 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Annotator: A framework for efficiently building video classifiers using vision-language models and active learning
Feb 09, 2024



High-quality and consistent annotations are fundamental to the successful development of robust machine learning models. Traditional data annotation methods are resource-intensive and inefficient, often leading to a reliance on third-party annotators who are not the domain experts. Hard samples, which are usually the most informative for model training, tend to be difficult to label accurately and consistently without business context. These can arise unpredictably during the annotation process, requiring a variable number of iterations and rounds of feedback, leading to unforeseen expenses and time commitments to guarantee quality. We posit that more direct involvement of domain experts, using a human-in-the-loop system, can resolve many of these practical challenges. We propose a novel framework we call Video Annotator (VA) for annotating, managing, and iterating on video classification datasets. Our approach offers a new paradigm for an end-user-centered model development process, enhancing the efficiency, usability, and effectiveness of video classifiers. Uniquely, VA allows for a continuous annotation process, seamlessly integrating data collection and model training. We leverage the zero-shot capabilities of vision-language foundation models combined with active learning techniques, and demonstrate that VA enables the efficient creation of high-quality models. VA achieves a median 6.8 point improvement in Average Precision relative to the most competitive baseline across a wide-ranging assortment of tasks. We release a dataset with 153k labels across 56 video understanding tasks annotated by three professional video editors using VA, and also release code to replicate our experiments at: http://github.com/netflix/videoannotator.
An Experience-based Direct Generation approach to Automatic Image Cropping
Dec 30, 2022Automatic Image Cropping is a challenging task with many practical downstream applications. The task is often divided into sub-problems - generating cropping candidates, finding the visually important regions, and determining aesthetics to select the most appealing candidate. Prior approaches model one or more of these sub-problems separately, and often combine them sequentially. We propose a novel convolutional neural network (CNN) based method to crop images directly, without explicitly modeling image aesthetics, evaluating multiple crop candidates, or detecting visually salient regions. Our model is trained on a large dataset of images cropped by experienced editors and can simultaneously predict bounding boxes for multiple fixed aspect ratios. We consider the aspect ratio of the cropped image to be a critical factor that influences aesthetics. Prior approaches for automatic image cropping, did not enforce the aspect ratio of the outputs, likely due to a lack of datasets for this task. We, therefore, benchmark our method on public datasets for two related tasks - first, aesthetic image cropping without regard to aspect ratio, and second, thumbnail generation that requires fixed aspect ratio outputs, but where aesthetics are not crucial. We show that our strategy is competitive with or performs better than existing methods in both these tasks. Furthermore, our one-stage model is easier to train and significantly faster than existing two-stage or end-to-end methods for inference. We present a qualitative evaluation study, and find that our model is able to generalize to diverse images from unseen datasets and often retains compositional properties of the original images after cropping. Our results demonstrate that explicitly modeling image aesthetics or visual attention regions is not necessarily required to build a competitive image cropping algorithm.
* Published in IEEE Access
PodSumm -- Podcast Audio Summarization
Sep 22, 2020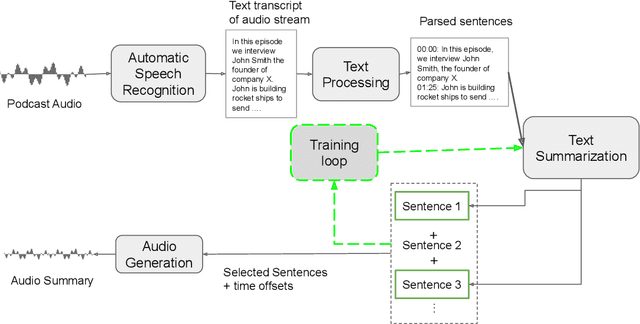
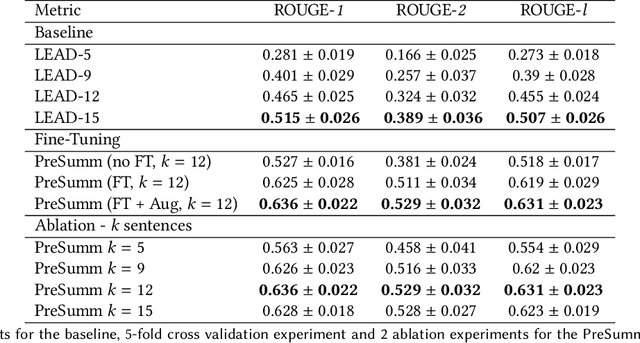
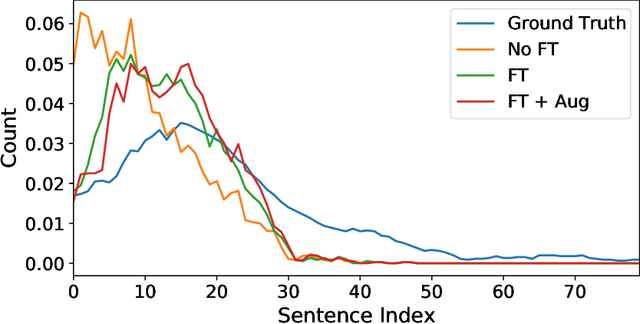
The diverse nature, scale, and specificity of podcasts present a unique challenge to content discovery systems. Listeners often rely on text descriptions of episodes provided by the podcast creators to discover new content. Some factors like the presentation style of the narrator and production quality are significant indicators of subjective user preference but are difficult to quantify and not reflected in the text descriptions provided by the podcast creators. We propose the automated creation of podcast audio summaries to aid in content discovery and help listeners to quickly preview podcast content before investing time in listening to an entire episode. In this paper, we present a method to automatically construct a podcast summary via guidance from the text-domain. Our method performs two key steps, namely, audio to text transcription and text summary generation. Motivated by a lack of datasets for this task, we curate an internal dataset, find an effective scheme for data augmentation, and design a protocol to gather summaries from annotators. We fine-tune a PreSumm[10] model with our augmented dataset and perform an ablation study. Our method achieves ROUGE-F(1/2/L) scores of 0.63/0.53/0.63 on our dataset. We hope these results may inspire future research in this direction.