 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVDIFF: Grounded Text-to-Video Generation with Diffusion Models
Paper and Code
Jul 02, 2024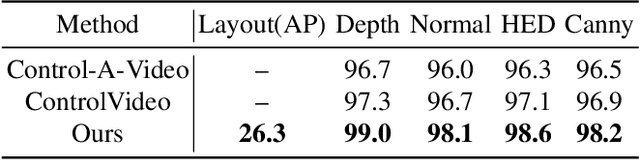
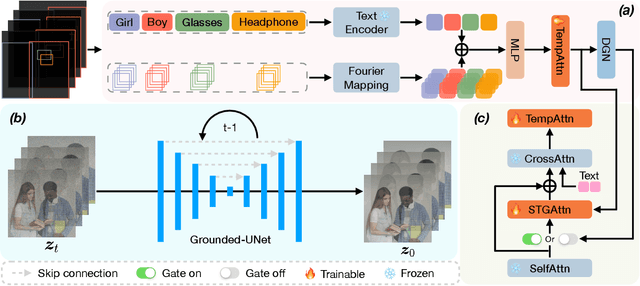

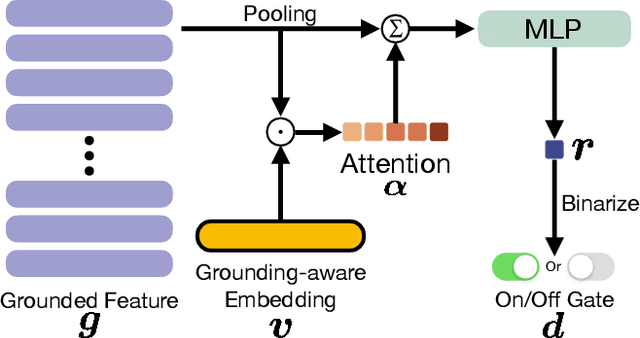
In text-to-video (T2V) generation, significant attention has been directed toward its development, yet unifying discrete and continuous grounding conditions in T2V generation remains under-explored. This paper proposes a Grounded text-to-Video generation framework, termed GVDIFF. First, we inject the grounding condition into the self-attention through an uncertainty-based representation to explicitly guide the focus of the network. Second, we introduce a spatial-temporal grounding layer that connects the grounding condition with target objects and enables the model with the grounded generation capacity in the spatial-temporal domain. Third, our dynamic gate network adaptively skips the redundant grounding process to selectively extract grounding information and semantics while improving efficiency. We extensively evaluate the grounded generation capacity of GVDIFF and demonstrate its versatility in applications, including long-range video generation, sequential prompts, and object-specific editing.