 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEExformer: A Fast Inferencing Transformer Architecture via Binarization with Multiple Early Exits
Dec 06, 2024Large Language Models (LLMs) based on transformers achieve cutting-edge results on a variety of applications. However, their enormous size and processing requirements make deployment on devices with constrained resources extremely difficult. Among various efficiency considerations, model binarization and Early Exit (EE) are common effective solutions. However, binarization may lead to performance loss due to reduced precision affecting gradient estimation and parameter updates. Besides, the present early-exit mechanisms are still in the nascent stages of research. To ameliorate these issues, we propose Binarized Early Exit Transformer (BEExformer), the first-ever selective learning transformer architecture to combine early exit with binarization for textual inference. It improves the binarization process through a differentiable second-order approximation to the impulse function. This enables gradient computation concerning both the sign as well as the magnitude of the weights. In contrast to absolute threshold-based EE, the proposed EE mechanism hinges on fractional reduction in entropy among intermediate transformer blocks with soft-routing loss estimation. While binarization results in 18.44 times reduction in model size, early exit reduces the FLOPs during inference by 54.85% and even improves accuracy by 5.98% through resolving the "overthinking" problem inherent in deep networks. Moreover, the proposed BEExformer simplifies training by not requiring knowledge distillation from a full-precision LLM. Extensive evaluation on the GLUE dataset and comparison with the SOTA works showcase its pareto-optimal performance-efficiency trade-off.
A Novel Denoising Technique and Deep Learning Based Hybrid Wind Speed Forecasting Model for Variable Terrain Conditions
Aug 28, 2024
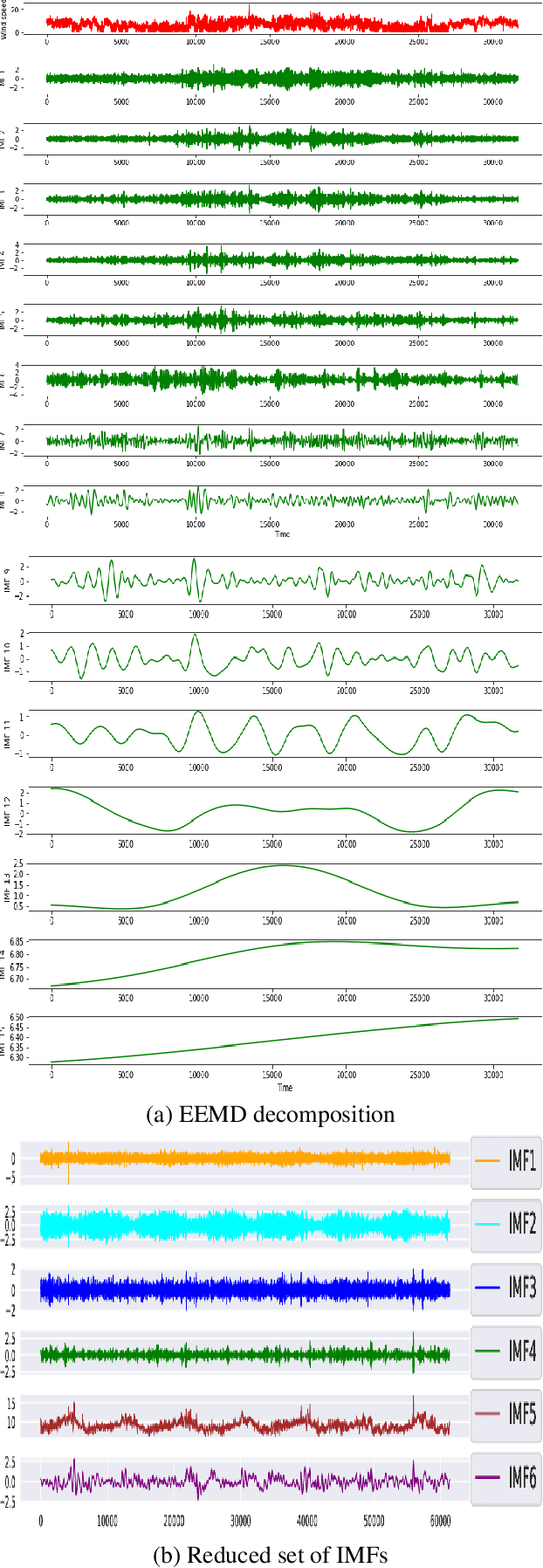

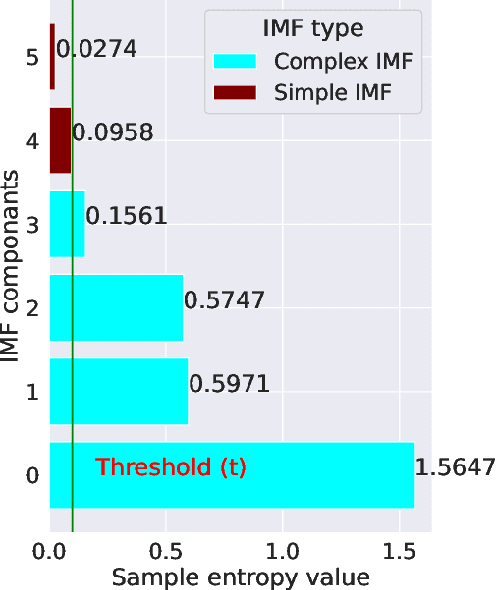
Wind flow can be highly unpredictable and can suffer substantial fluctuations in speed and direction due to the shape and height of hills, mountains, and valleys, making accurate wind speed (WS) forecasting essential in complex terrain. This paper presents a novel and adaptive model for short-term forecasting of WS. The paper's key contributions are as follows: (a) The Partial Auto Correlation Function (PACF) is utilised to minimise the dimension of the set of Intrinsic Mode Functions (IMF), hence reducing training time; (b) The sample entropy (SampEn) was used to calculate the complexity of the reduced set of IMFs. The proposed technique is adaptive since a specific Deep Learning (DL) model-feature combination was chosen based on complexity; (c) A novel bidirectional feature-LSTM framework for complicated IMFs has been suggested, resulting in improved forecasting accuracy; (d) The proposed model shows superior forecasting performance compared to the persistence, hybrid, Ensemble empirical mode decomposition (EEMD), and Variational Mode Decomposition (VMD)-based deep learning models. It has achieved the lowest variance in terms of forecasting accuracy between simple and complex terrain conditions 0.70%. Dimension reduction of IMF's and complexity-based model-feature selection helps reduce the training time by 68.77% and improve forecasting quality by 58.58% on average.
Enhancing Electrocardiogram Signal Analysis Using NLP-Inspired Techniques: A Novel Approach with Embedding and Self-Attention
Jul 15, 2024A language is made up of an infinite/finite number of sentences, which in turn is composed of a number of words. The Electrocardiogram (ECG) is the most popular noninvasive medical tool for studying heart function and diagnosing various irregular cardiac rhythms. Intuitive inspection of the ECG reveals a marked similarity between ECG signals and the spoken language. As a result, the ECG signal may be thought of as a series of heartbeats (similar to sentences in a spoken language), with each heartbeat consisting of a collection of waves (similar to words in a sentence) with varying morphologies. Just as natural language processing (NLP) is used to help computers comprehend and interpret human natural language, it is conceivable to create NLP-inspired algorithms to help computers comprehend the electrocardiogram data more efficiently. In this study, we propose a novel ECG analysis technique, based on embedding and self attention, to capture the spatial as well as the temporal dependencies of the ECG data. To generate the embedding, an encoder-decoder network was proposed to capture the temporal dependencies of the ECG signal and perform data compression. The compressed and encoded data was fed to the embedding layer as its weights. Finally, the proposed CNN-LSTM-Self Attention classifier works on the embedding layer and classifies the signal as normal or anomalous. The approach was tested using the PTB-xl dataset, which is severely imbalanced. Our emphasis was to appropriately recognise the disease classes present in minority numbers, in order to limit the detection of False Negative cases. An accuracy of 91% was achieved with a good F1-score for all the disease classes. Additionally, the the size of the model was reduced by 34% due to compression, making it suitable for deployment in real time applications
TexIm FAST: Text-to-Image Representation for Semantic Similarity Evaluation using Transformers
Jun 06, 2024One of the principal objectives of Natural Language Processing (NLP) is to generate meaningful representations from text. Improving the informativeness of the representations has led to a tremendous rise in the dimensionality and the memory footprint. It leads to a cascading effect amplifying the complexity of the downstream model by increasing its parameters. The available techniques cannot be applied to cross-modal applications such as text-to-image. To ameliorate these issues, a novel Text-to-Image methodology for generating fixed-length representations through a self-supervised Variational Auto-Encoder (VAE) for semantic evaluation applying transformers (TexIm FAST) has been proposed in this paper. The pictorial representations allow oblivious inference while retaining the linguistic intricacies, and are potent in cross-modal applications. TexIm FAST deals with variable-length sequences and generates fixed-length representations with over 75% reduced memory footprint. It enhances the efficiency of the models for downstream tasks by reducing its parameters. The efficacy of TexIm FAST has been extensively analyzed for the task of Semantic Textual Similarity (STS) upon the MSRPC, CNN/ Daily Mail, and XSum data-sets. The results demonstrate 6% improvement in accuracy compared to the baseline and showcase its exceptional ability to compare disparate length sequences such as a text with its summary.
Lumbar Spine Tumor Segmentation and Localization in T2 MRI Images Using AI
May 07, 2024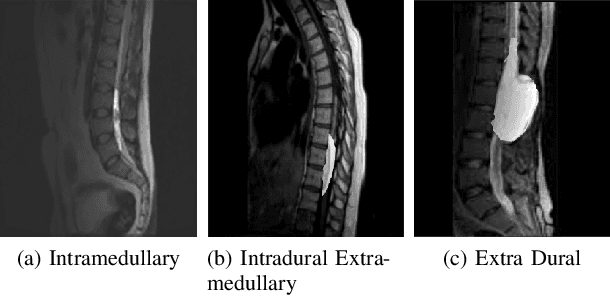


In medical imaging, segmentation and localization of spinal tumors in three-dimensional (3D) space pose significant computational challenges, primarily stemming from limited data availability. In response, this study introduces a novel data augmentation technique, aimed at automating spine tumor segmentation and localization through AI approaches. Leveraging a fusion of fuzzy c-means clustering and Random Forest algorithms, the proposed method achieves successful spine tumor segmentation based on predefined masks initially delineated by domain experts in medical imaging. Subsequently, a Convolutional Neural Network (CNN) architecture is employed for tumor classification. Moreover, 3D vertebral segmentation and labeling techniques are used to help pinpoint the exact location of the tumors in the lumbar spine. Results indicate a remarkable performance, with 99% accuracy for tumor segmentation, 98% accuracy for tumor classification, and 99% accuracy for tumor localization achieved with the proposed approach. These metrics surpass the efficacy of existing state-of-the-art techniques, as evidenced by superior Dice Score, Class Accuracy, and Intersection over Union (IOU) on class accuracy metrics. This innovative methodology holds promise for enhancing the diagnostic capabilities in detecting and characterizing spinal tumors, thereby facilitating more effective clinical decision-making.
Panoptic Segmentation and Labelling of Lumbar Spine Vertebrae using Modified Attention Unet
Apr 28, 2024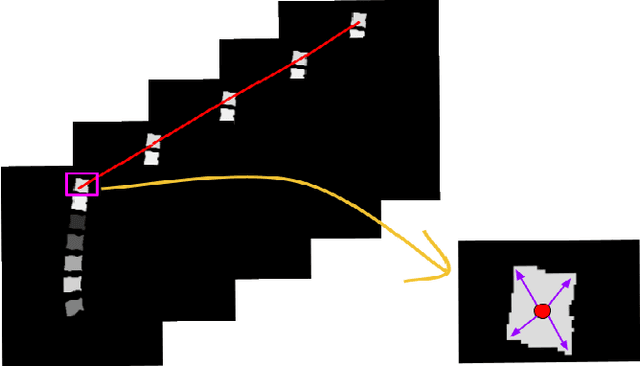


Segmentation and labeling of vertebrae in MRI images of the spine are critical for the diagnosis of illnesses and abnormalities. These steps are indispensable as MRI technology provides detailed information about the tissue structure of the spine. Both supervised and unsupervised segmentation methods exist, yet acquiring sufficient data remains challenging for achieving high accuracy. In this study, we propose an enhancing approach based on modified attention U-Net architecture for panoptic segmentation of 3D sliced MRI data of the lumbar spine. Our method achieves an impressive accuracy of 99.5\% by incorporating novel masking logic, thus significantly advancing the state-of-the-art in vertebral segmentation and labeling. This contributes to more precise and reliable diagnosis and treatment planning.
SoccerKDNet: A Knowledge Distillation Framework for Action Recognition in Soccer Videos
Jul 22, 2023Classifying player actions from soccer videos is a challenging problem, which has become increasingly important in sports analytics over the years. Most state-of-the-art methods employ highly complex offline networks, which makes it difficult to deploy such models in resource constrained scenarios. Here, in this paper we propose a novel end-to-end knowledge distillation based transfer learning network pre-trained on the Kinetics400 dataset and then perform extensive analysis on the learned framework by introducing a unique loss parameterization. We also introduce a new dataset named SoccerDB1 containing 448 videos and consisting of 4 diverse classes each of players playing soccer. Furthermore, we introduce an unique loss parameter that help us linearly weigh the extent to which the predictions of each network are utilized. Finally, we also perform a thorough performance study using various changed hyperparameters. We also benchmark the first classification results on the new SoccerDB1 dataset obtaining 67.20% validation accuracy. Apart from outperforming prior arts significantly, our model also generalizes to new datasets easily. The dataset has been made publicly available at: https://bit.ly/soccerdb1
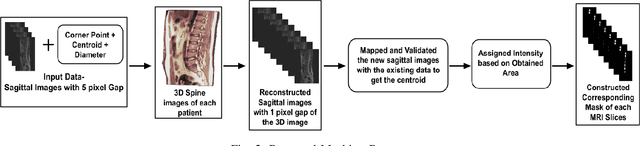
Fast 3D Volumetric Image Reconstruction from 2D MRI Slices by Parallel Processing
Mar 16, 2023Magnetic Resonance Imaging (MRI) is a technology for non-invasive imaging of anatomical features in detail. It can help in functional analysis of organs of a specimen but it is very costly. In this work, methods for (i) virtual three-dimensional (3D) reconstruction from a single sequence of two-dimensional (2D) slices of MR images of a human spine and brain along a single axis, and (ii) generation of missing inter-slice data are proposed. Our approach helps in preserving the edges, shape, size, as well as the internal tissue structures of the object being captured. The sequence of original 2D slices along a single axis is divided into smaller equal sub-parts which are then reconstructed using edge preserved kriging interpolation to predict the missing slice information. In order to speed up the process of interpolation, we have used multiprocessing by carrying out the initial interpolation on parallel cores. From the 3D matrix thus formed, shearlet transform is applied to estimate the edges considering the 2D blocks along the $Z$ axis, and to minimize the blurring effect using a proposed mean-median logic. Finally, for visualization, the sub-matrices are merged into a final 3D matrix. Next, the newly formed 3D matrix is split up into voxels and marching cubes method is applied to get the approximate 3D image for viewing. To the best of our knowledge it is a first of its kind approach based on kriging interpolation and multiprocessing for 3D reconstruction from 2D slices, and approximately 98.89\% accuracy is achieved with respect to similarity metrics for image comparison. The time required for reconstruction has also been reduced by approximately 70\% with multiprocessing even for a large input data set compared to that with single core processing.
IoT based Smart Access Controlled Secure Smart City Architecture Using Blockchain
Sep 09, 2019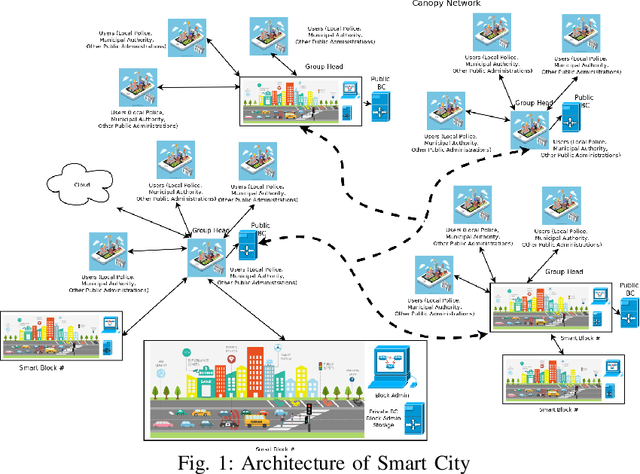
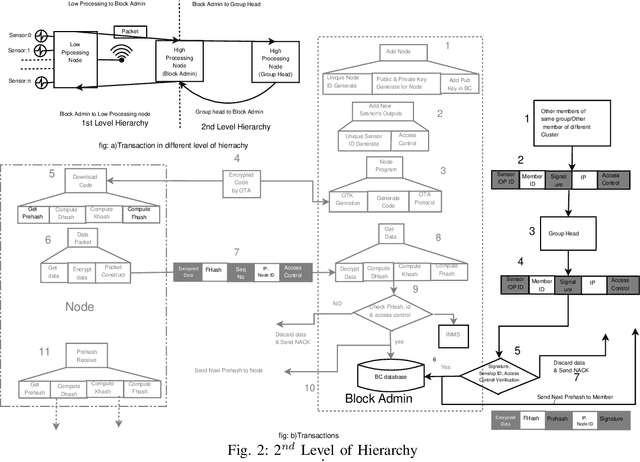
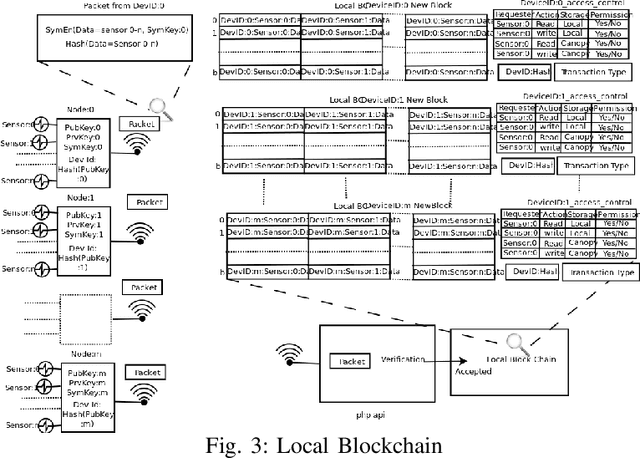
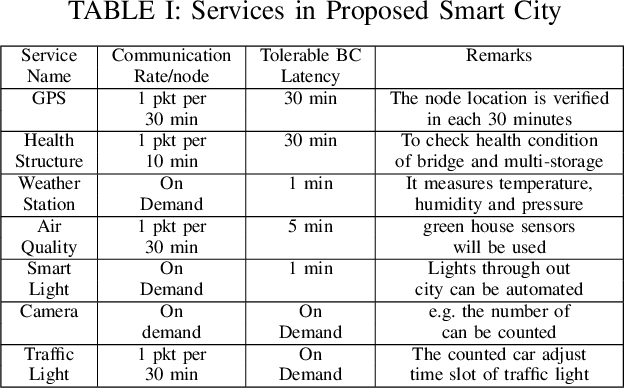
Standard security protocols like SSL, TLS, IPSec etc. have high memory and processor consumption which makes all these security protocols unsuitable for resource constrained platforms such as Internet of Things (IoT). Blockchain (BC) finds its efficient application in IoT platform to preserve the five basic cryptographic primitives, such as confidentiality, authenticity, integrity, availability and non-repudiation. Conventional adoption of BC in IoT platform causes high energy consumption, delay and computational overhead which are not appropriate for various resource constrained IoT devices. This work proposes a machine learning (ML) based smart access control framework in a public and a private BC for a smart city application which makes it more efficient as compared to the existing IoT applications. The proposed IoT based smart city architecture adopts BC technology for preserving all the cryptographic security and privacy issues. Moreover, BC has very minimal overhead on IoT platform as well. This work investigates the existing threat models and critical access control issues which handle multiple permissions of various nodes and detects relevant inconsistencies to notify the corresponding nodes. Comparison in terms of all security issues with existing literature shows that the proposed architecture is competitively efficient in terms of security access control.
A Novel Approach for Human Action Recognition from Silhouette Images
Oct 15, 2015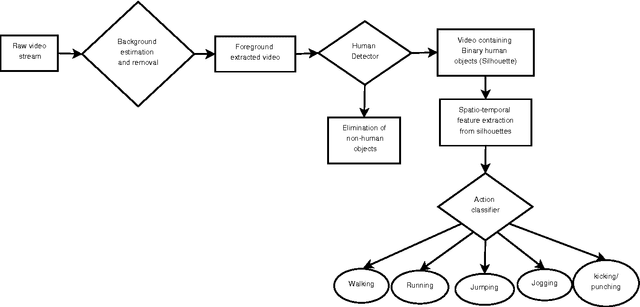
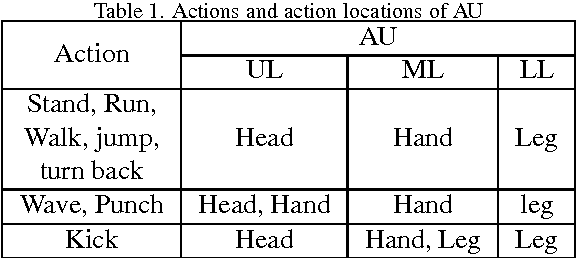
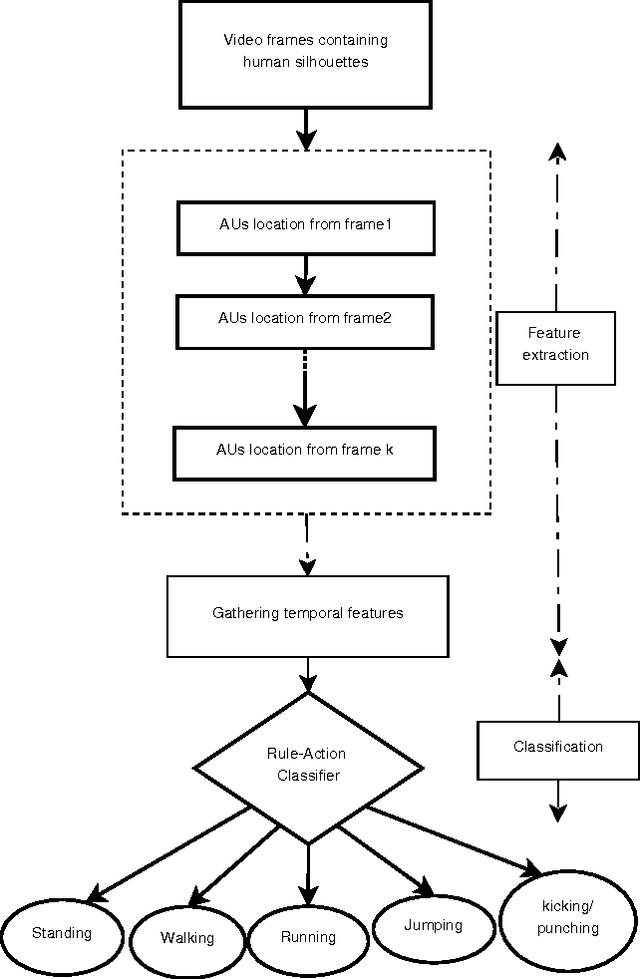
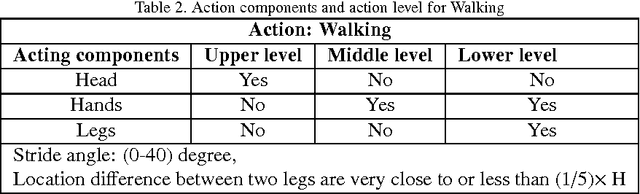
In this paper, a novel human action recognition technique from video is presented. Any action of human is a combination of several micro action sequences performed by one or more body parts of the human. The proposed approach uses spatio-temporal body parts movement (STBPM) features extracted from foreground silhouette of the human objects. The newly proposed STBPM feature estimates the movements of different body parts for any given time segment to classify actions. We also proposed a rule based logic named rule action classifier (RAC), which uses a series of condition action rules based on prior knowledge and hence does not required training to classify any action. Since we don't require training to classify actions, the proposed approach is view independent. The experimental results on publicly available Wizeman and MuHVAi datasets are compared with that of the related research work in terms of accuracy in the human action detection, and proposed technique outperforms the others.