 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Content-based Recommendation Model Training via Noise-aware Coreset Selection
Jan 15, 2026Content-based recommendation systems (CRSs) utilize content features to predict user-item interactions, serving as essential tools for helping users navigate information-rich web services. However, ensuring the effectiveness of CRSs requires large-scale and even continuous model training to accommodate diverse user preferences, resulting in significant computational costs and resource demands. A promising approach to this challenge is coreset selection, which identifies a small but representative subset of data samples that preserves model quality while reducing training overhead. Yet, the selected coreset is vulnerable to the pervasive noise in user-item interactions, particularly when it is minimally sized. To this end, we propose Noise-aware Coreset Selection (NaCS), a specialized framework for CRSs. NaCS constructs coresets through submodular optimization based on training gradients, while simultaneously correcting noisy labels using a progressively trained model. Meanwhile, we refine the selected coreset by filtering out low-confidence samples through uncertainty quantification, thereby avoid training with unreliable interactions. Through extensive experiments, we show that NaCS produces higher-quality coresets for CRSs while achieving better efficiency than existing coreset selection techniques. Notably, NaCS recovers 93-95\% of full-dataset training performance using merely 1\% of the training data. The source code is available at \href{https://github.com/chenxing1999/nacs}{https://github.com/chenxing1999/nacs}.
On-device Content-based Recommendation with Single-shot Embedding Pruning: A Cooperative Game Perspective
Nov 20, 2024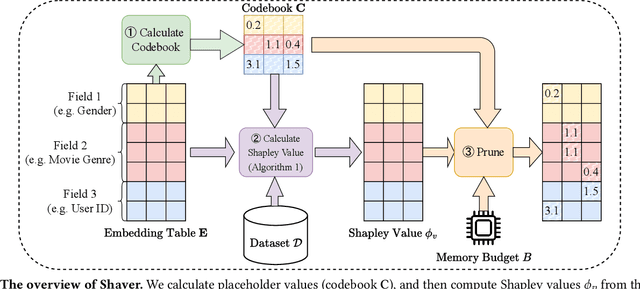
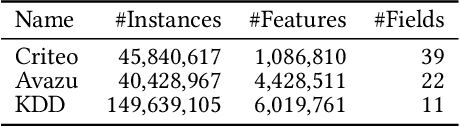
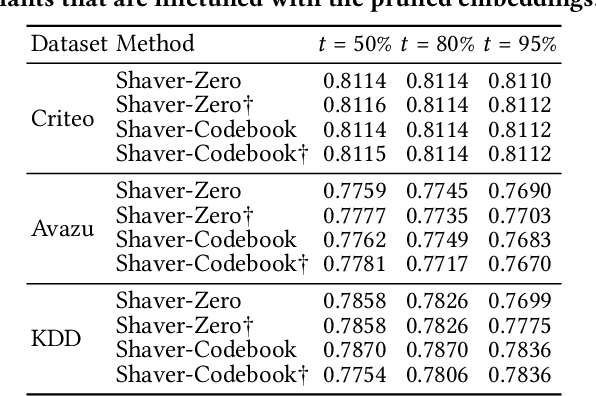
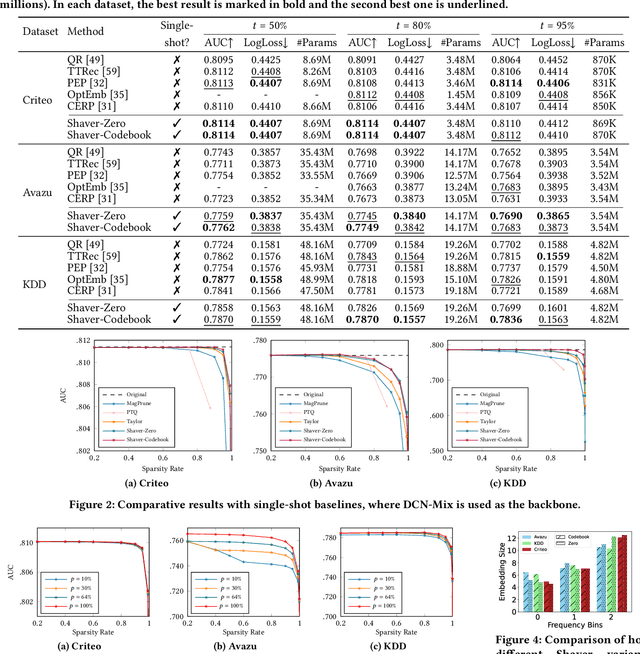
Content-based Recommender Systems (CRSs) play a crucial role in shaping user experiences in e-commerce, online advertising, and personalized recommendations. However, due to the vast amount of categorical features, the embedding tables used in CRS models pose a significant storage bottleneck for real-world deployment, especially on resource-constrained devices. To address this problem, various embedding pruning methods have been proposed, but most existing ones require expensive retraining steps for each target parameter budget, leading to enormous computation costs. In reality, this computation cost is a major hurdle in real-world applications with diverse storage requirements, such as federated learning and streaming settings. In this paper, we propose Shapley Value-guided Embedding Reduction (Shaver) as our response. With Shaver, we view the problem from a cooperative game perspective, and quantify each embedding parameter's contribution with Shapley values to facilitate contribution-based parameter pruning. To address the inherently high computation costs of Shapley values, we propose an efficient and unbiased method to estimate Shapley values of a CRS's embedding parameters. Moreover, in the pruning stage, we put forward a field-aware codebook to mitigate the information loss in the traditional zero-out treatment. Through extensive experiments on three real-world datasets, Shaver has demonstrated competitive performance with lightweight recommendation models across various parameter budgets. The source code is available at https://anonymous.4open.science/r/shaver-E808
A Thorough Performance Benchmarking on Lightweight Embedding-based Recommender Systems
Jun 25, 2024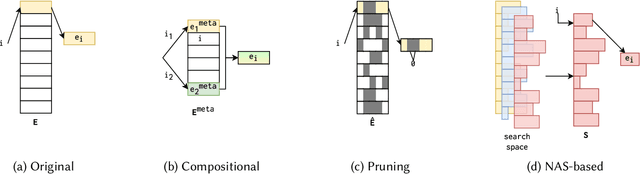


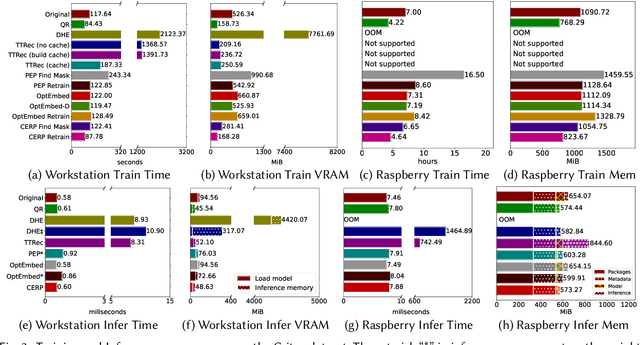
Since the creation of the Web, recommender systems (RSs) have been an indispensable mechanism in information filtering. State-of-the-art RSs primarily depend on categorical features, which ecoded by embedding vectors, resulting in excessively large embedding tables. To prevent over-parameterized embedding tables from harming scalability, both academia and industry have seen increasing efforts in compressing RS embeddings. However, despite the prosperity of lightweight embedding-based RSs (LERSs), a wide diversity is seen in evaluation protocols, resulting in obstacles when relating LERS performance to real-world usability. Moreover, despite the common goal of lightweight embeddings, LERSs are evaluated with a single choice between the two main recommendation tasks -- collaborative filtering and content-based recommendation. This lack of discussions on cross-task transferability hinders the development of unified, more scalable solutions. Motivated by these issues, this study investigates various LERSs' performance, efficiency, and cross-task transferability via a thorough benchmarking process. Additionally, we propose an efficient embedding compression method using magnitude pruning, which is an easy-to-deploy yet highly competitive baseline that outperforms various complex LERSs. Our study reveals the distinct performance of LERSs across the two tasks, shedding light on their effectiveness and generalizability. To support edge-based recommendations, we tested all LERSs on a Raspberry Pi 4, where the efficiency bottleneck is exposed. Finally, we conclude this paper with critical summaries of LERS performance, model selection suggestions, and underexplored challenges around LERSs for future research. To encourage future research, we publish source codes and artifacts at \href{this link}{https://github.com/chenxing1999/recsys-benchmark}.