 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDATA-WA: Demand-based Adaptive Task Assignment with Dynamic Worker Availability Windows
Mar 27, 2025With the rapid advancement of mobile networks and the widespread use of mobile devices, spatial crowdsourcing, which involves assigning location-based tasks to mobile workers, has gained significant attention. However, most existing research focuses on task assignment at the current moment, overlooking the fluctuating demand and supply between tasks and workers over time. To address this issue, we introduce an adaptive task assignment problem, which aims to maximize the number of assigned tasks by dynamically adjusting task assignments in response to changing demand and supply. We develop a spatial crowdsourcing framework, namely demand-based adaptive task assignment with dynamic worker availability windows, which consists of two components including task demand prediction and task assignment. In the first component, we construct a graph adjacency matrix representing the demand dependency relationships in different regions and employ a multivariate time series learning approach to predict future task demands. In the task assignment component, we adjust tasks to workers based on these predictions, worker availability windows, and the current task assignments, where each worker has an availability window that indicates the time periods they are available for task assignments. To reduce the search space of task assignments and be efficient, we propose a worker dependency separation approach based on graph partition and a task value function with reinforcement learning. Experiments on real data demonstrate that our proposals are both effective and efficient.
BOSS: Bottom-up Cross-modal Semantic Composition with Hybrid Counterfactual Training for Robust Content-based Image Retrieval
Jul 09, 2022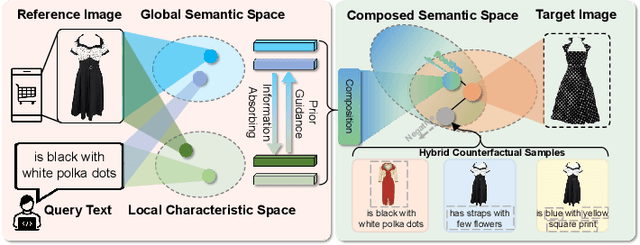

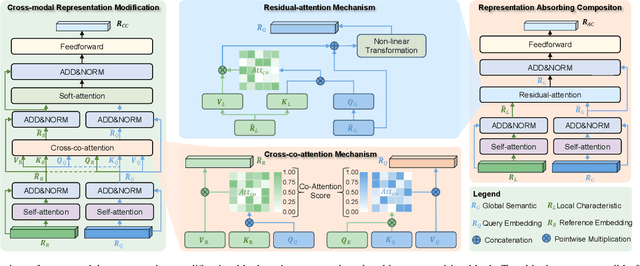

Content-Based Image Retrieval (CIR) aims to search for a target image by concurrently comprehending the composition of an example image and a complementary text, which potentially impacts a wide variety of real-world applications, such as internet search and fashion retrieval. In this scenario, the input image serves as an intuitive context and background for the search, while the corresponding language expressly requests new traits on how specific characteristics of the query image should be modified in order to get the intended target image. This task is challenging since it necessitates learning and understanding the composite image-text representation by incorporating cross-granular semantic updates. In this paper, we tackle this task by a novel \underline{\textbf{B}}ottom-up cr\underline{\textbf{O}}ss-modal \underline{\textbf{S}}emantic compo\underline{\textbf{S}}ition (\textbf{BOSS}) with Hybrid Counterfactual Training framework, which sheds new light on the CIR task by studying it from two previously overlooked perspectives: \emph{implicitly bottom-up composition of visiolinguistic representation} and \emph{explicitly fine-grained correspondence of query-target construction}. On the one hand, we leverage the implicit interaction and composition of cross-modal embeddings from the bottom local characteristics to the top global semantics, preserving and transforming the visual representation conditioned on language semantics in several continuous steps for effective target image search. On the other hand, we devise a hybrid counterfactual training strategy that can reduce the model's ambiguity for similar queries.
Collaborative Intelligence Orchestration: Inconsistency-Based Fusion of Semi-Supervised Learning and Active Learning
Jun 07, 2022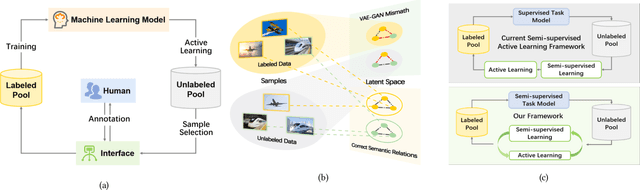



While annotating decent amounts of data to satisfy sophisticated learning models can be cost-prohibitive for many real-world applications. Active learning (AL) and semi-supervised learning (SSL) are two effective, but often isolated, means to alleviate the data-hungry problem. Some recent studies explored the potential of combining AL and SSL to better probe the unlabeled data. However, almost all these contemporary SSL-AL works use a simple combination strategy, ignoring SSL and AL's inherent relation. Further, other methods suffer from high computational costs when dealing with large-scale, high-dimensional datasets. Motivated by the industry practice of labeling data, we propose an innovative Inconsistency-based virtual aDvErsarial Active Learning (IDEAL) algorithm to further investigate SSL-AL's potential superiority and achieve mutual enhancement of AL and SSL, i.e., SSL propagates label information to unlabeled samples and provides smoothed embeddings for AL, while AL excludes samples with inconsistent predictions and considerable uncertainty for SSL. We estimate unlabeled samples' inconsistency by augmentation strategies of different granularities, including fine-grained continuous perturbation exploration and coarse-grained data transformations. Extensive experiments, in both text and image domains, validate the effectiveness of the proposed algorithm, comparing it against state-of-the-art baselines. Two real-world case studies visualize the practical industrial value of applying and deploying the proposed data sampling algorithm.
MAGIC: Multimodal relAtional Graph adversarIal inferenCe for Diverse and Unpaired Text-based Image Captioning
Dec 13, 2021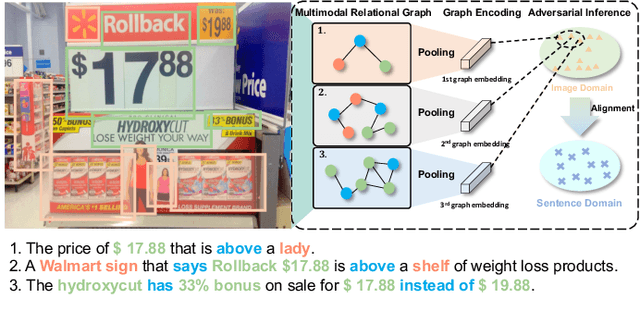
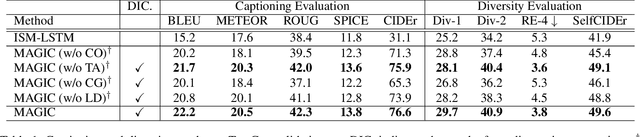
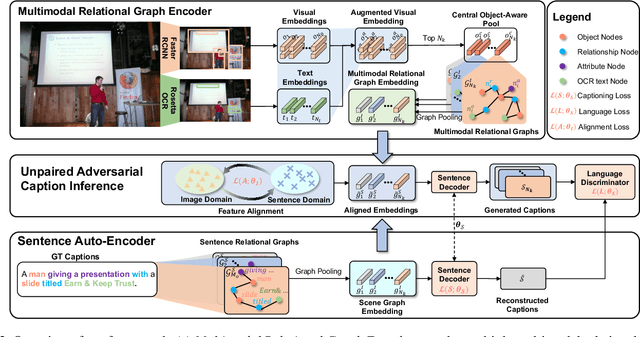
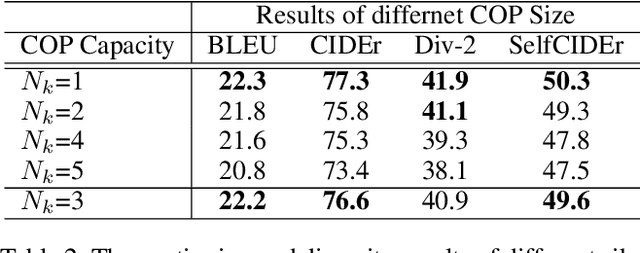
Text-based image captioning (TextCap) requires simultaneous comprehension of visual content and reading the text of images to generate a natural language description. Although a task can teach machines to understand the complex human environment further given that text is omnipresent in our daily surroundings, it poses additional challenges in normal captioning. A text-based image intuitively contains abundant and complex multimodal relational content, that is, image details can be described diversely from multiview rather than a single caption. Certainly, we can introduce additional paired training data to show the diversity of images' descriptions, this process is labor-intensive and time-consuming for TextCap pair annotations with extra texts. Based on the insight mentioned above, we investigate how to generate diverse captions that focus on different image parts using an unpaired training paradigm. We propose the Multimodal relAtional Graph adversarIal inferenCe (MAGIC) framework for diverse and unpaired TextCap. This framework can adaptively construct multiple multimodal relational graphs of images and model complex relationships among graphs to represent descriptive diversity. Moreover, a cascaded generative adversarial network is developed from modeled graphs to infer the unpaired caption generation in image-sentence feature alignment and linguistic coherence levels. We validate the effectiveness of MAGIC in generating diverse captions from different relational information items of an image. Experimental results show that MAGIC can generate very promising outcomes without using any image-caption training pairs.