 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTP-Net For Cross-Domain Trajectory Prediction
Oct 22, 2021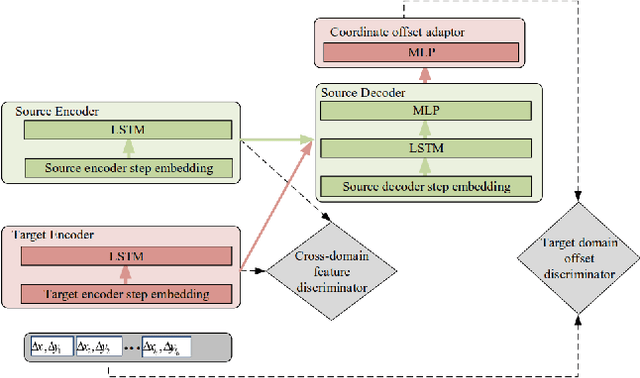


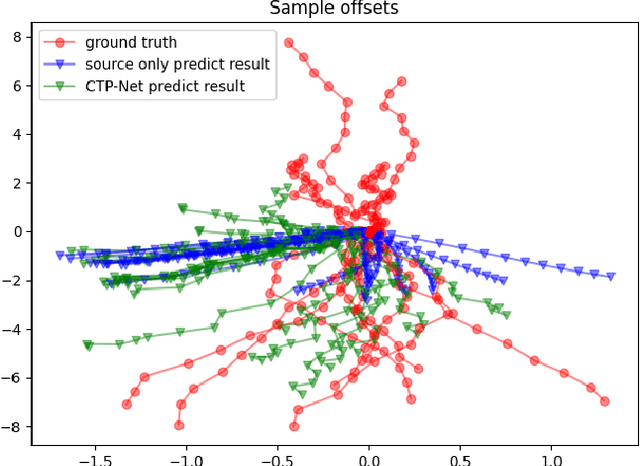
Deep learning based trajectory prediction methods rely on large amount of annotated future trajectories, but may not generalize well to a new scenario captured by another camera. Meanwhile, annotating trajectories for training a network for this new scenario is time-consuming and expensive, therefore it is desirable to adapt the model trained with the annotated source domain trajectories to the target domain. To tackle domain adaptation for trajectory prediction, we propose a Cross-domain Trajectory Prediction Network (CTP-Net), in which LSTMs are used to encode the observed trajectories of both domain, and their features are aligned by a cross-domain feature discriminator. Further, considering the consistency between the observed trajectories and the predicted trajectories in the target domain, a target domain offset discriminator is utilized to adversarially regularize the future trajectory predictions to be consistent with the observed trajectories. Extensive experiments demonstrate the effectiveness of the proposed domain adaptation for trajectory prediction setting as well as our method on domain adaptation for trajectory prediction.
Locality-constrained Spatial Transformer Network for Video Crowd Counting
Jul 18, 2019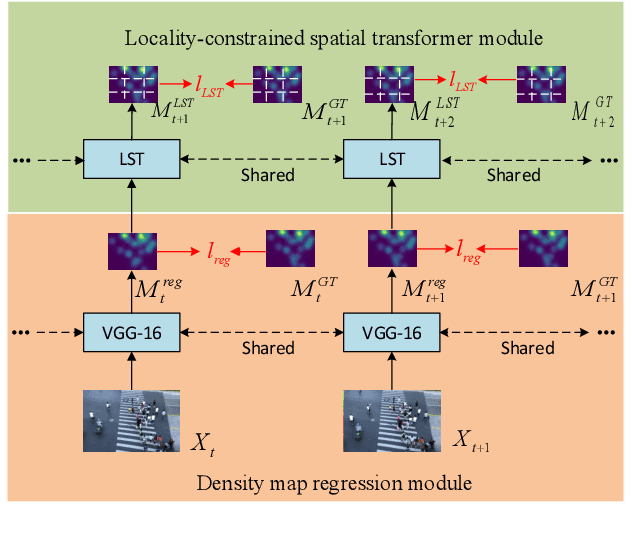
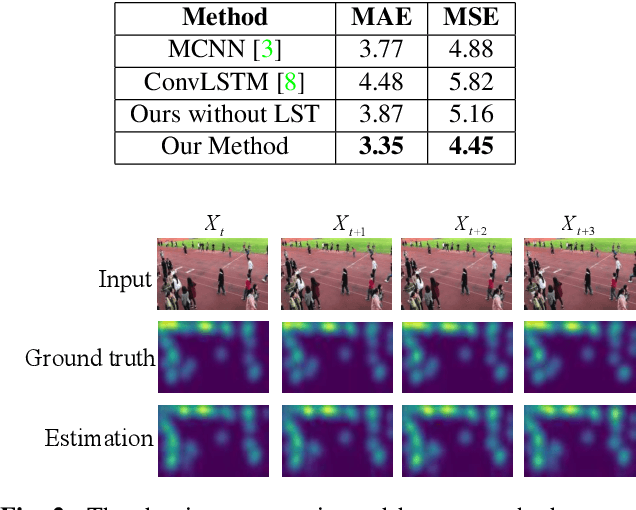
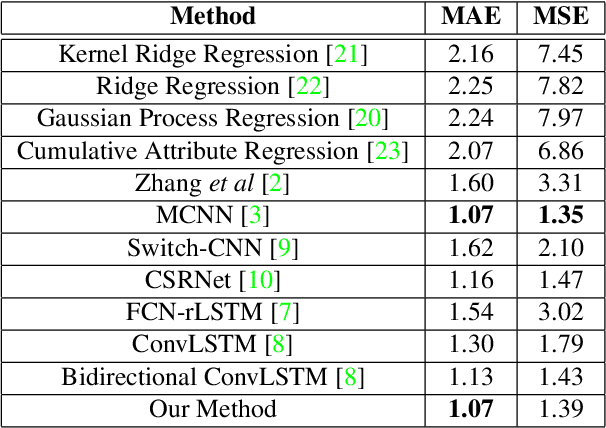
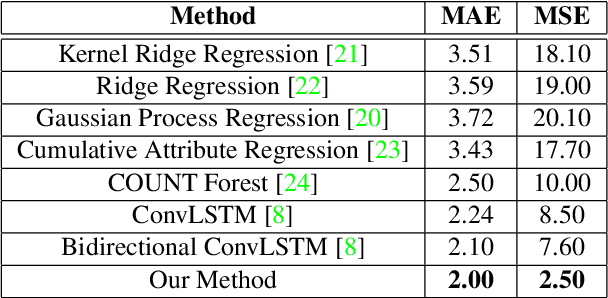
Compared with single image based crowd counting, video provides the spatial-temporal information of the crowd that would help improve the robustness of crowd counting. But translation, rotation and scaling of people lead to the change of density map of heads between neighbouring frames. Meanwhile, people walking in/out or being occluded in dynamic scenes leads to the change of head counts. To alleviate these issues in video crowd counting, a Locality-constrained Spatial Transformer Network (LSTN) is proposed. Specifically, we first leverage a Convolutional Neural Networks to estimate the density map for each frame. Then to relate the density maps between neighbouring frames, a Locality-constrained Spatial Transformer (LST) module is introduced to estimate the density map of next frame with that of current frame. To facilitate the performance evaluation, a large-scale video crowd counting dataset is collected, which contains 15K frames with about 394K annotated heads captured from 13 different scenes. As far as we know, it is the largest video crowd counting dataset. Extensive experiments on our dataset and other crowd counting datasets validate the effectiveness of our LSTN for crowd counting.