 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScanFormer: Referring Expression Comprehension by Iteratively Scanning
Jun 26, 2024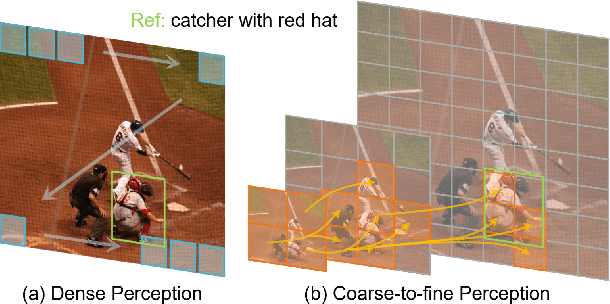
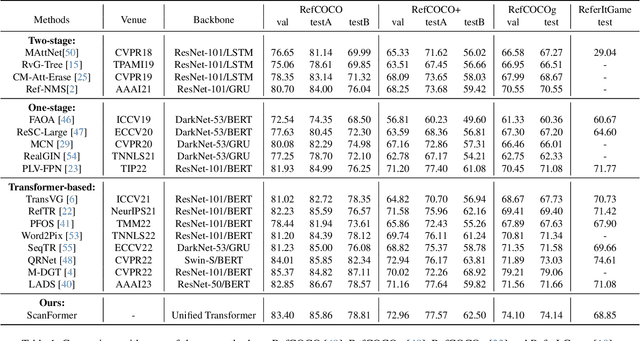
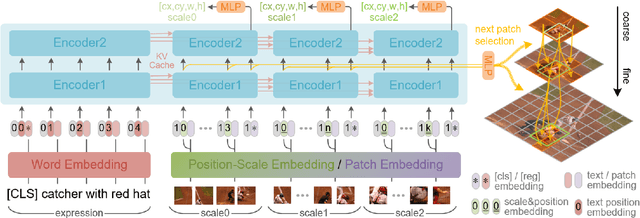
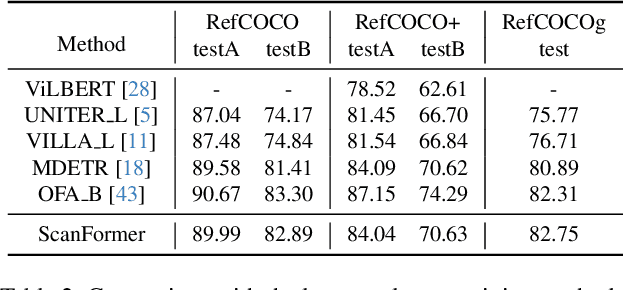
Referring Expression Comprehension (REC) aims to localize the target objects specified by free-form natural language descriptions in images. While state-of-the-art methods achieve impressive performance, they perform a dense perception of images, which incorporates redundant visual regions unrelated to linguistic queries, leading to additional computational overhead. This inspires us to explore a question: can we eliminate linguistic-irrelevant redundant visual regions to improve the efficiency of the model? Existing relevant methods primarily focus on fundamental visual tasks, with limited exploration in vision-language fields. To address this, we propose a coarse-to-fine iterative perception framework, called ScanFormer. It can iteratively exploit the image scale pyramid to extract linguistic-relevant visual patches from top to bottom. In each iteration, irrelevant patches are discarded by our designed informativeness prediction. Furthermore, we propose a patch selection strategy for discarded patches to accelerate inference. Experiments on widely used datasets, namely RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, verify the effectiveness of our method, which can strike a balance between accuracy and efficiency.
Referring Expression Comprehension Using Language Adaptive Inference
Jun 06, 2023



Different from universal object detection, referring expression comprehension (REC) aims to locate specific objects referred to by natural language expressions. The expression provides high-level concepts of relevant visual and contextual patterns, which vary significantly with different expressions and account for only a few of those encoded in the REC model. This leads us to a question: do we really need the entire network with a fixed structure for various referring expressions? Ideally, given an expression, only expression-relevant components of the REC model are required. These components should be small in number as each expression only contains very few visual and contextual clues. This paper explores the adaptation between expressions and REC models for dynamic inference. Concretely, we propose a neat yet efficient framework named Language Adaptive Dynamic Subnets (LADS), which can extract language-adaptive subnets from the REC model conditioned on the referring expressions. By using the compact subnet, the inference can be more economical and efficient. Extensive experiments on RefCOCO, RefCOCO+, RefCOCOg, and Referit show that the proposed method achieves faster inference speed and higher accuracy against state-of-the-art approaches.
Language Adaptive Weight Generation for Multi-task Visual Grounding
Jun 06, 2023
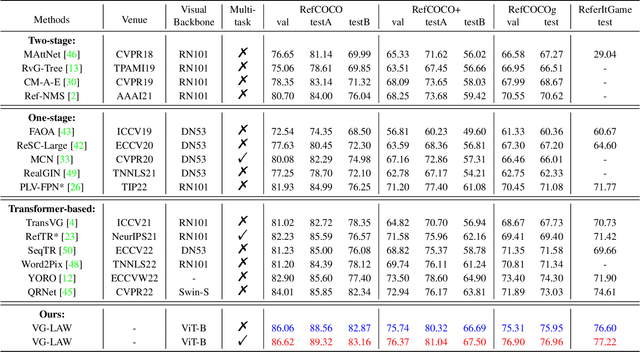
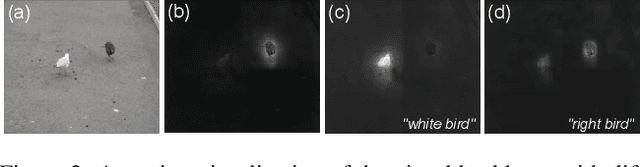
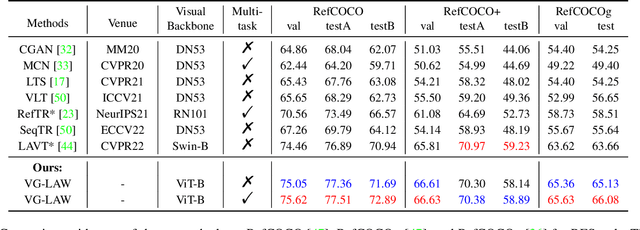
Although the impressive performance in visual grounding, the prevailing approaches usually exploit the visual backbone in a passive way, i.e., the visual backbone extracts features with fixed weights without expression-related hints. The passive perception may lead to mismatches (e.g., redundant and missing), limiting further performance improvement. Ideally, the visual backbone should actively extract visual features since the expressions already provide the blueprint of desired visual features. The active perception can take expressions as priors to extract relevant visual features, which can effectively alleviate the mismatches. Inspired by this, we propose an active perception Visual Grounding framework based on Language Adaptive Weights, called VG-LAW. The visual backbone serves as an expression-specific feature extractor through dynamic weights generated for various expressions. Benefiting from the specific and relevant visual features extracted from the language-aware visual backbone, VG-LAW does not require additional modules for cross-modal interaction. Along with a neat multi-task head, VG-LAW can be competent in referring expression comprehension and segmentation jointly. Extensive experiments on four representative datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, validate the effectiveness of the proposed framework and demonstrate state-of-the-art performance.
Referring Expression Comprehension via Cross-Level Multi-Modal Fusion
Apr 21, 2022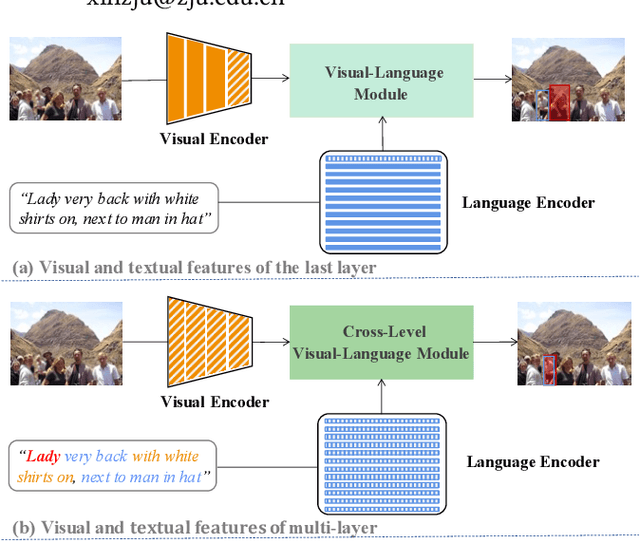
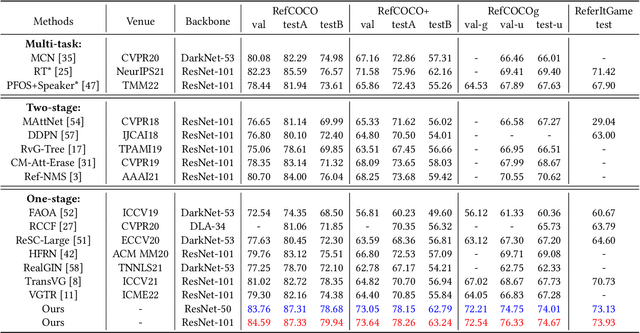


As an important and challenging problem in vision-language tasks, referring expression comprehension (REC) aims to localize the target object specified by a given referring expression. Recently, most of the state-of-the-art REC methods mainly focus on multi-modal fusion while overlooking the inherent hierarchical information contained in visual and language encoders. Considering that REC requires visual and textual hierarchical information for accurate target localization, and encoders inherently extract features in a hierarchical fashion, we propose to effectively utilize the rich hierarchical information contained in different layers of visual and language encoders. To this end, we design a Cross-level Multi-modal Fusion (CMF) framework, which gradually integrates visual and textual features of multi-layer through intra- and inter-modal. Experimental results on RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame datasets demonstrate the proposed framework achieves significant performance improvements over state-of-the-art methods.