 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Credit Assignment for Deep Reinforcement Learning
Paper and Code
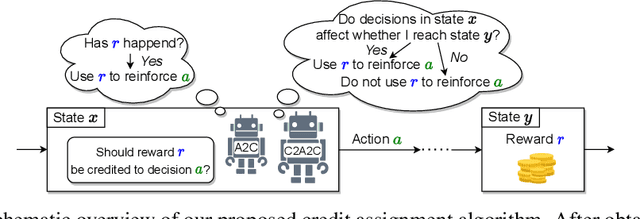
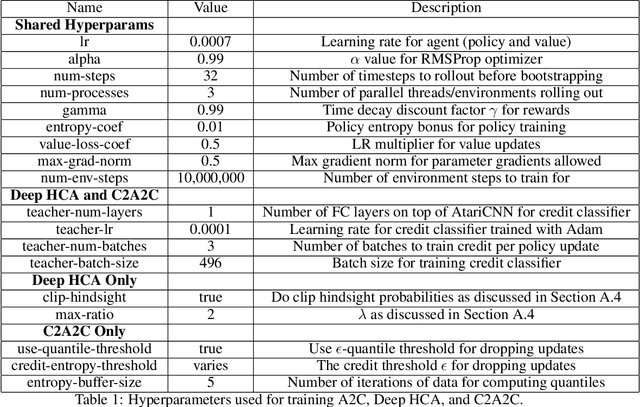
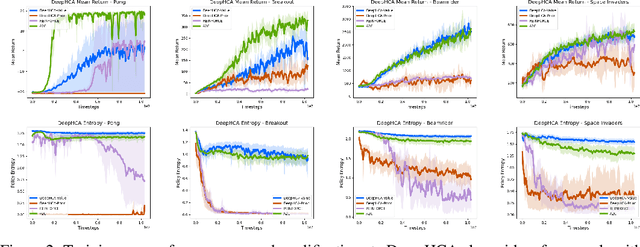
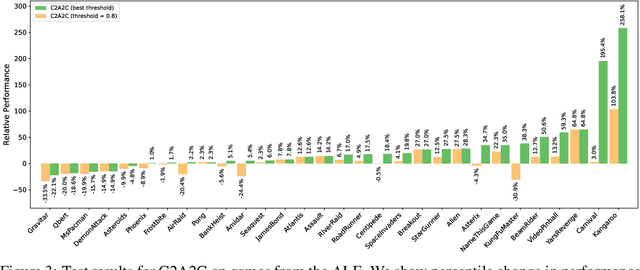
Credit assignment is a fundamental problem in reinforcement learning, the problem of measuring an action's influence on future rewards. Improvements in credit assignment methods have the potential to boost the performance of RL algorithms on many tasks, but thus far have not seen widespread adoption. Recently, a family of methods called Hindsight Credit Assignment (HCA) was proposed, which explicitly assign credit to actions in hindsight based on the probability of the action having led to an observed outcome. This approach is appealing as a means to more efficient data usage, but remains a largely theoretical idea applicable to a limited set of tabular RL tasks, and it is unclear how to extend HCA to Deep RL environments. In this work, we explore the use of HCA-style credit in a deep RL context. We first describe the limitations of existing HCA algorithms in deep RL, then propose several theoretically-justified modifications to overcome them. Based on this exploration, we present a new algorithm, Credit-Constrained Advantage Actor-Critic (C2A2C), which ignores policy updates for actions which don't affect future outcomes based on credit in hindsight, while updating the policy as normal for those that do. We find that C2A2C outperforms Advantage Actor-Critic (A2C) on the Arcade Learning Environment (ALE) benchmark, showing broad improvements over A2C and motivating further work on credit-constrained update rules for deep RL methods.