under distribution shifts. While existing domain adaptive human pose estimation algorithms address this bottleneck, they tend to perform suboptimally when the target domain images are occluded, a common occurrence in real-life scenarios. To address these challenges, we propose OR-POSE: Unsupervised Domain Adaptation for Occlusion Resilient Human POSE Estimation. OR-POSE is an innovative unsupervised domain adaptation algorithm which effectively mitigates domain shifts and overcomes occlusion challenges by employing the mean teacher framework for iterative pseudo-label refinement. Additionally, OR-POSE reinforces realistic pose prediction by leveraging a learned human pose prior which incorporates the anatomical constraints of humans in the adaptation process. Lastly, OR-POSE avoids overfitting to inaccurate pseudo labels generated from heavily occluded images by employing a novel visibility-based curriculum learning approach. This enables the model to gradually transition from training samples with relatively less occlusion to more challenging, heavily occluded samples. Extensive experiments show that OR-POSE outperforms existing analogous state-of-the-art algorithms by $\sim$ 7% on challenging occluded human pose estimation datasets.
SoccerKDNet: A Knowledge Distillation Framework for Action Recognition in Soccer Videos
Jul 22, 2023Classifying player actions from soccer videos is a challenging problem, which has become increasingly important in sports analytics over the years. Most state-of-the-art methods employ highly complex offline networks, which makes it difficult to deploy such models in resource constrained scenarios. Here, in this paper we propose a novel end-to-end knowledge distillation based transfer learning network pre-trained on the Kinetics400 dataset and then perform extensive analysis on the learned framework by introducing a unique loss parameterization. We also introduce a new dataset named SoccerDB1 containing 448 videos and consisting of 4 diverse classes each of players playing soccer. Furthermore, we introduce an unique loss parameter that help us linearly weigh the extent to which the predictions of each network are utilized. Finally, we also perform a thorough performance study using various changed hyperparameters. We also benchmark the first classification results on the new SoccerDB1 dataset obtaining 67.20% validation accuracy. Apart from outperforming prior arts significantly, our model also generalizes to new datasets easily. The dataset has been made publicly available at: https://bit.ly/soccerdb1
Lipschitz Bound Analysis of Neural Networks
Jul 14, 2022



Lipschitz Bound Estimation is an effective method of regularizing deep neural networks to make them robust against adversarial attacks. This is useful in a variety of applications ranging from reinforcement learning to autonomous systems. In this paper, we highlight the significant gap in obtaining a non-trivial Lipschitz bound certificate for Convolutional Neural Networks (CNNs) and empirically support it with extensive graphical analysis. We also show that unrolling Convolutional layers or Toeplitz matrices can be employed to convert Convolutional Neural Networks (CNNs) to a Fully Connected Network. Further, we propose a simple algorithm to show the existing 20x-50x gap in a particular data distribution between the actual lipschitz constant and the obtained tight bound. We also ran sets of thorough experiments on various network architectures and benchmark them on datasets like MNIST and CIFAR-10. All these proposals are supported by extensive testing, graphs, histograms and comparative analysis.