 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments
Jun 08, 2025
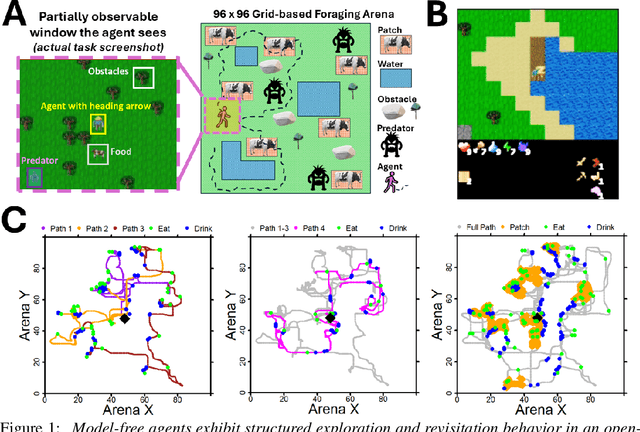


Understanding the behavior of deep reinforcement learning (DRL) agents -- particularly as task and agent sophistication increase -- requires more than simple comparison of reward curves, yet standard methods for behavioral analysis remain underdeveloped in DRL. We apply tools from neuroscience and ethology to study DRL agents in a novel, complex, partially observable environment, ForageWorld, designed to capture key aspects of real-world animal foraging -- including sparse, depleting resource patches, predator threats, and spatially extended arenas. We use this environment as a platform for applying joint behavioral and neural analysis to agents, revealing detailed, quantitatively grounded insights into agent strategies, memory, and planning. Contrary to common assumptions, we find that model-free RNN-based DRL agents can exhibit structured, planning-like behavior purely through emergent dynamics -- without requiring explicit memory modules or world models. Our results show that studying DRL agents like animals -- analyzing them with neuroethology-inspired tools that reveal structure in both behavior and neural dynamics -- uncovers rich structure in their learning dynamics that would otherwise remain invisible. We distill these tools into a general analysis framework linking core behavioral and representational features to diagnostic methods, which can be reused for a wide range of tasks and agents. As agents grow more complex and autonomous, bridging neuroscience, cognitive science, and AI will be essential -- not just for understanding their behavior, but for ensuring safe alignment and maximizing desirable behaviors that are hard to measure via reward. We show how this can be done by drawing on lessons from how biological intelligence is studied.
Military AI Needs Technically-Informed Regulation to Safeguard AI Research and its Applications
May 23, 2025


Military weapon systems and command-and-control infrastructure augmented by artificial intelligence (AI) have seen rapid development and deployment in recent years. However, the sociotechnical impacts of AI on combat systems, military decision-making, and the norms of warfare have been understudied. We focus on a specific subset of lethal autonomous weapon systems (LAWS) that use AI for targeting or battlefield decisions. We refer to this subset as AI-powered lethal autonomous weapon systems (AI-LAWS) and argue that they introduce novel risks -- including unanticipated escalation, poor reliability in unfamiliar environments, and erosion of human oversight -- all of which threaten both military effectiveness and the openness of AI research. These risks cannot be addressed by high-level policy alone; effective regulation must be grounded in the technical behavior of AI models. We argue that AI researchers must be involved throughout the regulatory lifecycle. Thus, we propose a clear, behavior-based definition of AI-LAWS -- systems that introduce unique risks through their use of modern AI -- as a foundation for technically grounded regulation, given that existing frameworks do not distinguish them from conventional LAWS. Using this definition, we propose several technically-informed policy directions and invite greater participation from the AI research community in military AI policy discussions.
AI-Powered Autonomous Weapons Risk Geopolitical Instability and Threaten AI Research
May 03, 2024

The recent embrace of machine learning (ML) in the development of autonomous weapons systems (AWS) creates serious risks to geopolitical stability and the free exchange of ideas in AI research. This topic has received comparatively little attention of late compared to risks stemming from superintelligent artificial general intelligence (AGI), but requires fewer assumptions about the course of technological development and is thus a nearer-future issue. ML is already enabling the substitution of AWS for human soldiers in many battlefield roles, reducing the upfront human cost, and thus political cost, of waging offensive war. In the case of peer adversaries, this increases the likelihood of "low intensity" conflicts which risk escalation to broader warfare. In the case of non-peer adversaries, it reduces the domestic blowback to wars of aggression. This effect can occur regardless of other ethical issues around the use of military AI such as the risk of civilian casualties, and does not require any superhuman AI capabilities. Further, the military value of AWS raises the specter of an AI-powered arms race and the misguided imposition of national security restrictions on AI research. Our goal in this paper is to raise awareness among the public and ML researchers on the near-future risks posed by full or near-full autonomy in military technology, and we provide regulatory suggestions to mitigate these risks. We call upon AI policy experts and the defense AI community in particular to embrace transparency and caution in their development and deployment of AWS to avoid the negative effects on global stability and AI research that we highlight here.
AuraSense: Robot Collision Avoidance by Full Surface Proximity Detection
Aug 10, 2021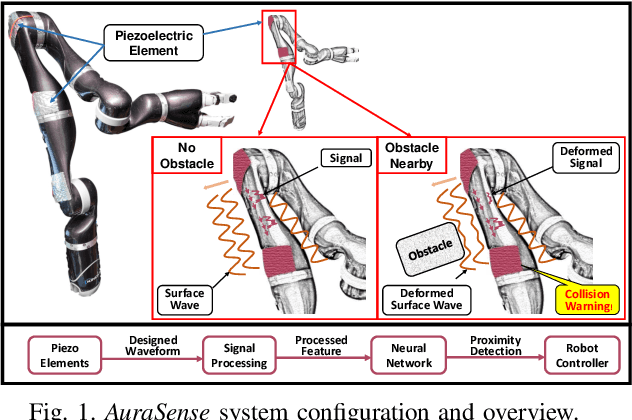
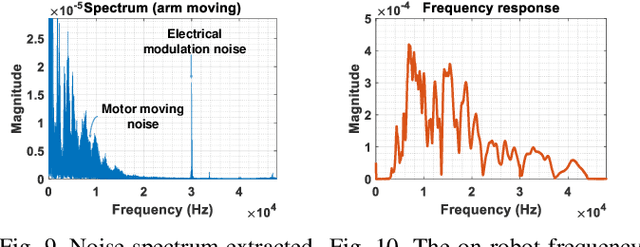
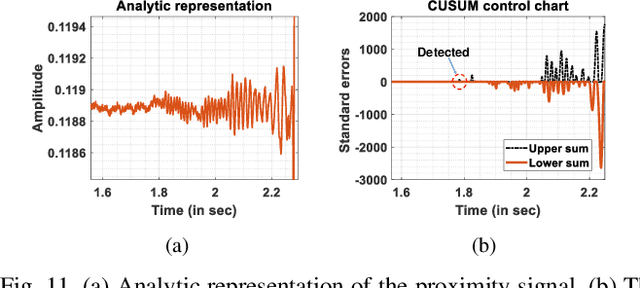
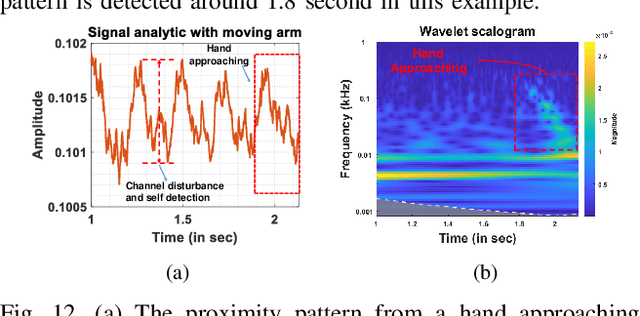
Perceiving obstacles and avoiding collisions is fundamental to the safe operation of a robot system, particularly when the robot must operate in highly dynamic human environments. Proximity detection using on-robot sensors can be used to avoid or mitigate impending collisions. However, existing proximity sensing methods are orientation and placement dependent, resulting in blind spots even with large numbers of sensors. In this paper, we introduce the phenomenon of the Leaky Surface Wave (LSW), a novel sensing modality, and present AuraSense, a proximity detection system using the LSW. AuraSense is the first system to realize no-dead-spot proximity sensing for robot arms. It requires only a single pair of piezoelectric transducers, and can easily be applied to off-the-shelf robots with minimal modifications. We further introduce a set of signal processing techniques and a lightweight neural network to address the unique challenges in using the LSW for proximity sensing. Finally, we demonstrate a prototype system consisting of a single piezoelectric element pair on a robot manipulator, which validates our design. We conducted several micro benchmark experiments and performed more than 2000 on-robot proximity detection trials with various potential robot arm materials, colliding objects, approach patterns, and robot movement patterns. AuraSense achieves 100% and 95.3% true positive proximity detection rates when the arm approaches static and mobile obstacles respectively, with a true negative rate over 99%, showing the real-world viability of this system.
Towards Practical Credit Assignment for Deep Reinforcement Learning
Jun 08, 2021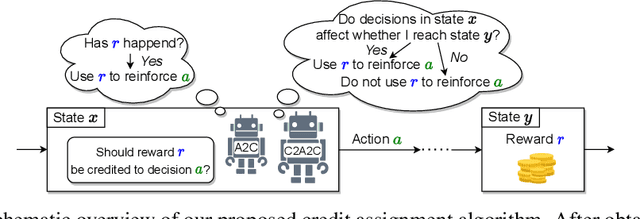
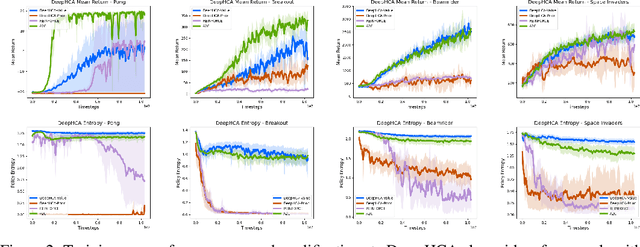
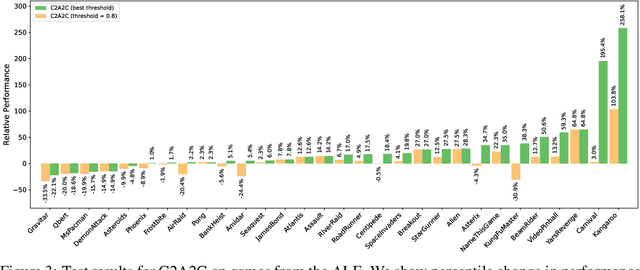
Credit assignment is a fundamental problem in reinforcement learning, the problem of measuring an action's influence on future rewards. Improvements in credit assignment methods have the potential to boost the performance of RL algorithms on many tasks, but thus far have not seen widespread adoption. Recently, a family of methods called Hindsight Credit Assignment (HCA) was proposed, which explicitly assign credit to actions in hindsight based on the probability of the action having led to an observed outcome. This approach is appealing as a means to more efficient data usage, but remains a largely theoretical idea applicable to a limited set of tabular RL tasks, and it is unclear how to extend HCA to Deep RL environments. In this work, we explore the use of HCA-style credit in a deep RL context. We first describe the limitations of existing HCA algorithms in deep RL, then propose several theoretically-justified modifications to overcome them. Based on this exploration, we present a new algorithm, Credit-Constrained Advantage Actor-Critic (C2A2C), which ignores policy updates for actions which don't affect future outcomes based on credit in hindsight, while updating the policy as normal for those that do. We find that C2A2C outperforms Advantage Actor-Critic (A2C) on the Arcade Learning Environment (ALE) benchmark, showing broad improvements over A2C and motivating further work on credit-constrained update rules for deep RL methods.
QXplore: Q-learning Exploration by Maximizing Temporal Difference Error
Jun 19, 2019

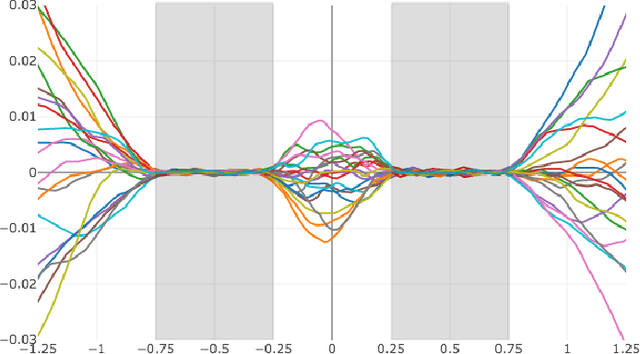

A major challenge in reinforcement learning for continuous state-action spaces is exploration, especially when reward landscapes are very sparse. Several recent methods provide an intrinsic motivation to explore by directly encouraging RL agents to seek novel states. A potential disadvantage of pure state novelty-seeking behavior is that unknown states are treated equally regardless of their potential for future reward. In this paper, we propose that the temporal difference error of predicting primary reward can serve as a secondary reward signal for exploration. This leads to novelty-seeking in the absence of primary reward, and at the same time accelerates exploration of reward-rich regions in sparse (but nonzero) reward landscapes compared to state novelty-seeking. This objective draws inspiration from dopaminergic pathways in the brain that influence animal behavior. We implement this idea with an adversarial method in which Q and Qx are the action-value functions for primary and secondary rewards, respectively. Secondary reward is given by the absolute value of the TD-error of Q. Training is off-policy, based on a replay buffer containing a mixture of trajectories induced by Q and Qx. We characterize performance on a suite of continuous control benchmark tasks against recent state of the art exploration methods and demonstrate comparable or better performance on all tasks, with much faster convergence for Q.
Q-Learning for Continuous Actions with Cross-Entropy Guided Policies
Mar 28, 2019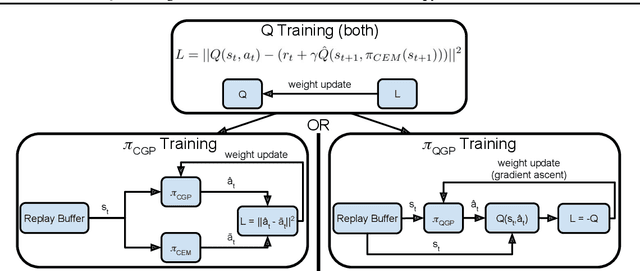

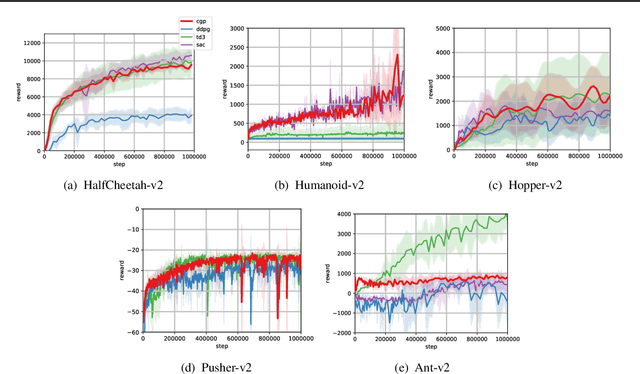
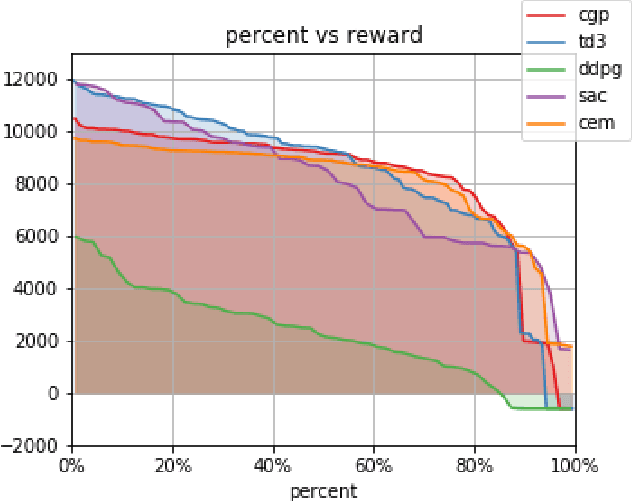
Off-Policy reinforcement learning (RL) is an important class of methods for many problem domains, such as robotics, where the cost of collecting data is high and on-policy methods are consequently intractable. Standard methods for applying Q-learning to continuous-valued action domains involve iteratively sampling the Q-function to find a good action (e.g. via hill-climbing), or by learning a policy network at the same time as the Q-function (e.g. DDPG). Both approaches make tradeoffs between stability, speed, and accuracy. We propose a novel approach, called Cross-Entropy Guided Policies, or CGP, that draws inspiration from both classes of techniques. CGP aims to combine the stability and performance of iterative sampling policies with the low computational cost of a policy network. Our approach trains the Q-function using iterative sampling with the Cross-Entropy Method (CEM), while training a policy network to imitate CEM's sampling behavior. We demonstrate that our method is more stable to train than state of the art policy network methods, while preserving equivalent inference time compute costs, and achieving competitive total reward on standard benchmarks.
Program Synthesis Through Reinforcement Learning Guided Tree Search
Jun 08, 2018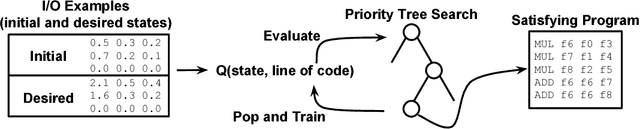

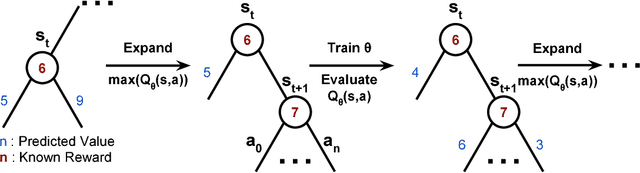

Program Synthesis is the task of generating a program from a provided specification. Traditionally, this has been treated as a search problem by the programming languages (PL) community and more recently as a supervised learning problem by the machine learning community. Here, we propose a third approach, representing the task of synthesizing a given program as a Markov decision process solvable via reinforcement learning(RL). From observations about the states of partial programs, we attempt to find a program that is optimal over a provided reward metric on pairs of programs and states. We instantiate this approach on a subset of the RISC-V assembly language operating on floating point numbers, and as an optimization inspired by search-based techniques from the PL community, we combine RL with a priority search tree. We evaluate this instantiation and demonstrate the effectiveness of our combined method compared to a variety of baselines, including a pure RL ablation and a state of the art Markov chain Monte Carlo search method on this task.