 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Action Co-occurrence in Lifestyle Vlogs using Graph Link Prediction
Sep 22, 2023We introduce the task of automatic human action co-occurrence identification, i.e., determine whether two human actions can co-occur in the same interval of time. We create and make publicly available the ACE (Action Co-occurrencE) dataset, consisting of a large graph of ~12k co-occurring pairs of visual actions and their corresponding video clips. We describe graph link prediction models that leverage visual and textual information to automatically infer if two actions are co-occurring. We show that graphs are particularly well suited to capture relations between human actions, and the learned graph representations are effective for our task and capture novel and relevant information across different data domains. The ACE dataset and the code introduced in this paper are publicly available at https://github.com/MichiganNLP/vlog_action_co-occurrence.
WhyAct: Identifying Action Reasons in Lifestyle Vlogs
Sep 09, 2021
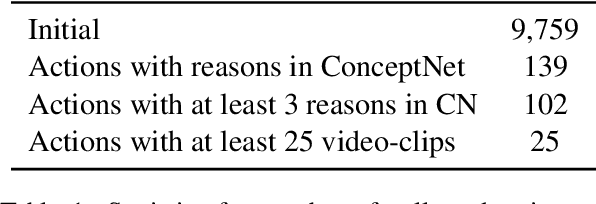

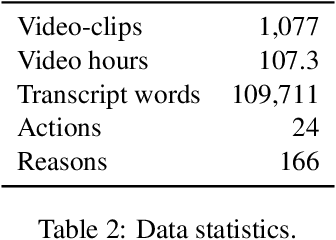
We aim to automatically identify human action reasons in online videos. We focus on the widespread genre of lifestyle vlogs, in which people perform actions while verbally describing them. We introduce and make publicly available the WhyAct dataset, consisting of 1,077 visual actions manually annotated with their reasons. We describe a multimodal model that leverages visual and textual information to automatically infer the reasons corresponding to an action presented in the video.