 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Expression Comprehension via Cross-Level Multi-Modal Fusion
Paper and Code
Apr 21, 2022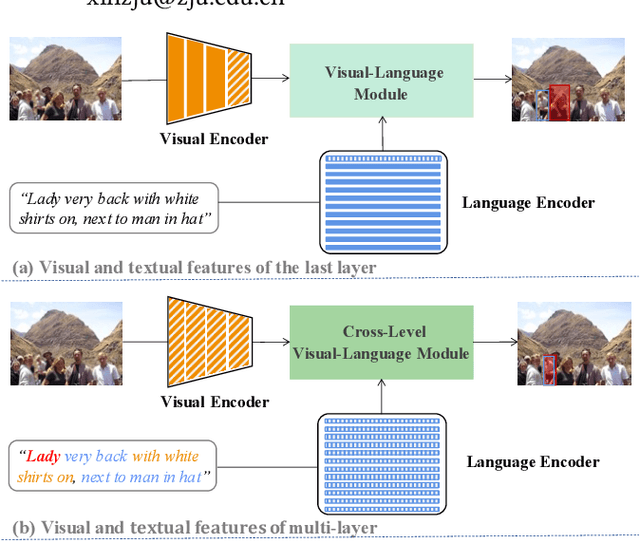
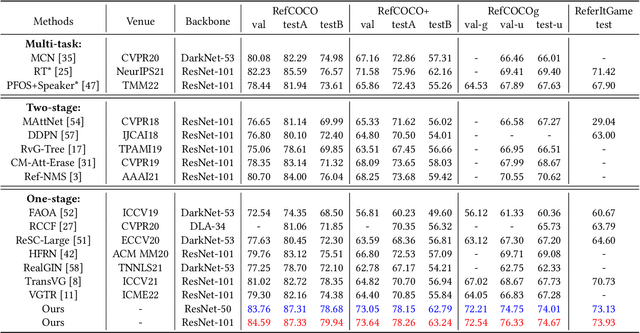


As an important and challenging problem in vision-language tasks, referring expression comprehension (REC) aims to localize the target object specified by a given referring expression. Recently, most of the state-of-the-art REC methods mainly focus on multi-modal fusion while overlooking the inherent hierarchical information contained in visual and language encoders. Considering that REC requires visual and textual hierarchical information for accurate target localization, and encoders inherently extract features in a hierarchical fashion, we propose to effectively utilize the rich hierarchical information contained in different layers of visual and language encoders. To this end, we design a Cross-level Multi-modal Fusion (CMF) framework, which gradually integrates visual and textual features of multi-layer through intra- and inter-modal. Experimental results on RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame datasets demonstrate the proposed framework achieves significant performance improvements over state-of-the-art methods.