 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThalamocortical motor circuit insights for more robust hierarchical control of complex sequences
Jun 23, 2020

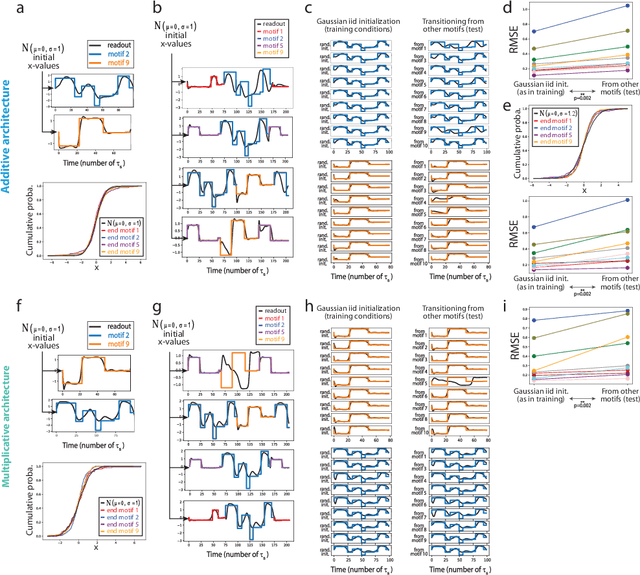
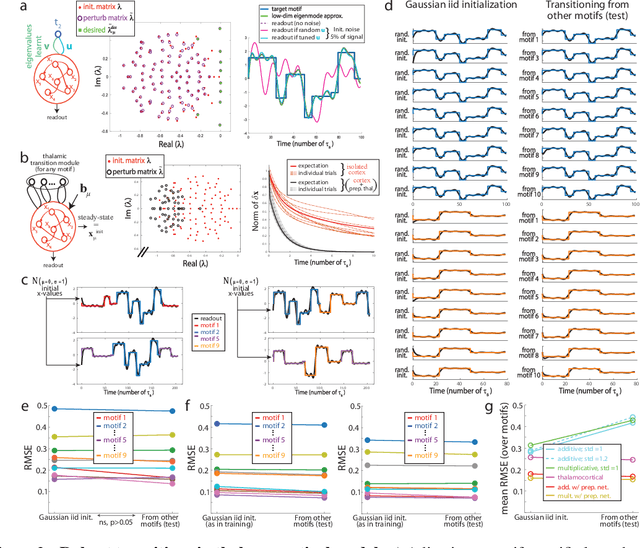
We study learning of recurrent neural networks that produce temporal sequences consisting of the concatenation of re-usable "motifs". In the context of neuroscience or robotics, these motifs would be the motor primitives from which complex behavior is generated. Given a known set of motifs, can a new motif be learned without affecting the performance of the known set and then used in new sequences without first explicitly learning every possible transition? Two requirements enable this: (i) parameter updates while learning a new motif do not interfere with the parameters used for the previously acquired ones; and (ii) a new motif can be robustly generated when starting from the network state reached at the end of any of the other motifs, even if that state was not present during training. We meet the first requirement by investigating artificial neural networks (ANNs) with specific architectures, and attempt to meet the second by training them to generate motifs from random initial states. We find that learning of single motifs succeeds but that sequence generation is not robust: transition failures are observed. We then compare these results with a model whose architecture and analytically-tractable dynamics are inspired by the motor thalamocortical circuit, and that includes a specific module used to implement motif transitions. The synaptic weights of this model can be adjusted without requiring stochastic gradient descent (SGD) on the simulated network outputs, and we have asymptotic guarantees that transitions will not fail. Indeed, in simulations, we achieve single-motif accuracy on par with the previously studied ANNs and have improved sequencing robustness with no transition failures. Finally, we show that insights obtained by studying the transition subnetwork of this model can also improve the robustness of transitioning in the traditional ANNs previously studied.
full-FORCE: A Target-Based Method for Training Recurrent Networks
Oct 09, 2017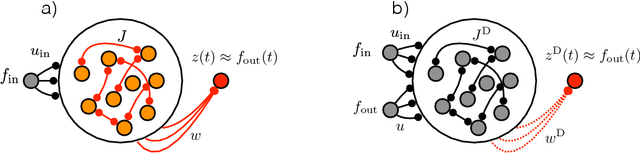
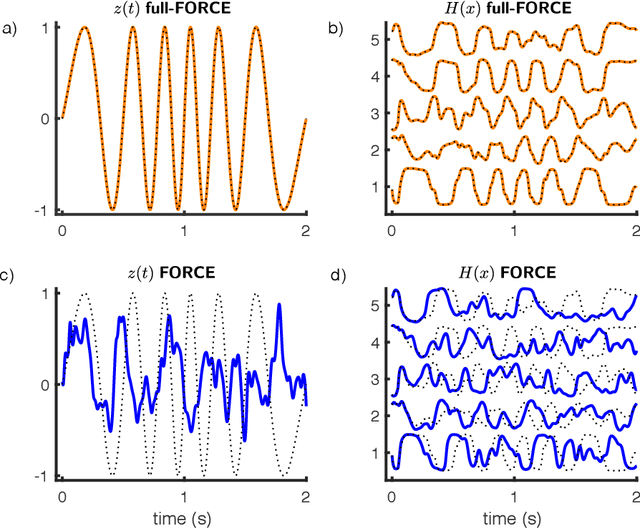
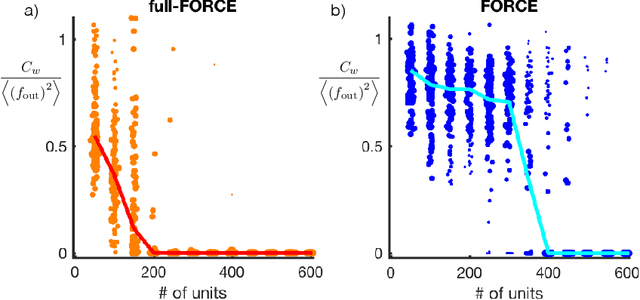
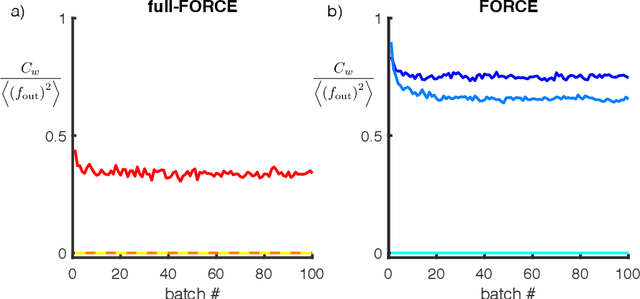
Trained recurrent networks are powerful tools for modeling dynamic neural computations. We present a target-based method for modifying the full connectivity matrix of a recurrent network to train it to perform tasks involving temporally complex input/output transformations. The method introduces a second network during training to provide suitable "target" dynamics useful for performing the task. Because it exploits the full recurrent connectivity, the method produces networks that perform tasks with fewer neurons and greater noise robustness than traditional least-squares (FORCE) approaches. In addition, we show how introducing additional input signals into the target-generating network, which act as task hints, greatly extends the range of tasks that can be learned and provides control over the complexity and nature of the dynamics of the trained, task-performing network.