 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOSS: Bottom-up Cross-modal Semantic Composition with Hybrid Counterfactual Training for Robust Content-based Image Retrieval
Paper and Code
Jul 09, 2022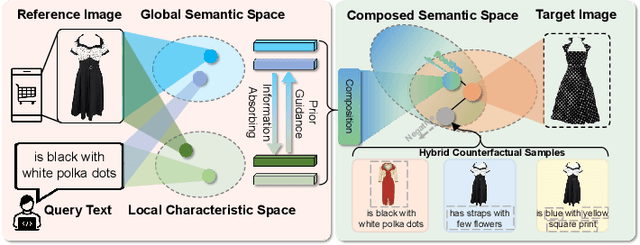

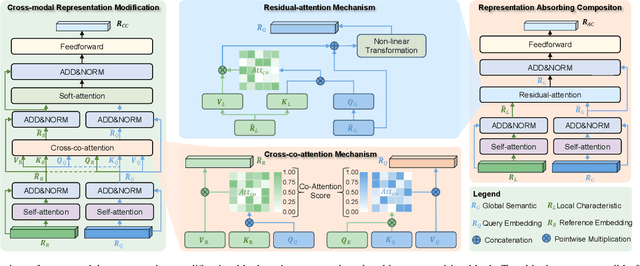

Content-Based Image Retrieval (CIR) aims to search for a target image by concurrently comprehending the composition of an example image and a complementary text, which potentially impacts a wide variety of real-world applications, such as internet search and fashion retrieval. In this scenario, the input image serves as an intuitive context and background for the search, while the corresponding language expressly requests new traits on how specific characteristics of the query image should be modified in order to get the intended target image. This task is challenging since it necessitates learning and understanding the composite image-text representation by incorporating cross-granular semantic updates. In this paper, we tackle this task by a novel \underline{\textbf{B}}ottom-up cr\underline{\textbf{O}}ss-modal \underline{\textbf{S}}emantic compo\underline{\textbf{S}}ition (\textbf{BOSS}) with Hybrid Counterfactual Training framework, which sheds new light on the CIR task by studying it from two previously overlooked perspectives: \emph{implicitly bottom-up composition of visiolinguistic representation} and \emph{explicitly fine-grained correspondence of query-target construction}. On the one hand, we leverage the implicit interaction and composition of cross-modal embeddings from the bottom local characteristics to the top global semantics, preserving and transforming the visual representation conditioned on language semantics in several continuous steps for effective target image search. On the other hand, we devise a hybrid counterfactual training strategy that can reduce the model's ambiguity for similar queries.