 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVDIFF: Grounded Text-to-Video Generation with Diffusion Models
Jul 02, 2024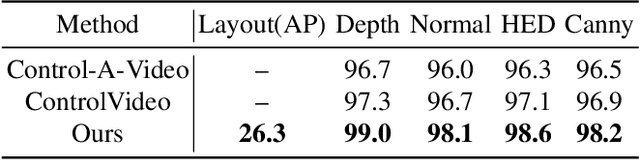
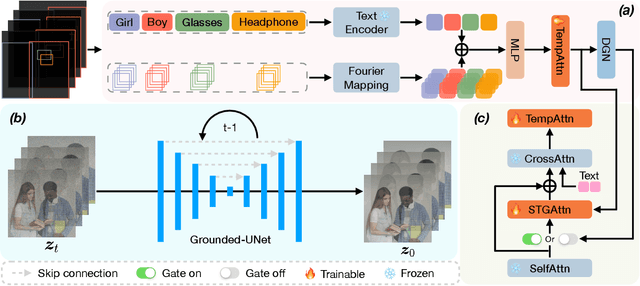

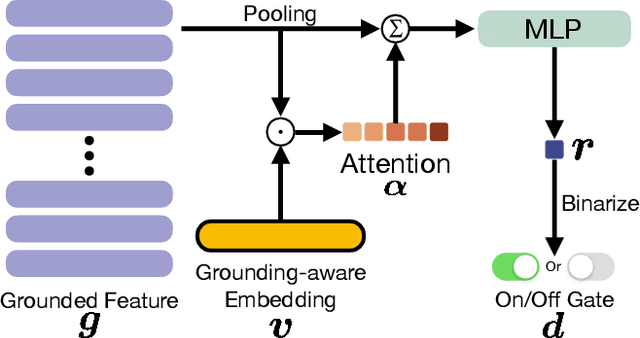
In text-to-video (T2V) generation, significant attention has been directed toward its development, yet unifying discrete and continuous grounding conditions in T2V generation remains under-explored. This paper proposes a Grounded text-to-Video generation framework, termed GVDIFF. First, we inject the grounding condition into the self-attention through an uncertainty-based representation to explicitly guide the focus of the network. Second, we introduce a spatial-temporal grounding layer that connects the grounding condition with target objects and enables the model with the grounded generation capacity in the spatial-temporal domain. Third, our dynamic gate network adaptively skips the redundant grounding process to selectively extract grounding information and semantics while improving efficiency. We extensively evaluate the grounded generation capacity of GVDIFF and demonstrate its versatility in applications, including long-range video generation, sequential prompts, and object-specific editing.
HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird's Eye View
Jul 25, 2023Vision-based Bird's Eye View (BEV) representation is an emerging perception formulation for autonomous driving. The core challenge is to construct BEV space with multi-camera features, which is a one-to-many ill-posed problem. Diving into all previous BEV representation generation methods, we found that most of them fall into two types: modeling depths in image views or modeling heights in the BEV space, mostly in an implicit way. In this work, we propose to explicitly model heights in the BEV space, which needs no extra data like LiDAR and can fit arbitrary camera rigs and types compared to modeling depths. Theoretically, we give proof of the equivalence between height-based methods and depth-based methods. Considering the equivalence and some advantages of modeling heights, we propose HeightFormer, which models heights and uncertainties in a self-recursive way. Without any extra data, the proposed HeightFormer could estimate heights in BEV accurately. Benchmark results show that the performance of HeightFormer achieves SOTA compared with those camera-only methods.