 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtemis: A Novel Annotation Methodology for Indicative Single Document Summarization
May 14, 2020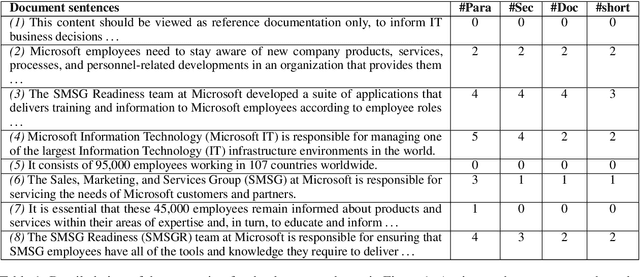
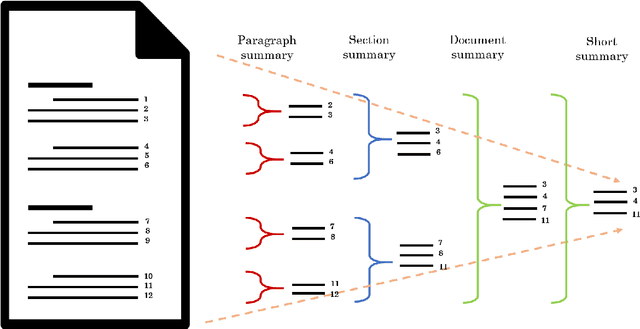

We describe Artemis (Annotation methodology for Rich, Tractable, Extractive, Multi-domain, Indicative Summarization), a novel hierarchical annotation process that produces indicative summaries for documents from multiple domains. Current summarization evaluation datasets are single-domain and focused on a few domains for which naturally occurring summaries can be easily found, such as news and scientific articles. These are not sufficient for training and evaluation of summarization models for use in document management and information retrieval systems, which need to deal with documents from multiple domains. Compared to other annotation methods such as Relative Utility and Pyramid, Artemis is more tractable because judges don't need to look at all the sentences in a document when making an importance judgment for one of the sentences, while providing similarly rich sentence importance annotations. We describe the annotation process in detail and compare it with other similar evaluation systems. We also present analysis and experimental results over a sample set of 532 annotated documents.
Infinite Mixed Membership Matrix Factorization
Jan 15, 2014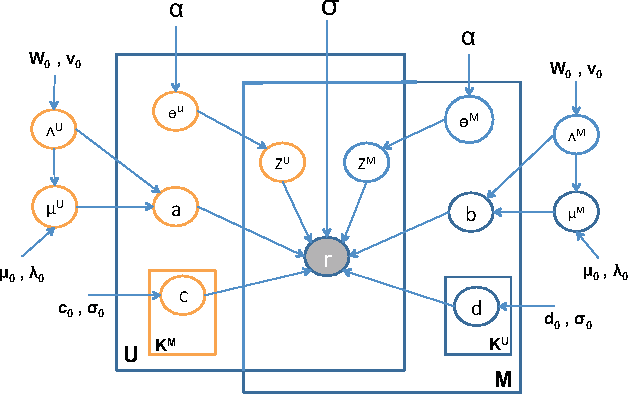
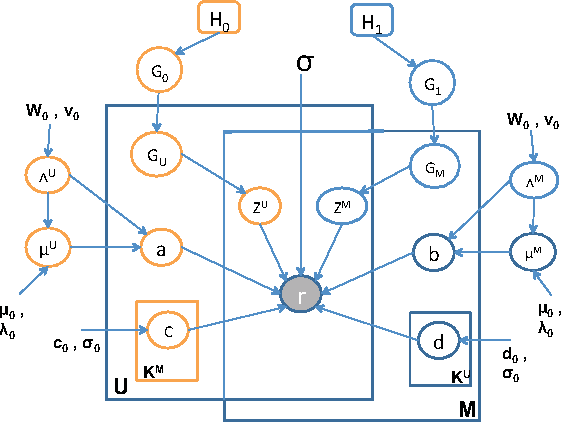
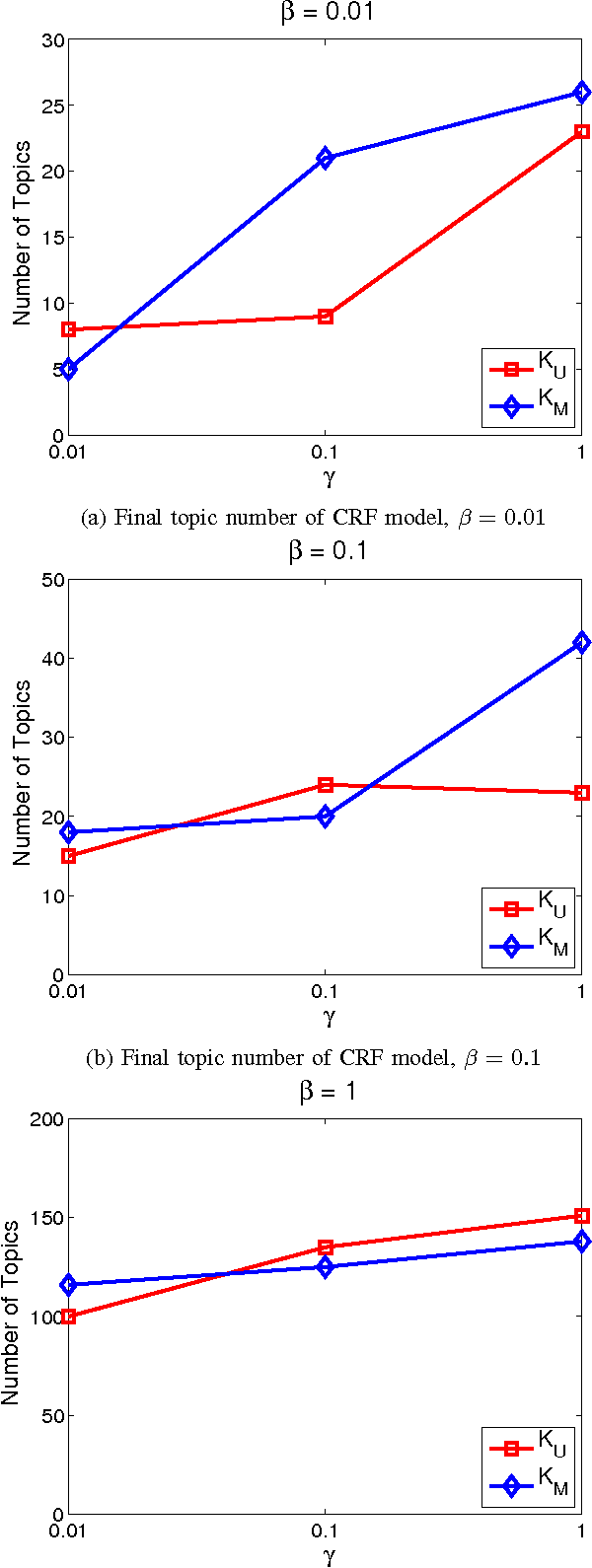
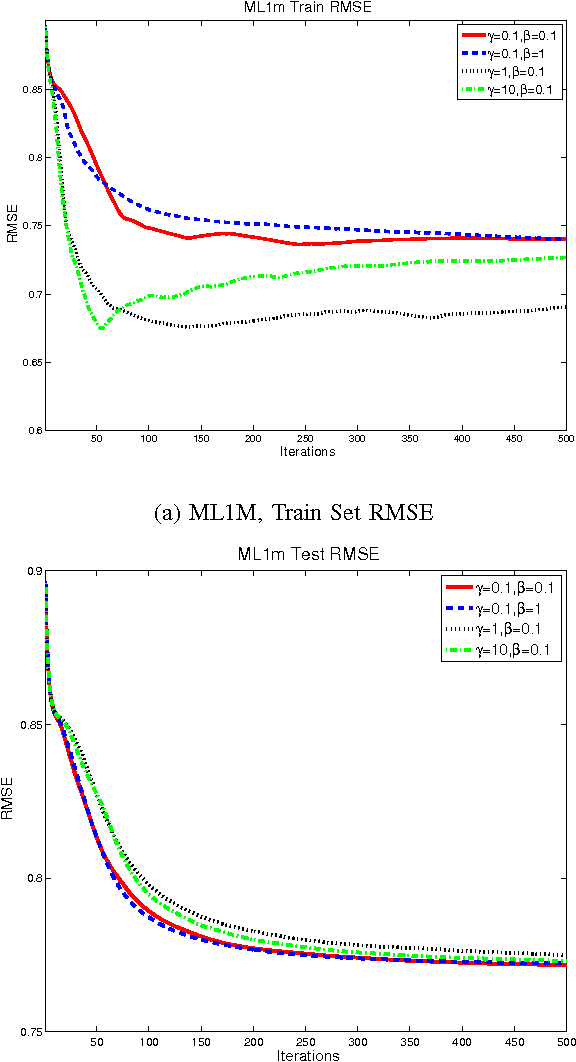
Rating and recommendation systems have become a popular application area for applying a suite of machine learning techniques. Current approaches rely primarily on probabilistic interpretations and extensions of matrix factorization, which factorizes a user-item ratings matrix into latent user and item vectors. Most of these methods fail to model significant variations in item ratings from otherwise similar users, a phenomenon known as the "Napoleon Dynamite" effect. Recent efforts have addressed this problem by adding a contextual bias term to the rating, which captures the mood under which a user rates an item or the context in which an item is rated by a user. In this work, we extend this model in a nonparametric sense by learning the optimal number of moods or contexts from the data, and derive Gibbs sampling inference procedures for our model. We evaluate our approach on the MovieLens 1M dataset, and show significant improvements over the optimal parametric baseline, more than twice the improvements previously encountered for this task. We also extract and evaluate a DBLP dataset, wherein we predict the number of papers co-authored by two authors, and present improvements over the parametric baseline on this alternative domain as well.