 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStretched sinograms for limited-angle tomographic reconstruction with neural networks
Jun 16, 2023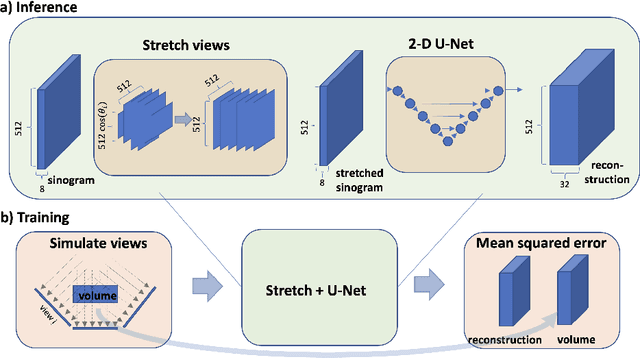
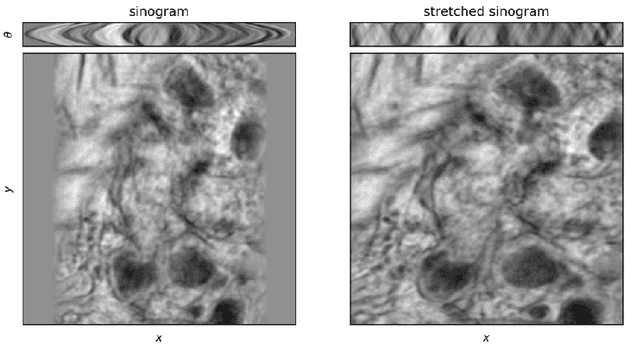
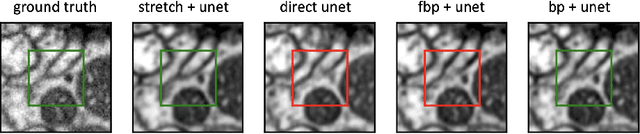

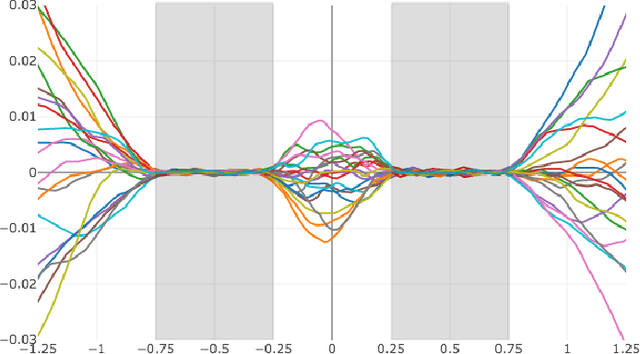
We present a direct method for limited angle tomographic reconstruction using convolutional networks. The key to our method is to first stretch every tilt view in the direction perpendicular to the tilt axis by the secant of the tilt angle. These stretched views are then fed into a 2-D U-Net which directly outputs the 3-D reconstruction. We train our networks by minimizing the mean squared error between the network's generated reconstruction and a ground truth 3-D volume. To demonstrate and evaluate our method, we synthesize tilt views from a 3-D image of fly brain tissue acquired with Focused Ion Beam Scanning Electron Microscopy. We compare our method to using a U-Net to directly reconstruct the unstretched tilt views and show that this simple stretching procedure leads to significantly better reconstructions. We also compare to using a network to clean up reconstructions generated by backprojection and filtered backprojection, and find that this simple stretching procedure also gives lower mean squared error on previously unseen images.
QXplore: Q-learning Exploration by Maximizing Temporal Difference Error
Jun 19, 2019


A major challenge in reinforcement learning for continuous state-action spaces is exploration, especially when reward landscapes are very sparse. Several recent methods provide an intrinsic motivation to explore by directly encouraging RL agents to seek novel states. A potential disadvantage of pure state novelty-seeking behavior is that unknown states are treated equally regardless of their potential for future reward. In this paper, we propose that the temporal difference error of predicting primary reward can serve as a secondary reward signal for exploration. This leads to novelty-seeking in the absence of primary reward, and at the same time accelerates exploration of reward-rich regions in sparse (but nonzero) reward landscapes compared to state novelty-seeking. This objective draws inspiration from dopaminergic pathways in the brain that influence animal behavior. We implement this idea with an adversarial method in which Q and Qx are the action-value functions for primary and secondary rewards, respectively. Secondary reward is given by the absolute value of the TD-error of Q. Training is off-policy, based on a replay buffer containing a mixture of trajectories induced by Q and Qx. We characterize performance on a suite of continuous control benchmark tasks against recent state of the art exploration methods and demonstrate comparable or better performance on all tasks, with much faster convergence for Q.
Q-Learning for Continuous Actions with Cross-Entropy Guided Policies
Mar 28, 2019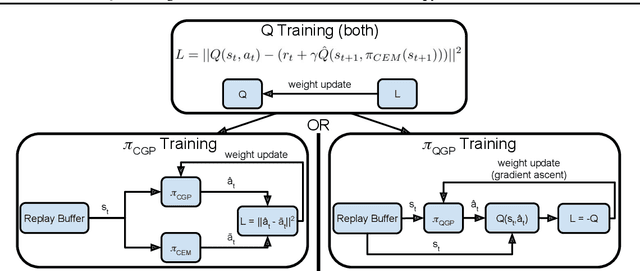

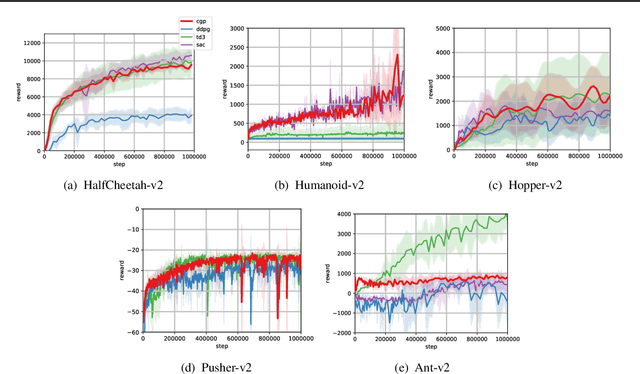
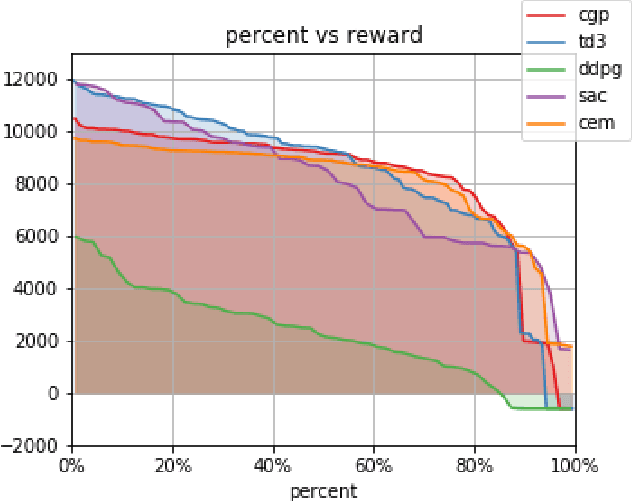
Off-Policy reinforcement learning (RL) is an important class of methods for many problem domains, such as robotics, where the cost of collecting data is high and on-policy methods are consequently intractable. Standard methods for applying Q-learning to continuous-valued action domains involve iteratively sampling the Q-function to find a good action (e.g. via hill-climbing), or by learning a policy network at the same time as the Q-function (e.g. DDPG). Both approaches make tradeoffs between stability, speed, and accuracy. We propose a novel approach, called Cross-Entropy Guided Policies, or CGP, that draws inspiration from both classes of techniques. CGP aims to combine the stability and performance of iterative sampling policies with the low computational cost of a policy network. Our approach trains the Q-function using iterative sampling with the Cross-Entropy Method (CEM), while training a policy network to imitate CEM's sampling behavior. We demonstrate that our method is more stable to train than state of the art policy network methods, while preserving equivalent inference time compute costs, and achieving competitive total reward on standard benchmarks.
Program Synthesis Through Reinforcement Learning Guided Tree Search
Jun 08, 2018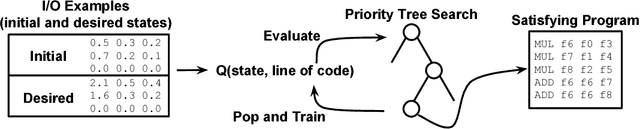

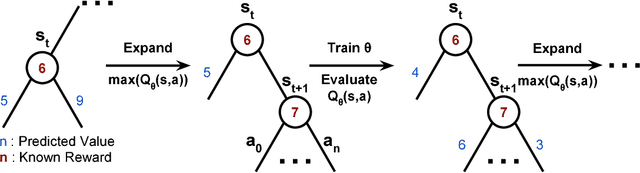

Program Synthesis is the task of generating a program from a provided specification. Traditionally, this has been treated as a search problem by the programming languages (PL) community and more recently as a supervised learning problem by the machine learning community. Here, we propose a third approach, representing the task of synthesizing a given program as a Markov decision process solvable via reinforcement learning(RL). From observations about the states of partial programs, we attempt to find a program that is optimal over a provided reward metric on pairs of programs and states. We instantiate this approach on a subset of the RISC-V assembly language operating on floating point numbers, and as an optimization inspired by search-based techniques from the PL community, we combine RL with a priority search tree. We evaluate this instantiation and demonstrate the effectiveness of our combined method compared to a variety of baselines, including a pure RL ablation and a state of the art Markov chain Monte Carlo search method on this task.