 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterated Piecewise Affine (IPA) Approximation for Language Modeling
Jun 21, 2023In this work, we demonstrate the application of a simple first-order Taylor expansion to approximate a generic function $F: R^{n \times m} \to R^{n \times m}$ and utilize it in language modeling. To enhance the basic Taylor expansion, we introduce iteration and piecewise modeling, leading us to name the algorithm the Iterative Piecewise Affine (IPA) approximation. The final algorithm exhibits interesting resemblances to the Transformers decoder architecture. By comparing parameter arrangements in IPA and Transformers, we observe a strikingly similar performance, with IPA outperforming Transformers by 1.5\% in the next token prediction task with cross-entropy loss for smaller sequence lengths.
LACoS-BLOOM: Low-rank Adaptation with Contrastive objective on 8 bits Siamese-BLOOM
May 10, 2023Text embeddings are useful features for several NLP applications, such as sentence similarity, text clustering, and semantic search. In this paper, we present a Low-rank Adaptation with a Contrastive objective on top of 8-bit Siamese-BLOOM, a multilingual large language model optimized to produce semantically meaningful word embeddings. The innovation is threefold. First, we cast BLOOM weights to 8-bit values. Second, we fine-tune BLOOM with a scalable adapter (LoRA) and 8-bit Adam optimizer for sentence similarity classification. Third, we apply a Siamese architecture on BLOOM model with a contrastive objective to ease the multi-lingual labeled data scarcity. The experiment results show the quality of learned embeddings from LACoS-BLOOM is proportional to the number of model parameters and the amount of unlabeled training data. With the parameter efficient fine-tuning design, we are able to run BLOOM 7.1 billion parameters end-to-end on a single GPU machine with 32GB memory. Compared to previous solution Sentence-BERT, we achieve significant improvement on both English and multi-lingual STS tasks.
Providing Insights for Open-Response Surveys via End-to-End Context-Aware Clustering
Mar 02, 2022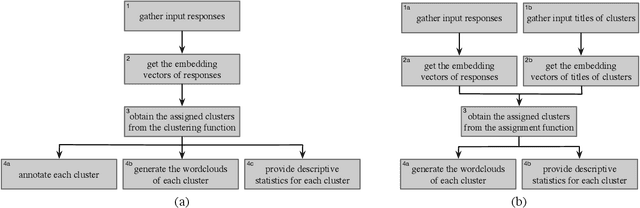


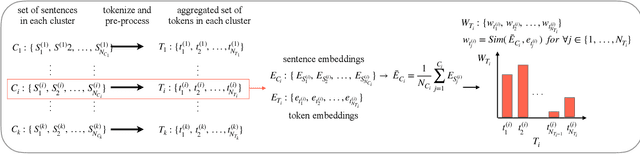
Teachers often conduct surveys in order to collect data from a predefined group of students to gain insights into topics of interest. When analyzing surveys with open-ended textual responses, it is extremely time-consuming, labor-intensive, and difficult to manually process all the responses into an insightful and comprehensive report. In the analysis step, traditionally, the teacher has to read each of the responses and decide on how to group them in order to extract insightful information. Even though it is possible to group the responses only using certain keywords, such an approach would be limited since it not only fails to account for embedded contexts but also cannot detect polysemous words or phrases and semantics that are not expressible in single words. In this work, we present a novel end-to-end context-aware framework that extracts, aggregates, and abbreviates embedded semantic patterns in open-response survey data. Our framework relies on a pre-trained natural language model in order to encode the textual data into semantic vectors. The encoded vectors then get clustered either into an optimally tuned number of groups or into a set of groups with pre-specified titles. In the former case, the clusters are then further analyzed to extract a representative set of keywords or summary sentences that serve as the labels of the clusters. In our framework, for the designated clusters, we finally provide context-aware wordclouds that demonstrate the semantically prominent keywords within each group. Honoring user privacy, we have successfully built the on-device implementation of our framework suitable for real-time analysis on mobile devices and have tested it on a synthetic dataset. Our framework reduces the costs at-scale by automating the process of extracting the most insightful information pieces from survey data.
Improving Retrieval Modeling Using Cross Convolution Networks And Multi Frequency Word Embedding
Feb 16, 2018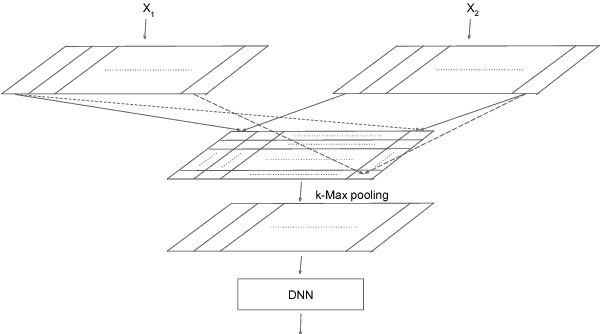
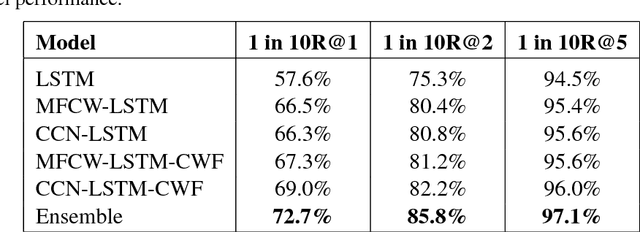
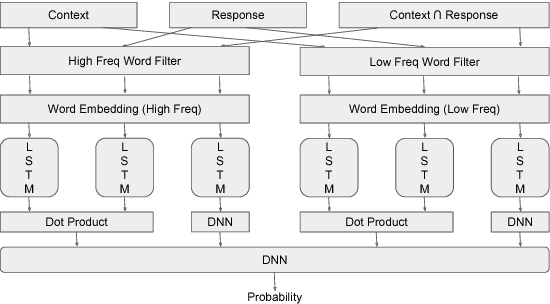
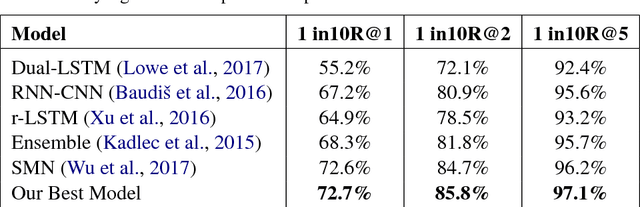
To build a satisfying chatbot that has the ability of managing a goal-oriented multi-turn dialogue, accurate modeling of human conversation is crucial. In this paper we concentrate on the task of response selection for multi-turn human-computer conversation with a given context. Previous approaches show weakness in capturing information of rare keywords that appear in either or both context and correct response, and struggle with long input sequences. We propose Cross Convolution Network (CCN) and Multi Frequency word embedding to address both problems. We train several models using the Ubuntu Dialogue dataset which is the largest freely available multi-turn based dialogue corpus. We further build an ensemble model by averaging predictions of multiple models. We achieve a new state-of-the-art on this dataset with considerable improvements compared to previous best results.