 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhyAct: Identifying Action Reasons in Lifestyle Vlogs
Sep 09, 2021
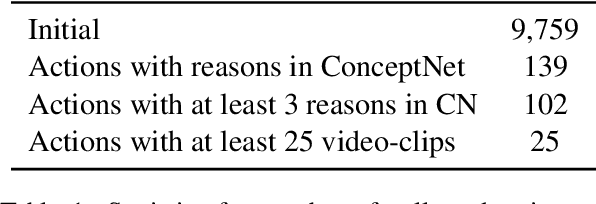

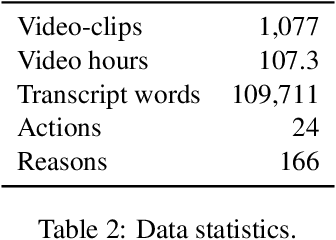
We aim to automatically identify human action reasons in online videos. We focus on the widespread genre of lifestyle vlogs, in which people perform actions while verbally describing them. We introduce and make publicly available the WhyAct dataset, consisting of 1,077 visual actions manually annotated with their reasons. We describe a multimodal model that leverages visual and textual information to automatically infer the reasons corresponding to an action presented in the video.
Driver Behavior Extraction from Videos in Naturalistic Driving Datasets with 3D ConvNets
Nov 30, 2020
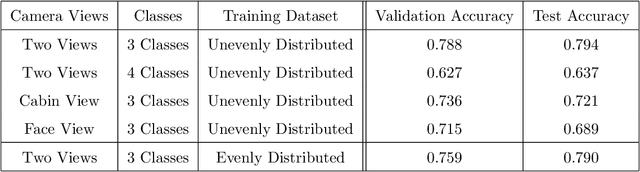
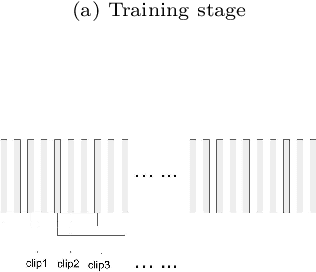

Naturalistic driving data (NDD) is an important source of information to understand crash causation and human factors and to further develop crash avoidance countermeasures. Videos recorded while driving are often included in such datasets. While there is often a large amount of video data in NDD, only a small portion of them can be annotated by human coders and used for research, which underuses all video data. In this paper, we explored a computer vision method to automatically extract the information we need from videos. More specifically, we developed a 3D ConvNet algorithm to automatically extract cell-phone-related behaviors from videos. The experiments show that our method can extract chunks from videos, most of which (~79%) contain the automatically labeled cell phone behaviors. In conjunction with human review of the extracted chunks, this approach can find cell-phone-related driver behaviors much more efficiently than simply viewing video.