 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Learning for Continuous Actions with Cross-Entropy Guided Policies
Paper and Code
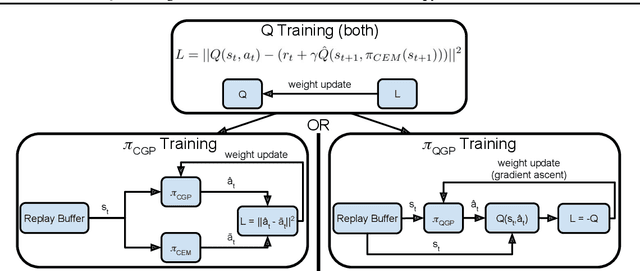

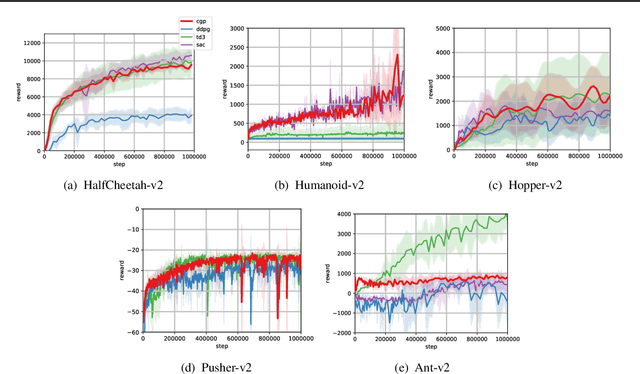
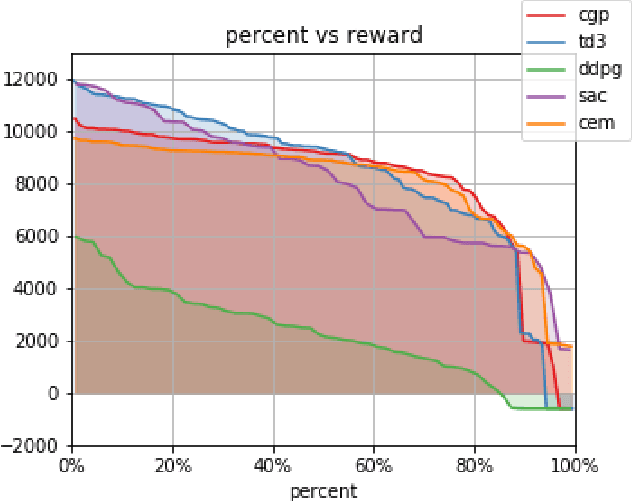
Off-Policy reinforcement learning (RL) is an important class of methods for many problem domains, such as robotics, where the cost of collecting data is high and on-policy methods are consequently intractable. Standard methods for applying Q-learning to continuous-valued action domains involve iteratively sampling the Q-function to find a good action (e.g. via hill-climbing), or by learning a policy network at the same time as the Q-function (e.g. DDPG). Both approaches make tradeoffs between stability, speed, and accuracy. We propose a novel approach, called Cross-Entropy Guided Policies, or CGP, that draws inspiration from both classes of techniques. CGP aims to combine the stability and performance of iterative sampling policies with the low computational cost of a policy network. Our approach trains the Q-function using iterative sampling with the Cross-Entropy Method (CEM), while training a policy network to imitate CEM's sampling behavior. We demonstrate that our method is more stable to train than state of the art policy network methods, while preserving equivalent inference time compute costs, and achieving competitive total reward on standard benchmarks.