 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Electro-communication and Electro-sensing in Weakly Electric Fish using Multi-Agent Deep Reinforcement Learning
Nov 11, 2025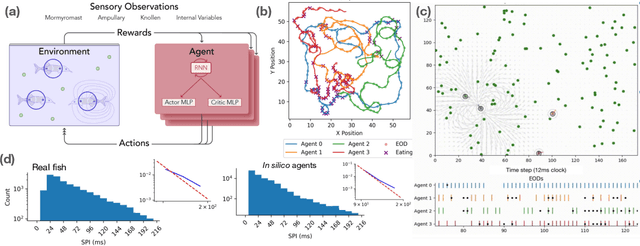
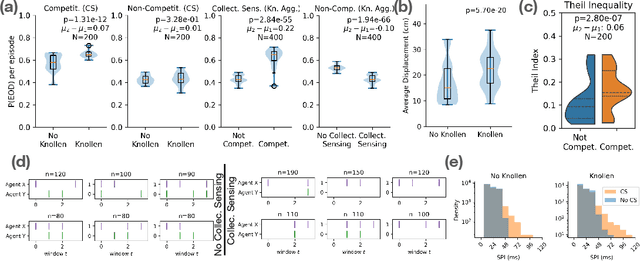
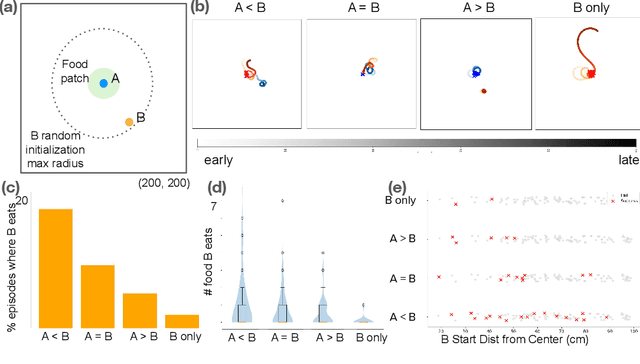
Weakly electric fish, like Gnathonemus petersii, use a remarkable electrical modality for active sensing and communication, but studying their rich electrosensing and electrocommunication behavior and associated neural activity in naturalistic settings remains experimentally challenging. Here, we present a novel biologically-inspired computational framework to study these behaviors, where recurrent neural network (RNN) based artificial agents trained via multi-agent reinforcement learning (MARL) learn to modulate their electric organ discharges (EODs) and movement patterns to collectively forage in virtual environments. Trained agents demonstrate several emergent features consistent with real fish collectives, including heavy tailed EOD interval distributions, environmental context dependent shifts in EOD interval distributions, and social interaction patterns like freeloading, where agents reduce their EOD rates while benefiting from neighboring agents' active sensing. A minimal two-fish assay further isolates the role of electro-communication, showing that access to conspecific EODs and relative dominance jointly shape foraging success. Notably, these behaviors emerge through evolution-inspired rewards for individual fitness and emergent inter-agent interactions, rather than through rewarding agents explicitly for social interactions. Our work has broad implications for the neuroethology of weakly electric fish, as well as other social, communicating animals in which extensive recordings from multiple individuals, and thus traditional data-driven modeling, are infeasible.
Gradient Descent as Loss Landscape Navigation: a Normative Framework for Deriving Learning Rules
Oct 30, 2025Learning rules -- prescriptions for updating model parameters to improve performance -- are typically assumed rather than derived. Why do some learning rules work better than others, and under what assumptions can a given rule be considered optimal? We propose a theoretical framework that casts learning rules as policies for navigating (partially observable) loss landscapes, and identifies optimal rules as solutions to an associated optimal control problem. A range of well-known rules emerge naturally within this framework under different assumptions: gradient descent from short-horizon optimization, momentum from longer-horizon planning, natural gradients from accounting for parameter space geometry, non-gradient rules from partial controllability, and adaptive optimizers like Adam from online Bayesian inference of loss landscape shape. We further show that continual learning strategies like weight resetting can be understood as optimal responses to task uncertainty. By unifying these phenomena under a single objective, our framework clarifies the computational structure of learning and offers a principled foundation for designing adaptive algorithms.
InputDSA: Demixing then Comparing Recurrent and Externally Driven Dynamics
Oct 29, 2025In control problems and basic scientific modeling, it is important to compare observations with dynamical simulations. For example, comparing two neural systems can shed light on the nature of emergent computations in the brain and deep neural networks. Recently, Ostrow et al. (2023) introduced Dynamical Similarity Analysis (DSA), a method to measure the similarity of two systems based on their recurrent dynamics rather than geometry or topology. However, DSA does not consider how inputs affect the dynamics, meaning that two similar systems, if driven differently, may be classified as different. Because real-world dynamical systems are rarely autonomous, it is important to account for the effects of input drive. To this end, we introduce a novel metric for comparing both intrinsic (recurrent) and input-driven dynamics, called InputDSA (iDSA). InputDSA extends the DSA framework by estimating and comparing both input and intrinsic dynamic operators using a variant of Dynamic Mode Decomposition with control (DMDc) based on subspace identification. We demonstrate that InputDSA can successfully compare partially observed, input-driven systems from noisy data. We show that when the true inputs are unknown, surrogate inputs can be substituted without a major deterioration in similarity estimates. We apply InputDSA on Recurrent Neural Networks (RNNs) trained with Deep Reinforcement Learning, identifying that high-performing networks are dynamically similar to one another, while low-performing networks are more diverse. Lastly, we apply InputDSA to neural data recorded from rats performing a cognitive task, demonstrating that it identifies a transition from input-driven evidence accumulation to intrinsically-driven decision-making. Our work demonstrates that InputDSA is a robust and efficient method for comparing intrinsic dynamics and the effect of external input on dynamical systems.
From memories to maps: Mechanisms of in context reinforcement learning in transformers
Jun 24, 2025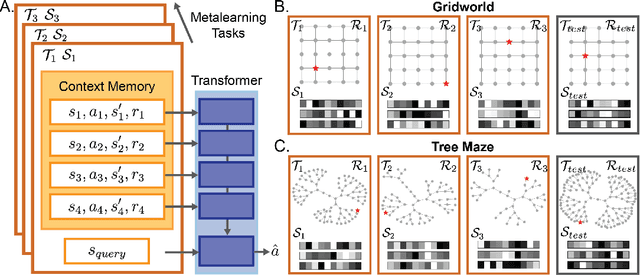



Humans and animals show remarkable learning efficiency, adapting to new environments with minimal experience. This capability is not well captured by standard reinforcement learning algorithms that rely on incremental value updates. Rapid adaptation likely depends on episodic memory -- the ability to retrieve specific past experiences to guide decisions in novel contexts. Transformers provide a useful setting for studying these questions because of their ability to learn rapidly in-context and because their key-value architecture resembles episodic memory systems in the brain. We train a transformer to in-context reinforcement learn in a distribution of planning tasks inspired by rodent behavior. We then characterize the learning algorithms that emerge in the model. We first find that representation learning is supported by in-context structure learning and cross-context alignment, where representations are aligned across environments with different sensory stimuli. We next demonstrate that the reinforcement learning strategies developed by the model are not interpretable as standard model-free or model-based planning. Instead, we show that in-context reinforcement learning is supported by caching intermediate computations within the model's memory tokens, which are then accessed at decision time. Overall, we find that memory may serve as a computational resource, storing both raw experience and cached computations to support flexible behavior. Furthermore, the representations developed in the model resemble computations associated with the hippocampal-entorhinal system in the brain, suggesting that our findings may be relevant for natural cognition. Taken together, our work offers a mechanistic hypothesis for the rapid adaptation that underlies in-context learning in artificial and natural settings.
POCO: Scalable Neural Forecasting through Population Conditioning
Jun 17, 2025Predicting future neural activity is a core challenge in modeling brain dynamics, with applications ranging from scientific investigation to closed-loop neurotechnology. While recent models of population activity emphasize interpretability and behavioral decoding, neural forecasting-particularly across multi-session, spontaneous recordings-remains underexplored. We introduce POCO, a unified forecasting model that combines a lightweight univariate forecaster with a population-level encoder to capture both neuron-specific and brain-wide dynamics. Trained across five calcium imaging datasets spanning zebrafish, mice, and C. elegans, POCO achieves state-of-the-art accuracy at cellular resolution in spontaneous behaviors. After pre-training, POCO rapidly adapts to new recordings with minimal fine-tuning. Notably, POCO's learned unit embeddings recover biologically meaningful structure-such as brain region clustering-without any anatomical labels. Our comprehensive analysis reveals several key factors influencing performance, including context length, session diversity, and preprocessing. Together, these results position POCO as a scalable and adaptable approach for cross-session neural forecasting and offer actionable insights for future model design. By enabling accurate, generalizable forecasting models of neural dynamics across individuals and species, POCO lays the groundwork for adaptive neurotechnologies and large-scale efforts for neural foundation models.
Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments
Jun 08, 2025
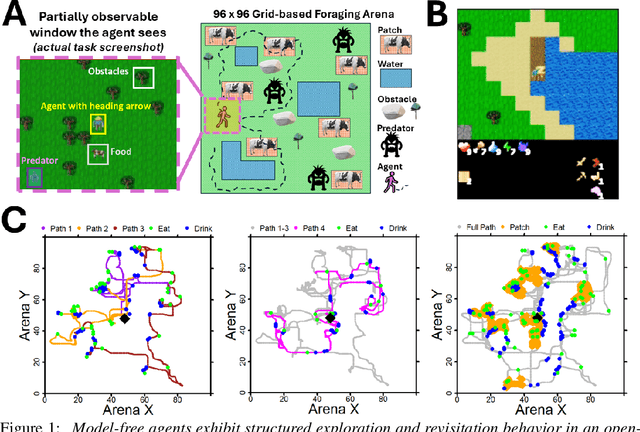


Understanding the behavior of deep reinforcement learning (DRL) agents -- particularly as task and agent sophistication increase -- requires more than simple comparison of reward curves, yet standard methods for behavioral analysis remain underdeveloped in DRL. We apply tools from neuroscience and ethology to study DRL agents in a novel, complex, partially observable environment, ForageWorld, designed to capture key aspects of real-world animal foraging -- including sparse, depleting resource patches, predator threats, and spatially extended arenas. We use this environment as a platform for applying joint behavioral and neural analysis to agents, revealing detailed, quantitatively grounded insights into agent strategies, memory, and planning. Contrary to common assumptions, we find that model-free RNN-based DRL agents can exhibit structured, planning-like behavior purely through emergent dynamics -- without requiring explicit memory modules or world models. Our results show that studying DRL agents like animals -- analyzing them with neuroethology-inspired tools that reveal structure in both behavior and neural dynamics -- uncovers rich structure in their learning dynamics that would otherwise remain invisible. We distill these tools into a general analysis framework linking core behavioral and representational features to diagnostic methods, which can be reused for a wide range of tasks and agents. As agents grow more complex and autonomous, bridging neuroscience, cognitive science, and AI will be essential -- not just for understanding their behavior, but for ensuring safe alignment and maximizing desirable behaviors that are hard to measure via reward. We show how this can be done by drawing on lessons from how biological intelligence is studied.
Military AI Needs Technically-Informed Regulation to Safeguard AI Research and its Applications
May 23, 2025


Military weapon systems and command-and-control infrastructure augmented by artificial intelligence (AI) have seen rapid development and deployment in recent years. However, the sociotechnical impacts of AI on combat systems, military decision-making, and the norms of warfare have been understudied. We focus on a specific subset of lethal autonomous weapon systems (LAWS) that use AI for targeting or battlefield decisions. We refer to this subset as AI-powered lethal autonomous weapon systems (AI-LAWS) and argue that they introduce novel risks -- including unanticipated escalation, poor reliability in unfamiliar environments, and erosion of human oversight -- all of which threaten both military effectiveness and the openness of AI research. These risks cannot be addressed by high-level policy alone; effective regulation must be grounded in the technical behavior of AI models. We argue that AI researchers must be involved throughout the regulatory lifecycle. Thus, we propose a clear, behavior-based definition of AI-LAWS -- systems that introduce unique risks through their use of modern AI -- as a foundation for technically grounded regulation, given that existing frameworks do not distinguish them from conventional LAWS. Using this definition, we propose several technically-informed policy directions and invite greater participation from the AI research community in military AI policy discussions.
Measuring and Controlling Solution Degeneracy across Task-Trained Recurrent Neural Networks
Oct 04, 2024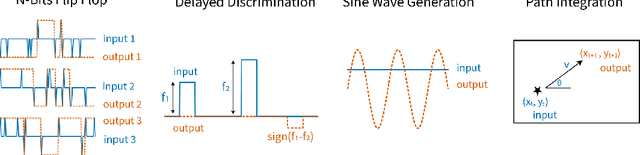

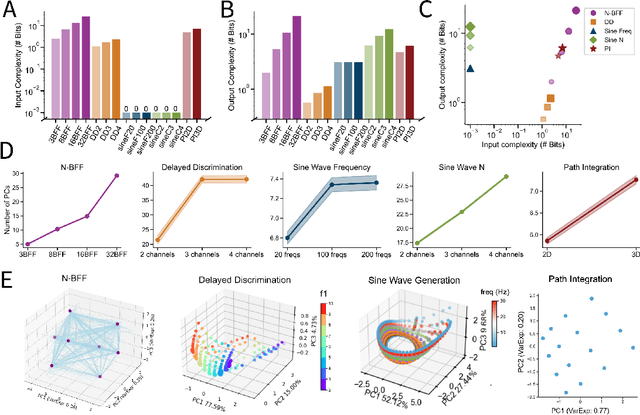

Task-trained recurrent neural networks (RNNs) are versatile models of dynamical processes widely used in machine learning and neuroscience. While RNNs are easily trained to perform a wide range of tasks, the nature and extent of the degeneracy in the resultant solutions (i.e., the variability across trained RNNs) remain poorly understood. Here, we provide a unified framework for analyzing degeneracy across three levels: behavior, neural dynamics, and weight space. We analyzed RNNs trained on diverse tasks across machine learning and neuroscience domains, including N-bit flip-flop, sine wave generation, delayed discrimination, and path integration. Our key finding is that the variability across RNN solutions, quantified on the basis of neural dynamics and trained weights, depends primarily on network capacity and task characteristics such as complexity. We introduce information-theoretic measures to quantify task complexity and demonstrate that increasing task complexity consistently reduces degeneracy in neural dynamics and generalization behavior while increasing degeneracy in weight space. These relationships hold across diverse tasks and can be used to control the degeneracy of the solution space of task-trained RNNs. Furthermore, we provide several strategies to control solution degeneracy, enabling task-trained RNNs to learn more consistent or diverse solutions as needed. We envision that these insights will lead to more reliable machine learning models and could inspire strategies to better understand and control degeneracy observed in neuroscience experiments.
AI-Powered Autonomous Weapons Risk Geopolitical Instability and Threaten AI Research
May 03, 2024

The recent embrace of machine learning (ML) in the development of autonomous weapons systems (AWS) creates serious risks to geopolitical stability and the free exchange of ideas in AI research. This topic has received comparatively little attention of late compared to risks stemming from superintelligent artificial general intelligence (AGI), but requires fewer assumptions about the course of technological development and is thus a nearer-future issue. ML is already enabling the substitution of AWS for human soldiers in many battlefield roles, reducing the upfront human cost, and thus political cost, of waging offensive war. In the case of peer adversaries, this increases the likelihood of "low intensity" conflicts which risk escalation to broader warfare. In the case of non-peer adversaries, it reduces the domestic blowback to wars of aggression. This effect can occur regardless of other ethical issues around the use of military AI such as the risk of civilian casualties, and does not require any superhuman AI capabilities. Further, the military value of AWS raises the specter of an AI-powered arms race and the misguided imposition of national security restrictions on AI research. Our goal in this paper is to raise awareness among the public and ML researchers on the near-future risks posed by full or near-full autonomy in military technology, and we provide regulatory suggestions to mitigate these risks. We call upon AI policy experts and the defense AI community in particular to embrace transparency and caution in their development and deployment of AWS to avoid the negative effects on global stability and AI research that we highlight here.
Efficient and robust multi-task learning in the brain with modular task primitives
May 28, 2021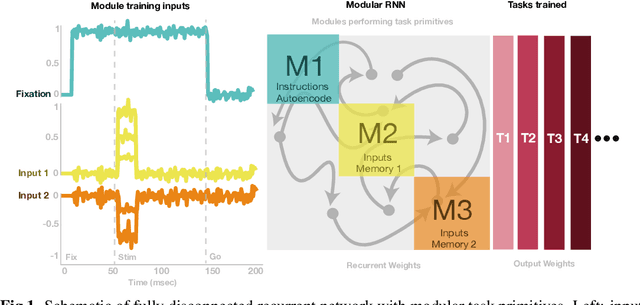

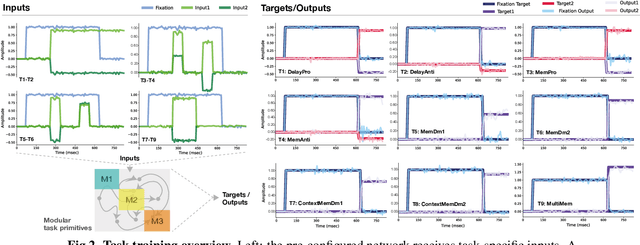

In a real-world setting biological agents do not have infinite resources to learn new things. It is thus useful to recycle previously acquired knowledge in a way that allows for faster, less resource-intensive acquisition of multiple new skills. Neural networks in the brain are likely not entirely re-trained with new tasks, but how they leverage existing computations to learn new tasks is not well understood. In this work, we study this question in artificial neural networks trained on commonly used neuroscience paradigms. Building on recent work from the multi-task learning literature, we propose two ingredients: (1) network modularity, and (2) learning task primitives. Together, these ingredients form inductive biases we call structural and functional, respectively. Using a corpus of nine different tasks, we show that a modular network endowed with task primitives allows for learning multiple tasks well while keeping parameter counts, and updates, low. We also show that the skills acquired with our approach are more robust to a broad range of perturbations compared to those acquired with other multi-task learning strategies. This work offers a new perspective on achieving efficient multi-task learning in the brain, and makes predictions for novel neuroscience experiments in which targeted perturbations are employed to explore solution spaces.