 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2Report: A Cognitive Deep Research Agent for Expert-Level Commercial Report Synthesis
Jan 08, 2026Synthesizing informative commercial reports from massive and noisy web sources is critical for high-stakes business decisions. Although current deep research agents achieve notable progress, their reports still remain limited in terms of quality, reliability, and coverage. In this work, we propose Mind2Report, a cognitive deep research agent that emulates the commercial analyst to synthesize expert-level reports. Specifically, it first probes fine-grained intent, then searches web sources and records distilled information on the fly, and subsequently iteratively synthesizes the report. We design Mind2Report as a training-free agentic workflow that augments general large language models (LLMs) with dynamic memory to support these long-form cognitive processes. To rigorously evaluate Mind2Report, we further construct QRC-Eval comprising 200 real-world commercial tasks and establish a holistic evaluation strategy to assess report quality, reliability, and coverage. Experiments demonstrate that Mind2Report outperforms leading baselines, including OpenAI and Gemini deep research agents. Although this is a preliminary study, we expect it to serve as a foundation for advancing the future design of commercial deep research agents. Our code and data are available at https://github.com/Melmaphother/Mind2Report.
StarDojo: Benchmarking Open-Ended Behaviors of Agentic Multimodal LLMs in Production-Living Simulations with Stardew Valley
Jul 10, 2025Autonomous agents navigating human society must master both production activities and social interactions, yet existing benchmarks rarely evaluate these skills simultaneously. To bridge this gap, we introduce StarDojo, a novel benchmark based on Stardew Valley, designed to assess AI agents in open-ended production-living simulations. In StarDojo, agents are tasked to perform essential livelihood activities such as farming and crafting, while simultaneously engaging in social interactions to establish relationships within a vibrant community. StarDojo features 1,000 meticulously curated tasks across five key domains: farming, crafting, exploration, combat, and social interactions. Additionally, we provide a compact subset of 100 representative tasks for efficient model evaluation. The benchmark offers a unified, user-friendly interface that eliminates the need for keyboard and mouse control, supports all major operating systems, and enables the parallel execution of multiple environment instances, making it particularly well-suited for evaluating the most capable foundation agents, powered by multimodal large language models (MLLMs). Extensive evaluations of state-of-the-art MLLMs agents demonstrate substantial limitations, with the best-performing model, GPT-4.1, achieving only a 12.7% success rate, primarily due to challenges in visual understanding, multimodal reasoning and low-level manipulation. As a user-friendly environment and benchmark, StarDojo aims to facilitate further research towards robust, open-ended agents in complex production-living environments.
POCO: Scalable Neural Forecasting through Population Conditioning
Jun 17, 2025Predicting future neural activity is a core challenge in modeling brain dynamics, with applications ranging from scientific investigation to closed-loop neurotechnology. While recent models of population activity emphasize interpretability and behavioral decoding, neural forecasting-particularly across multi-session, spontaneous recordings-remains underexplored. We introduce POCO, a unified forecasting model that combines a lightweight univariate forecaster with a population-level encoder to capture both neuron-specific and brain-wide dynamics. Trained across five calcium imaging datasets spanning zebrafish, mice, and C. elegans, POCO achieves state-of-the-art accuracy at cellular resolution in spontaneous behaviors. After pre-training, POCO rapidly adapts to new recordings with minimal fine-tuning. Notably, POCO's learned unit embeddings recover biologically meaningful structure-such as brain region clustering-without any anatomical labels. Our comprehensive analysis reveals several key factors influencing performance, including context length, session diversity, and preprocessing. Together, these results position POCO as a scalable and adaptable approach for cross-session neural forecasting and offer actionable insights for future model design. By enabling accurate, generalizable forecasting models of neural dynamics across individuals and species, POCO lays the groundwork for adaptive neurotechnologies and large-scale efforts for neural foundation models.
Efficient Multi-Instance Generation with Janus-Pro-Dirven Prompt Parsing
Mar 27, 2025Recent advances in text-guided diffusion models have revolutionized conditional image generation, yet they struggle to synthesize complex scenes with multiple objects due to imprecise spatial grounding and limited scalability. We address these challenges through two key modules: 1) Janus-Pro-driven Prompt Parsing, a prompt-layout parsing module that bridges text understanding and layout generation via a compact 1B-parameter architecture, and 2) MIGLoRA, a parameter-efficient plug-in integrating Low-Rank Adaptation (LoRA) into UNet (SD1.5) and DiT (SD3) backbones. MIGLoRA is capable of preserving the base model's parameters and ensuring plug-and-play adaptability, minimizing architectural intrusion while enabling efficient fine-tuning. To support a comprehensive evaluation, we create DescripBox and DescripBox-1024, benchmarks that span diverse scenes and resolutions. The proposed method achieves state-of-the-art performance on COCO and LVIS benchmarks while maintaining parameter efficiency, demonstrating superior layout fidelity and scalability for open-world synthesis.
A Kronecker product accelerated efficient sparse Gaussian Process (E-SGP) for flow emulation
Dec 13, 2023



In this paper, we introduce an efficient sparse Gaussian process (E-SGP) for the surrogate modelling of fluid mechanics. This novel Bayesian machine learning algorithm allows efficient model training using databases of different structures. It is a further development of the approximated sparse GP algorithm, combining the concept of efficient GP (E-GP) and variational energy free sparse Gaussian process (VEF-SGP). The developed E-SGP approach exploits the arbitrariness of inducing points and the monotonically increasing nature of the objective function with respect to the number of inducing points in VEF-SGP. By specifying the inducing points on the orthogonal grid/input subspace and using the Kronecker product, E-SGP significantly improves computational efficiency without imposing any constraints on the covariance matrix or increasing the number of parameters that need to be optimised during training. The E-SGP algorithm developed in this paper outperforms E-GP not only in scalability but also in model quality in terms of mean standardized logarithmic loss (MSLL). The computational complexity of E-GP suffers from the cubic growth regarding the growing structured training database. However, E-SGP maintains computational efficiency whilst the resolution of the model, (i.e., the number of inducing points) remains fixed. The examples show that E-SGP produces more accurate predictions in comparison with E-GP when the model resolutions are similar in both. E-GP benefits from more training data but comes with higher computational demands, while E-SGP achieves a comparable level of accuracy but is more computationally efficient, making E-SGP a potentially preferable choice for fluid mechanic problems. Furthermore, E-SGP can produce more reasonable estimates of model uncertainty, whilst E-GP is more likely to produce over-confident predictions.
Hebbian and Gradient-based Plasticity Enables Robust Memory and Rapid Learning in RNNs
Feb 07, 2023



Rapidly learning from ongoing experiences and remembering past events with a flexible memory system are two core capacities of biological intelligence. While the underlying neural mechanisms are not fully understood, various evidence supports that synaptic plasticity plays a critical role in memory formation and fast learning. Inspired by these results, we equip Recurrent Neural Networks (RNNs) with plasticity rules to enable them to adapt their parameters according to ongoing experiences. In addition to the traditional local Hebbian plasticity, we propose a global, gradient-based plasticity rule, which allows the model to evolve towards its self-determined target. Our models show promising results on sequential and associative memory tasks, illustrating their ability to robustly form and retain memories. In the meantime, these models can cope with many challenging few-shot learning problems. Comparing different plasticity rules under the same framework shows that Hebbian plasticity is well-suited for several memory and associative learning tasks; however, it is outperformed by gradient-based plasticity on few-shot regression tasks which require the model to infer the underlying mapping. Code is available at https://github.com/yuvenduan/PlasticRNNs.
Collaborative Intelligence Orchestration: Inconsistency-Based Fusion of Semi-Supervised Learning and Active Learning
Jun 07, 2022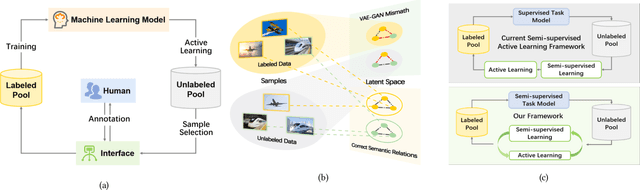



While annotating decent amounts of data to satisfy sophisticated learning models can be cost-prohibitive for many real-world applications. Active learning (AL) and semi-supervised learning (SSL) are two effective, but often isolated, means to alleviate the data-hungry problem. Some recent studies explored the potential of combining AL and SSL to better probe the unlabeled data. However, almost all these contemporary SSL-AL works use a simple combination strategy, ignoring SSL and AL's inherent relation. Further, other methods suffer from high computational costs when dealing with large-scale, high-dimensional datasets. Motivated by the industry practice of labeling data, we propose an innovative Inconsistency-based virtual aDvErsarial Active Learning (IDEAL) algorithm to further investigate SSL-AL's potential superiority and achieve mutual enhancement of AL and SSL, i.e., SSL propagates label information to unlabeled samples and provides smoothed embeddings for AL, while AL excludes samples with inconsistent predictions and considerable uncertainty for SSL. We estimate unlabeled samples' inconsistency by augmentation strategies of different granularities, including fine-grained continuous perturbation exploration and coarse-grained data transformations. Extensive experiments, in both text and image domains, validate the effectiveness of the proposed algorithm, comparing it against state-of-the-art baselines. Two real-world case studies visualize the practical industrial value of applying and deploying the proposed data sampling algorithm.
Fixed Inducing Points Online Bayesian Calibration for Computer Models with an Application to a Scale-Resolving CFD Simulation
Sep 15, 2020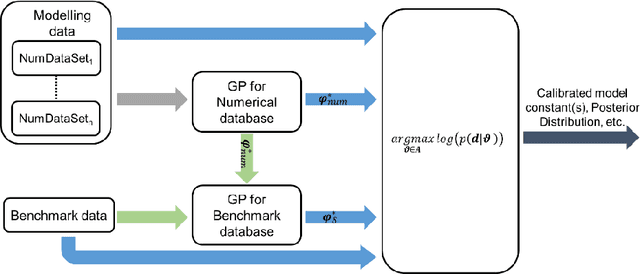
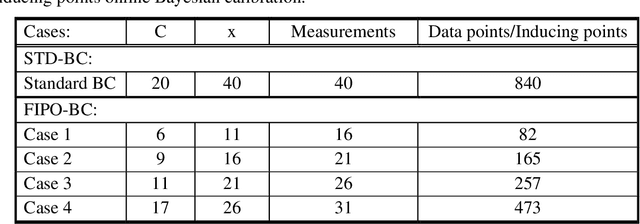
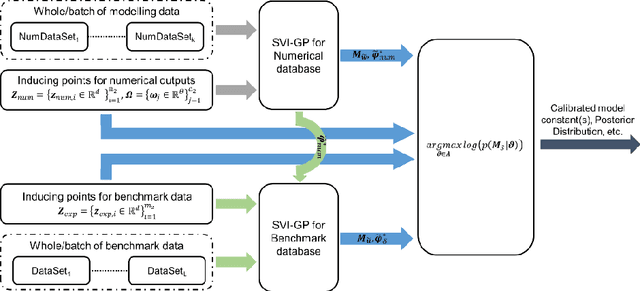
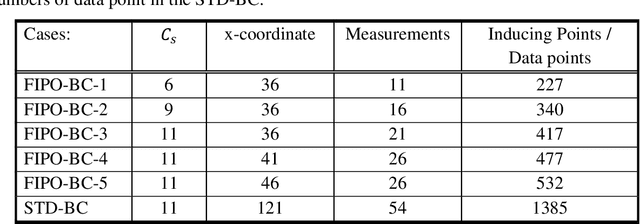
This paper proposes a novel fixed inducing points online Bayesian calibration (FIPO-BC) algorithm to efficiently learn the model parameters using a benchmark database. The standard Bayesian calibration (STD-BC) algorithm provides a statistical method to calibrate the parameters of computationally expensive models. However, the STD-BC algorithm scales very badly with the number of data points and lacks online learning capability. The proposed FIPO-BC algorithm greatly improves the computational efficiency and enables the online calibration by executing the calibration on a set of predefined inducing points. To demonstrate the procedure of the FIPO-BC algorithm, two tests are performed, finding the optimal value and exploring the posterior distribution of 1) the parameter in a simple function, and 2) the high-wave number damping factor in a scale-resolving turbulence model (SAS-SST). The results (such as the calibrated model parameter and its posterior distribution) of FIPO-BC with different inducing points are compared to those of STD-BC. It is found that FIPO-BC and STD-BC can provide very similar results, once the predefined set of inducing point in FIPO-BC is sufficiently fine. But, the FIPO-BC algorithm is at least ten times faster than the STD-BC algorithm. Meanwhile, the online feature of the FIPO-BC allows continuous updating of the calibration outputs and potentially reduces the workload on generating the database.
Pre-train and Plug-in: Flexible Conditional Text Generation with Variational Auto-Encoders
Nov 10, 2019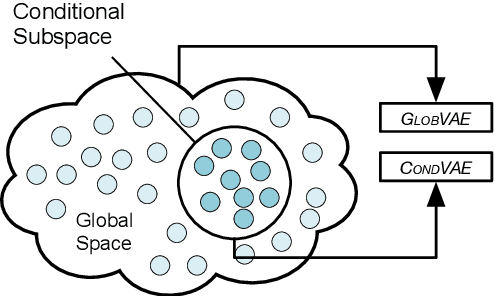



Current neural Natural Language Generation (NLG) models cannot handle emerging conditions due to their joint end-to-end learning fashion. When the need for generating text under a new condition emerges, these techniques require not only sufficiently supplementary labeled data but also a full re-training of the existing model. In this paper, we present a new framework named Hierarchical Neural Auto-Encoder (HAE) toward flexible conditional text generation. HAE decouples the text generation module from the condition representation module to allow "one-to-many" conditional generation. When a fresh condition emerges, only a lightweight network needs to be trained and works as a plug-in for HAE, which is efficient and desirable for real-world applications. Extensive experiments demonstrate the superiority of HAE against the existing alternatives with much less training time and fewer model parameters.