 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocality-constrained Spatial Transformer Network for Video Crowd Counting
Paper and Code
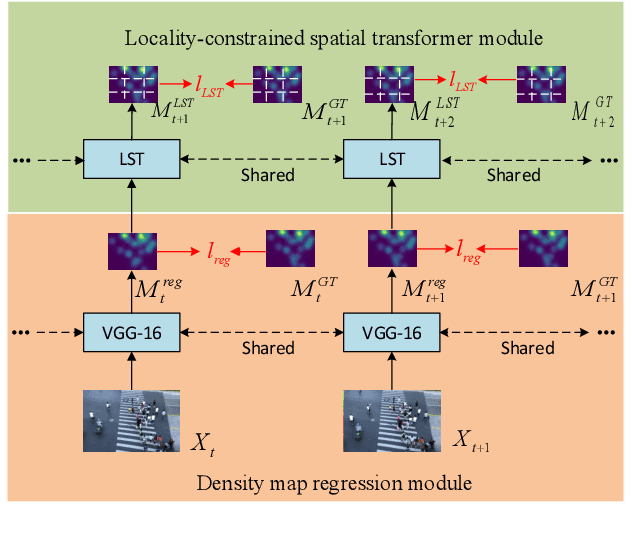
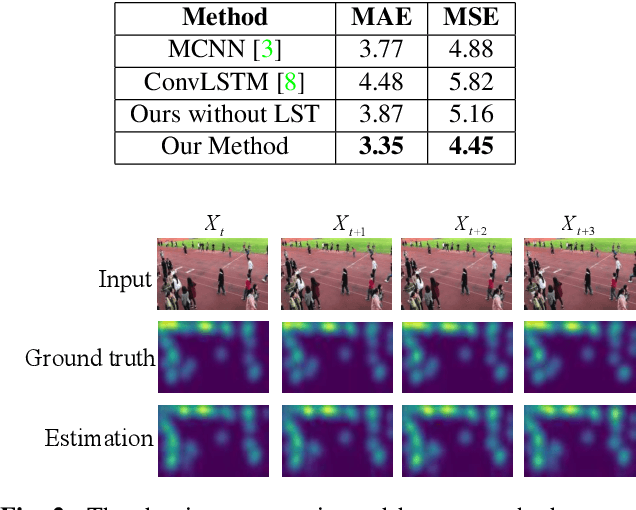
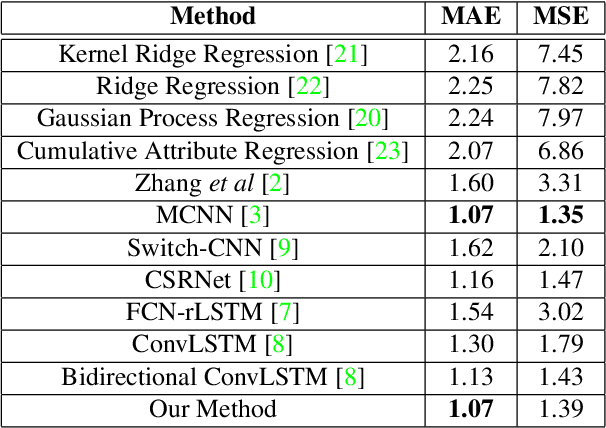
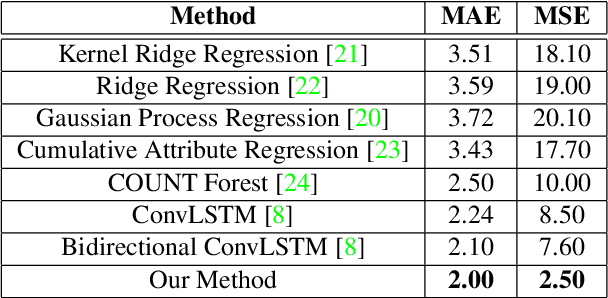
Compared with single image based crowd counting, video provides the spatial-temporal information of the crowd that would help improve the robustness of crowd counting. But translation, rotation and scaling of people lead to the change of density map of heads between neighbouring frames. Meanwhile, people walking in/out or being occluded in dynamic scenes leads to the change of head counts. To alleviate these issues in video crowd counting, a Locality-constrained Spatial Transformer Network (LSTN) is proposed. Specifically, we first leverage a Convolutional Neural Networks to estimate the density map for each frame. Then to relate the density maps between neighbouring frames, a Locality-constrained Spatial Transformer (LST) module is introduced to estimate the density map of next frame with that of current frame. To facilitate the performance evaluation, a large-scale video crowd counting dataset is collected, which contains 15K frames with about 394K annotated heads captured from 13 different scenes. As far as we know, it is the largest video crowd counting dataset. Extensive experiments on our dataset and other crowd counting datasets validate the effectiveness of our LSTN for crowd counting.