 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Retrieval Modeling Using Cross Convolution Networks And Multi Frequency Word Embedding
Paper and Code
Feb 16, 2018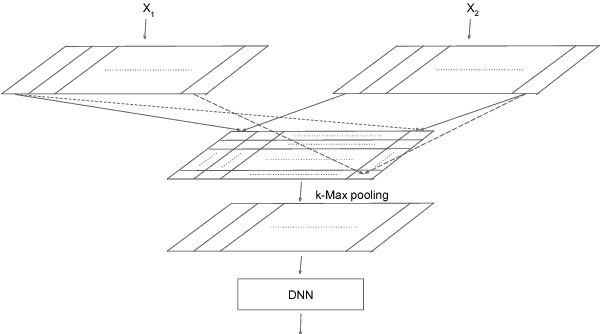
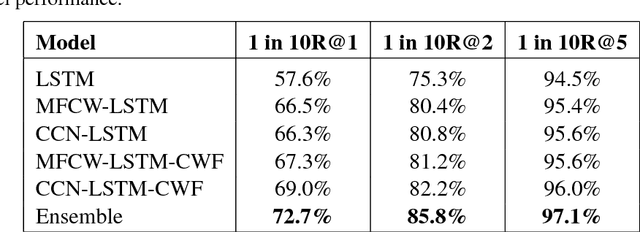
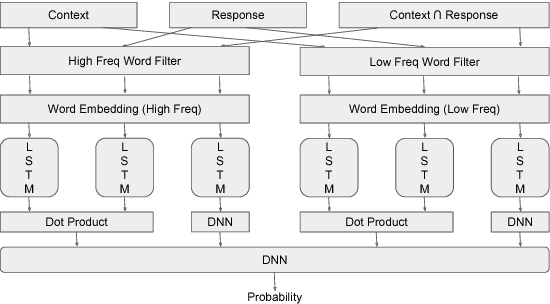
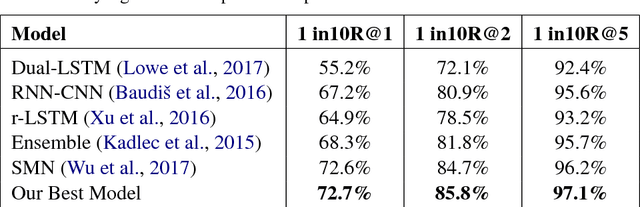
To build a satisfying chatbot that has the ability of managing a goal-oriented multi-turn dialogue, accurate modeling of human conversation is crucial. In this paper we concentrate on the task of response selection for multi-turn human-computer conversation with a given context. Previous approaches show weakness in capturing information of rare keywords that appear in either or both context and correct response, and struggle with long input sequences. We propose Cross Convolution Network (CCN) and Multi Frequency word embedding to address both problems. We train several models using the Ubuntu Dialogue dataset which is the largest freely available multi-turn based dialogue corpus. We further build an ensemble model by averaging predictions of multiple models. We achieve a new state-of-the-art on this dataset with considerable improvements compared to previous best results.