 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEExformer: A Fast Inferencing Transformer Architecture via Binarization with Multiple Early Exits
Dec 06, 2024Large Language Models (LLMs) based on transformers achieve cutting-edge results on a variety of applications. However, their enormous size and processing requirements make deployment on devices with constrained resources extremely difficult. Among various efficiency considerations, model binarization and Early Exit (EE) are common effective solutions. However, binarization may lead to performance loss due to reduced precision affecting gradient estimation and parameter updates. Besides, the present early-exit mechanisms are still in the nascent stages of research. To ameliorate these issues, we propose Binarized Early Exit Transformer (BEExformer), the first-ever selective learning transformer architecture to combine early exit with binarization for textual inference. It improves the binarization process through a differentiable second-order approximation to the impulse function. This enables gradient computation concerning both the sign as well as the magnitude of the weights. In contrast to absolute threshold-based EE, the proposed EE mechanism hinges on fractional reduction in entropy among intermediate transformer blocks with soft-routing loss estimation. While binarization results in 18.44 times reduction in model size, early exit reduces the FLOPs during inference by 54.85% and even improves accuracy by 5.98% through resolving the "overthinking" problem inherent in deep networks. Moreover, the proposed BEExformer simplifies training by not requiring knowledge distillation from a full-precision LLM. Extensive evaluation on the GLUE dataset and comparison with the SOTA works showcase its pareto-optimal performance-efficiency trade-off.
A Novel Denoising Technique and Deep Learning Based Hybrid Wind Speed Forecasting Model for Variable Terrain Conditions
Aug 28, 2024
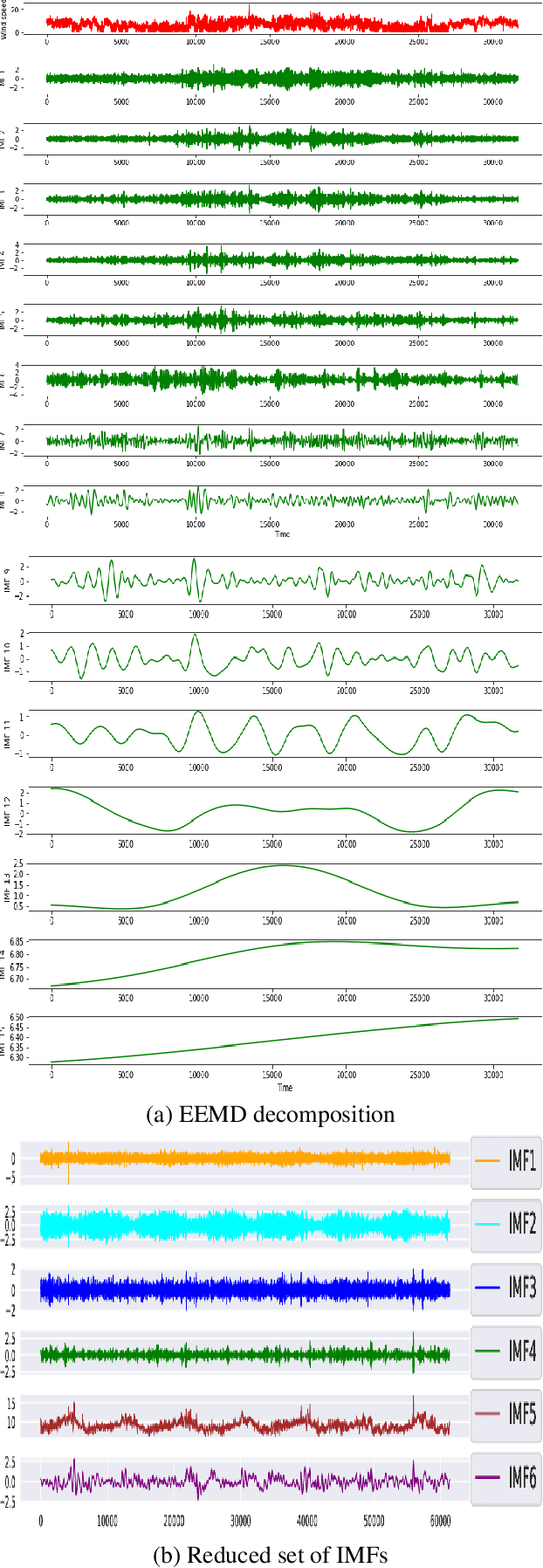

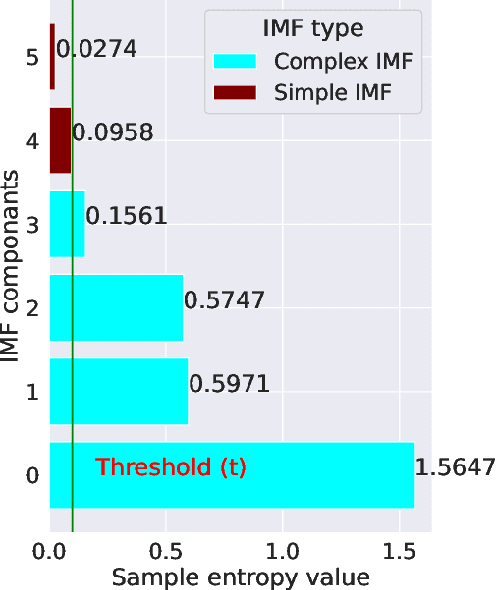
Wind flow can be highly unpredictable and can suffer substantial fluctuations in speed and direction due to the shape and height of hills, mountains, and valleys, making accurate wind speed (WS) forecasting essential in complex terrain. This paper presents a novel and adaptive model for short-term forecasting of WS. The paper's key contributions are as follows: (a) The Partial Auto Correlation Function (PACF) is utilised to minimise the dimension of the set of Intrinsic Mode Functions (IMF), hence reducing training time; (b) The sample entropy (SampEn) was used to calculate the complexity of the reduced set of IMFs. The proposed technique is adaptive since a specific Deep Learning (DL) model-feature combination was chosen based on complexity; (c) A novel bidirectional feature-LSTM framework for complicated IMFs has been suggested, resulting in improved forecasting accuracy; (d) The proposed model shows superior forecasting performance compared to the persistence, hybrid, Ensemble empirical mode decomposition (EEMD), and Variational Mode Decomposition (VMD)-based deep learning models. It has achieved the lowest variance in terms of forecasting accuracy between simple and complex terrain conditions 0.70%. Dimension reduction of IMF's and complexity-based model-feature selection helps reduce the training time by 68.77% and improve forecasting quality by 58.58% on average.
TexIm FAST: Text-to-Image Representation for Semantic Similarity Evaluation using Transformers
Jun 06, 2024One of the principal objectives of Natural Language Processing (NLP) is to generate meaningful representations from text. Improving the informativeness of the representations has led to a tremendous rise in the dimensionality and the memory footprint. It leads to a cascading effect amplifying the complexity of the downstream model by increasing its parameters. The available techniques cannot be applied to cross-modal applications such as text-to-image. To ameliorate these issues, a novel Text-to-Image methodology for generating fixed-length representations through a self-supervised Variational Auto-Encoder (VAE) for semantic evaluation applying transformers (TexIm FAST) has been proposed in this paper. The pictorial representations allow oblivious inference while retaining the linguistic intricacies, and are potent in cross-modal applications. TexIm FAST deals with variable-length sequences and generates fixed-length representations with over 75% reduced memory footprint. It enhances the efficiency of the models for downstream tasks by reducing its parameters. The efficacy of TexIm FAST has been extensively analyzed for the task of Semantic Textual Similarity (STS) upon the MSRPC, CNN/ Daily Mail, and XSum data-sets. The results demonstrate 6% improvement in accuracy compared to the baseline and showcase its exceptional ability to compare disparate length sequences such as a text with its summary.