 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparser Training for On-Device Recommendation Systems
Nov 19, 2024



Recommender systems often rely on large embedding tables that map users and items to dense vectors of uniform size, leading to substantial memory consumption and inefficiencies. This is particularly problematic in memory-constrained environments like mobile and Web of Things (WoT) applications, where scalability and real-time performance are critical. Various research efforts have sought to address these issues. Although embedding pruning methods utilizing Dynamic Sparse Training (DST) stand out due to their low training and inference costs, consistent sparsity, and end-to-end differentiability, they face key challenges. Firstly, they typically initializes the mask matrix, which is used to prune redundant parameters, with random uniform sparse initialization. This strategy often results in suboptimal performance as it creates unstructured and inefficient connections. Secondly, they tend to favor the users/items sampled in the single batch immediately before weight exploration when they reactivate pruned parameters with large gradient magnitudes, which does not necessarily improve the overall performance. Thirdly, while they use sparse weights during forward passes, they still need to compute dense gradients during backward passes. In this paper, we propose SparseRec, an lightweight embedding method based on DST, to address these issues. Specifically, SparseRec initializes the mask matrix using Nonnegative Matrix Factorization. It accumulates gradients to identify the inactive parameters that can better improve the model performance after activation. Furthermore, it avoids dense gradients during backpropagation by sampling a subset of important vectors. Gradients are calculated only for parameters in this subset, thus maintaining sparsity during training in both forward and backward passes.
Scalable Dynamic Embedding Size Search for Streaming Recommendation
Jul 22, 2024



Recommender systems typically represent users and items by learning their embeddings, which are usually set to uniform dimensions and dominate the model parameters. However, real-world recommender systems often operate in streaming recommendation scenarios, where the number of users and items continues to grow, leading to substantial storage resource consumption for these embeddings. Although a few methods attempt to mitigate this by employing embedding size search strategies to assign different embedding dimensions in streaming recommendations, they assume that the embedding size grows with the frequency of users/items, which eventually still exceeds the predefined memory budget over time. To address this issue, this paper proposes to learn Scalable Lightweight Embeddings for streaming recommendation, called SCALL, which can adaptively adjust the embedding sizes of users/items within a given memory budget over time. Specifically, we propose to sample embedding sizes from a probabilistic distribution, with the guarantee to meet any predefined memory budget. By fixing the memory budget, the proposed embedding size sampling strategy can increase and decrease the embedding sizes in accordance to the frequency of the corresponding users or items. Furthermore, we develop a reinforcement learning-based search paradigm that models each state with mean pooling to keep the length of the state vectors fixed, invariant to the changing number of users and items. As a result, the proposed method can provide embedding sizes to unseen users and items. Comprehensive empirical evaluations on two public datasets affirm the advantageous effectiveness of our proposed method.
Budgeted Embedding Table For Recommender Systems
Oct 23, 2023At the heart of contemporary recommender systems (RSs) are latent factor models that provide quality recommendation experience to users. These models use embedding vectors, which are typically of a uniform and fixed size, to represent users and items. As the number of users and items continues to grow, this design becomes inefficient and hard to scale. Recent lightweight embedding methods have enabled different users and items to have diverse embedding sizes, but are commonly subject to two major drawbacks. Firstly, they limit the embedding size search to optimizing a heuristic balancing the recommendation quality and the memory complexity, where the trade-off coefficient needs to be manually tuned for every memory budget requested. The implicitly enforced memory complexity term can even fail to cap the parameter usage, making the resultant embedding table fail to meet the memory budget strictly. Secondly, most solutions, especially reinforcement learning based ones derive and optimize the embedding size for each each user/item on an instance-by-instance basis, which impedes the search efficiency. In this paper, we propose Budgeted Embedding Table (BET), a novel method that generates table-level actions (i.e., embedding sizes for all users and items) that is guaranteed to meet pre-specified memory budgets. Furthermore, by leveraging a set-based action formulation and engaging set representation learning, we present an innovative action search strategy powered by an action fitness predictor that efficiently evaluates each table-level action. Experiments have shown state-of-the-art performance on two real-world datasets when BET is paired with three popular recommender models under different memory budgets.
Continuous Input Embedding Size Search For Recommender Systems
Apr 25, 2023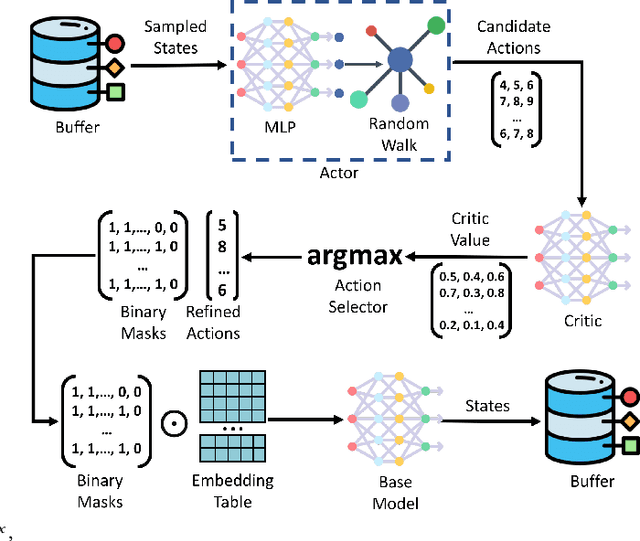
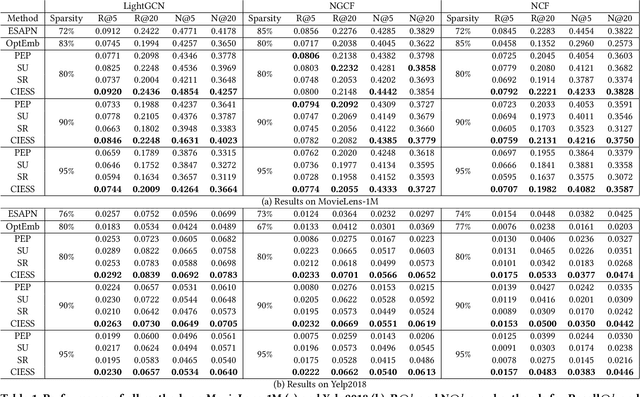
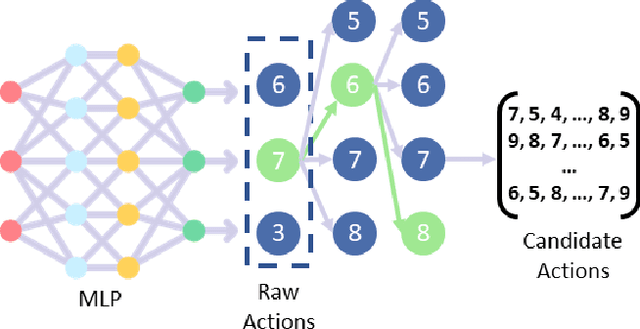

Latent factor models are the most popular backbones for today's recommender systems owing to their prominent performance. Latent factor models represent users and items as real-valued embedding vectors for pairwise similarity computation, and all embeddings are traditionally restricted to a uniform size that is relatively large (e.g., 256-dimensional). With the exponentially expanding user base and item catalog in contemporary e-commerce, this design is admittedly becoming memory-inefficient. To facilitate lightweight recommendation, reinforcement learning (RL) has recently opened up opportunities for identifying varying embedding sizes for different users/items. However, challenged by search efficiency and learning an optimal RL policy, existing RL-based methods are restricted to highly discrete, predefined embedding size choices. This leads to a largely overlooked potential of introducing finer granularity into embedding sizes to obtain better recommendation effectiveness under a given memory budget. In this paper, we propose continuous input embedding size search (CIESS), a novel RL-based method that operates on a continuous search space with arbitrary embedding sizes to choose from. In CIESS, we further present an innovative random walk-based exploration strategy to allow the RL policy to efficiently explore more candidate embedding sizes and converge to a better decision. CIESS is also model-agnostic and hence generalizable to a variety of latent factor RSs, whilst experiments on two real-world datasets have shown state-of-the-art performance of CIESS under different memory budgets when paired with three popular recommendation models.