 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Human Interactions Replicable by Generative Agents? A Case Study on Pronoun Usage in Hierarchical Interactions
Paper and Code
Jan 25, 2025
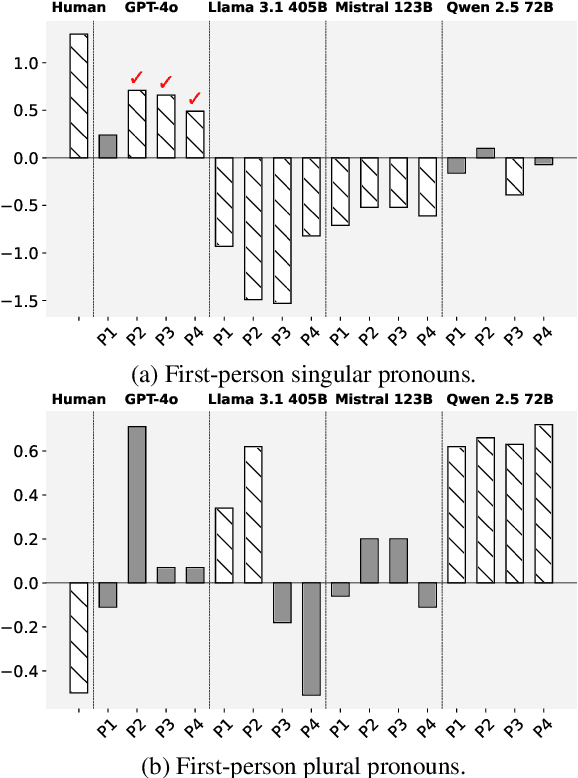
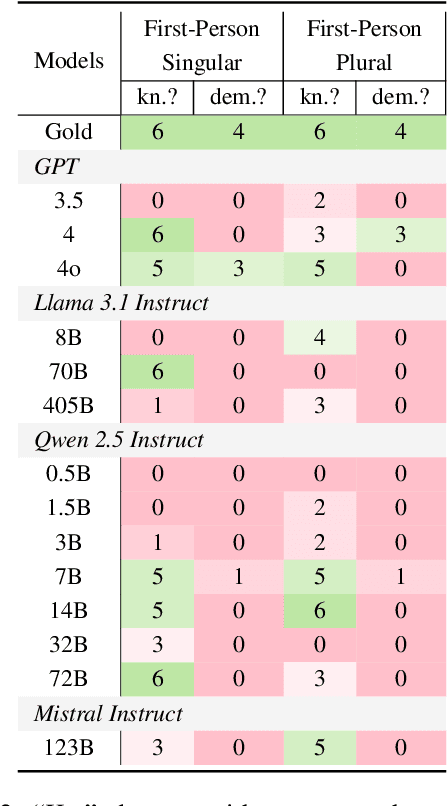
As Large Language Models (LLMs) advance in their capabilities, researchers have increasingly employed them for social simulation. In this paper, we investigate whether interactions among LLM agents resemble those of humans. Specifically, we focus on the pronoun usage difference between leaders and non-leaders, examining whether the simulation would lead to human-like pronoun usage patterns during the LLMs' interactions. Our evaluation reveals the significant discrepancies between LLM-based simulations and human pronoun usage, with prompt-based or specialized agents failing to demonstrate human-like pronoun usage patterns. In addition, we reveal that even if LLMs understand the human pronoun usage patterns, they fail to demonstrate them in the actual interaction process. Our study highlights the limitations of social simulations based on LLM agents, urging caution in using such social simulation in practitioners' decision-making process.