 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
May 11, 2026In industrial procurement, an LLM answer is useful only if it survives a standards check: recommended material must match operating condition, every parameter must respect a regulated threshold, and no procedure may contradict a safety clause. Partial correctness can mask safety-critical contradictions that aggregate LLM benchmarks rarely capture. We introduce IndustryBench, a 2,049-item benchmark for industrial procurement QA in Chinese, grounded in Chinese national standards (GB/T) and structured industrial product records, organized by seven capability dimensions, ten industry categories, and panel-derived difficulty tiers, with item-aligned English, Russian, and Vietnamese renderings. Our construction pipeline rejects 70.3% of LLM-generated candidates at a search-based external-verification stage, calibrating how unreliable industrial QA remains after LLM-only filtering.Our evaluation decouples raw correctness, scored by a Qwen3-Max judge validated at $κ_w = 0.798$ against a domain expert, from a separate safety-violation (SV) check against source texts. Across 17 models in Chinese and an 8-model intersection over four languages, we find: (i) the best system reaches only 2.083 on the 0--3 rubric, leaving substantial headroom; (ii) Standards & Terminology is the most persistent capability weakness and survives item-aligned translation; (iii) extended reasoning lowers safety-adjusted scores for 12 of 13 models, primarily by introducing unsupported safety-critical details into longer final answers; and (iv) safety-violation rates reshuffle the leaderboard -- GPT-5.4 climbs from rank 6 to rank 3 after SV adjustment, while Kimi-k2.5-1T-A32B drops seven positions.Industrial LLM evaluation therefore requires source-grounded, safety-aware diagnosis rather than aggregate accuracy. We release IndustryBench with all prompts, scoring scripts, and dataset documentation.
ConInstruct: Evaluating Large Language Models on Conflict Detection and Resolution in Instructions
Nov 19, 2025Instruction-following is a critical capability of Large Language Models (LLMs). While existing works primarily focus on assessing how well LLMs adhere to user instructions, they often overlook scenarios where instructions contain conflicting constraints-a common occurrence in complex prompts. The behavior of LLMs under such conditions remains under-explored. To bridge this gap, we introduce ConInstruct, a benchmark specifically designed to assess LLMs' ability to detect and resolve conflicts within user instructions. Using this dataset, we evaluate LLMs' conflict detection performance and analyze their conflict resolution behavior. Our experiments reveal two key findings: (1) Most proprietary LLMs exhibit strong conflict detection capabilities, whereas among open-source models, only DeepSeek-R1 demonstrates similarly strong performance. DeepSeek-R1 and Claude-4.5-Sonnet achieve the highest average F1-scores at 91.5% and 87.3%, respectively, ranking first and second overall. (2) Despite their strong conflict detection abilities, LLMs rarely explicitly notify users about the conflicts or request clarification when faced with conflicting constraints. These results underscore a critical shortcoming in current LLMs and highlight an important area for future improvement when designing instruction-following LLMs.
Out-of-Distribution Detection with Positive and Negative Prompt Supervision Using Large Language Models
Nov 14, 2025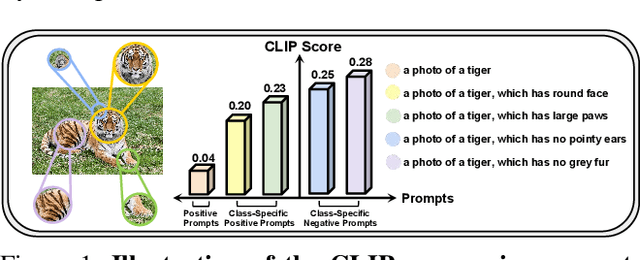
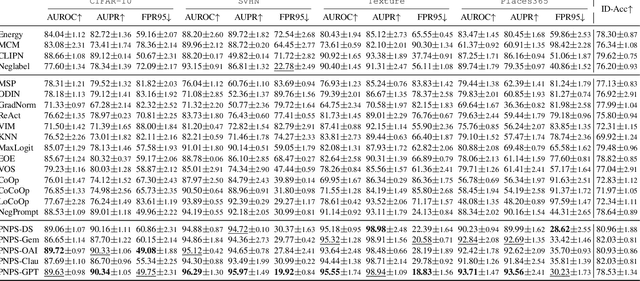
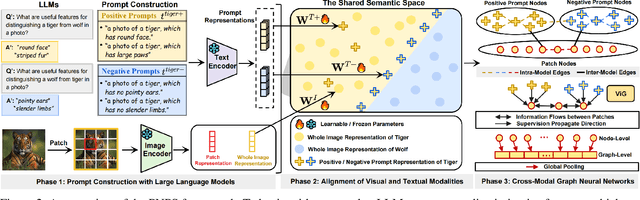
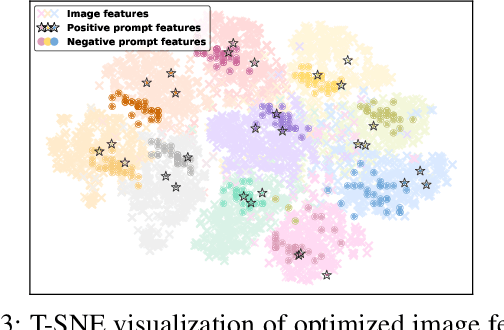
Out-of-distribution (OOD) detection is committed to delineating the classification boundaries between in-distribution (ID) and OOD images. Recent advances in vision-language models (VLMs) have demonstrated remarkable OOD detection performance by integrating both visual and textual modalities. In this context, negative prompts are introduced to emphasize the dissimilarity between image features and prompt content. However, these prompts often include a broad range of non-ID features, which may result in suboptimal outcomes due to the capture of overlapping or misleading information. To address this issue, we propose Positive and Negative Prompt Supervision, which encourages negative prompts to capture inter-class features and transfers this semantic knowledge to the visual modality to enhance OOD detection performance. Our method begins with class-specific positive and negative prompts initialized by large language models (LLMs). These prompts are subsequently optimized, with positive prompts focusing on features within each class, while negative prompts highlight features around category boundaries. Additionally, a graph-based architecture is employed to aggregate semantic-aware supervision from the optimized prompt representations and propagate it to the visual branch, thereby enhancing the performance of the energy-based OOD detector. Extensive experiments on two benchmarks, CIFAR-100 and ImageNet-1K, across eight OOD datasets and five different LLMs, demonstrate that our method outperforms state-of-the-art baselines.
Evidential Uncertainty Probes for Graph Neural Networks
Mar 11, 2025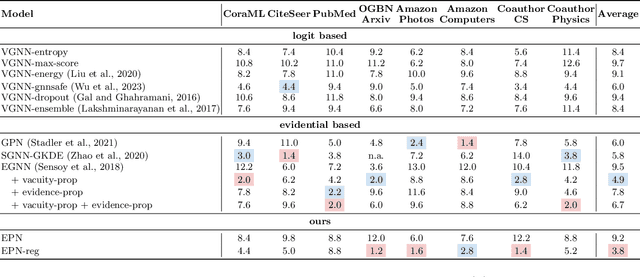
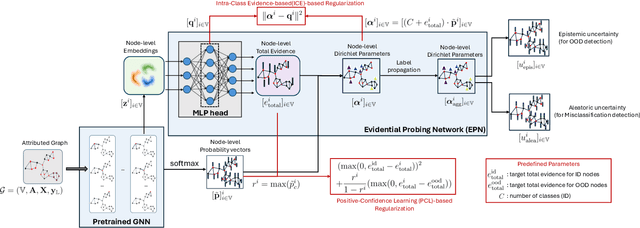
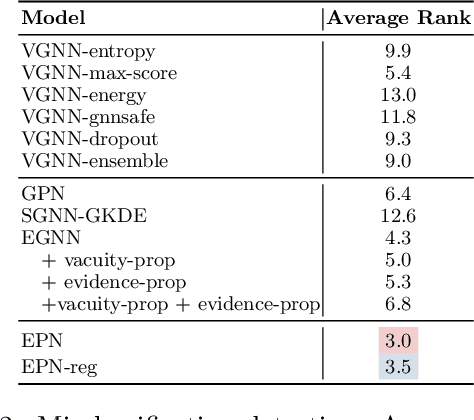
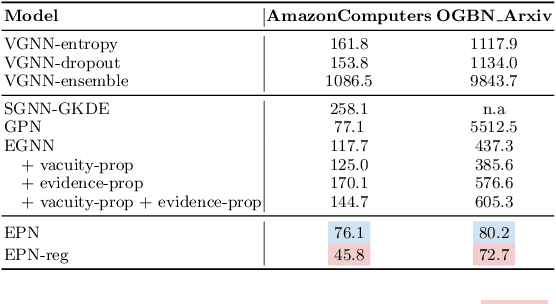
Accurate quantification of both aleatoric and epistemic uncertainties is essential when deploying Graph Neural Networks (GNNs) in high-stakes applications such as drug discovery and financial fraud detection, where reliable predictions are critical. Although Evidential Deep Learning (EDL) efficiently quantifies uncertainty using a Dirichlet distribution over predictive probabilities, existing EDL-based GNN (EGNN) models require modifications to the network architecture and retraining, failing to take advantage of pre-trained models. We propose a plug-and-play framework for uncertainty quantification in GNNs that works with pre-trained models without the need for retraining. Our Evidential Probing Network (EPN) uses a lightweight Multi-Layer-Perceptron (MLP) head to extract evidence from learned representations, allowing efficient integration with various GNN architectures. We further introduce evidence-based regularization techniques, referred to as EPN-reg, to enhance the estimation of epistemic uncertainty with theoretical justifications. Extensive experiments demonstrate that the proposed EPN-reg achieves state-of-the-art performance in accurate and efficient uncertainty quantification, making it suitable for real-world deployment.
Can We Trust the Performance Evaluation of Uncertainty Estimation Methods in Text Summarization?
Jun 25, 2024Text summarization, a key natural language generation (NLG) task, is vital in various domains. However, the high cost of inaccurate summaries in risk-critical applications, particularly those involving human-in-the-loop decision-making, raises concerns about the reliability of uncertainty estimation on text summarization (UE-TS) evaluation methods. This concern stems from the dependency of uncertainty model metrics on diverse and potentially conflicting NLG metrics. To address this issue, we introduce a comprehensive UE-TS benchmark incorporating 31 NLG metrics across four dimensions. The benchmark evaluates the uncertainty estimation capabilities of two large language models and one pre-trained language model on three datasets, with human-annotation analysis incorporated where applicable. We also assess the performance of 14 common uncertainty estimation methods within this benchmark. Our findings emphasize the importance of considering multiple uncorrelated NLG metrics and diverse uncertainty estimation methods to ensure reliable and efficient evaluation of UE-TS techniques.
Uncertainty Quantification for Bird's Eye View Semantic Segmentation: Methods and Benchmarks
May 31, 2024



The fusion of raw features from multiple sensors on an autonomous vehicle to create a Bird's Eye View (BEV) representation is crucial for planning and control systems. There is growing interest in using deep learning models for BEV semantic segmentation. Anticipating segmentation errors and improving the explainability of DNNs is essential for autonomous driving, yet it is under-studied. This paper introduces a benchmark for predictive uncertainty quantification in BEV segmentation. The benchmark assesses various approaches across three popular datasets using two representative backbones and focuses on the effectiveness of predicted uncertainty in identifying misclassified and out-of-distribution (OOD) pixels, as well as calibration. Empirical findings highlight the challenges in uncertainty quantification. Our results find that evidential deep learning based approaches show the most promise by efficiently quantifying aleatoric and epistemic uncertainty. We propose the Uncertainty-Focal-Cross-Entropy (UFCE) loss, designed for highly imbalanced data, which consistently improves the segmentation quality and calibration. Additionally, we introduce a vacuity-scaled regularization term that enhances the model's focus on high uncertainty pixels, improving epistemic uncertainty quantification.
Uncertainty Estimation on Sequential Labeling via Uncertainty Transmission
Nov 15, 2023Sequential labeling is a task predicting labels for each token in a sequence, such as Named Entity Recognition (NER). NER tasks aim to extract entities and predict their labels given a text, which is important in information extraction. Although previous works have shown great progress in improving NER performance, uncertainty estimation on NER (UE-NER) is still underexplored but essential. This work focuses on UE-NER, which aims to estimate uncertainty scores for the NER predictions. Previous uncertainty estimation models often overlook two unique characteristics of NER: the connection between entities (i.e., one entity embedding is learned based on the other ones) and wrong span cases in the entity extraction subtask. Therefore, we propose a Sequential Labeling Posterior Network (SLPN) to estimate uncertainty scores for the extracted entities, considering uncertainty transmitted from other tokens. Moreover, we have defined an evaluation strategy to address the specificity of wrong-span cases. Our SLPN has achieved significant improvements on two datasets, such as a 5.54-point improvement in AUPR on the MIT-Restaurant dataset.
Improvements on Uncertainty Quantification for Node Classification via Distance-Based Regularization
Nov 10, 2023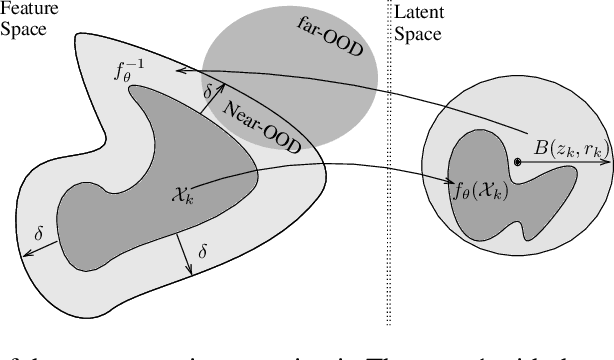
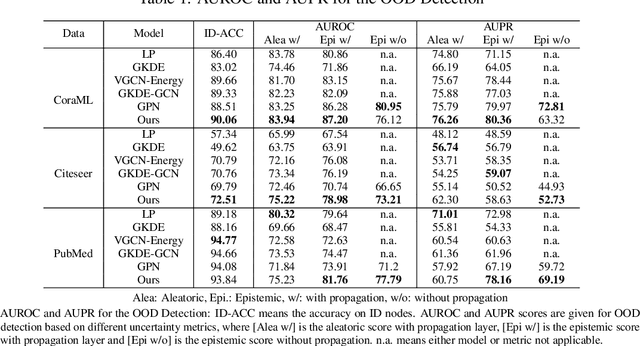
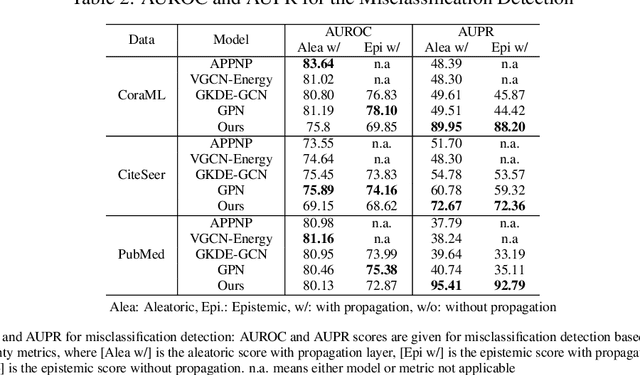

Deep neural networks have achieved significant success in the last decades, but they are not well-calibrated and often produce unreliable predictions. A large number of literature relies on uncertainty quantification to evaluate the reliability of a learning model, which is particularly important for applications of out-of-distribution (OOD) detection and misclassification detection. We are interested in uncertainty quantification for interdependent node-level classification. We start our analysis based on graph posterior networks (GPNs) that optimize the uncertainty cross-entropy (UCE)-based loss function. We describe the theoretical limitations of the widely-used UCE loss. To alleviate the identified drawbacks, we propose a distance-based regularization that encourages clustered OOD nodes to remain clustered in the latent space. We conduct extensive comparison experiments on eight standard datasets and demonstrate that the proposed regularization outperforms the state-of-the-art in both OOD detection and misclassification detection.