 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestioning the Stability of Visual Question Answering
Nov 14, 2025Visual Language Models (VLMs) have achieved remarkable progress, yet their reliability under small, meaning-preserving input changes remains poorly understood. We present the first large-scale, systematic study of VLM robustness to benign visual and textual perturbations: pixel-level shifts, light geometric transformations, padded rescaling, paraphrasing, and multilingual rewrites that do not alter the underlying semantics of an image-question pair. Across a broad set of models and datasets, we find that modern VLMs are highly sensitive to such minor perturbations: a substantial fraction of samples change their predicted answer under at least one visual or textual modification. We characterize how this instability varies across perturbation types, question categories, and models, revealing that even state-of-the-art systems (e.g., GPT-4o, Gemini 2.0 Flash) frequently fail under shifts as small as a few pixels or harmless rephrasings. We further show that sample-level stability serves as a strong indicator of correctness: stable samples are consistently far more likely to be answered correctly. Leveraging this, we demonstrate that the stability patterns of small, accessible open-source models can be used to predict the correctness of much larger closed-source models with high precision. Our findings expose a fundamental fragility in current VLMs and highlight the need for robustness evaluations that go beyond adversarial perturbations, focusing instead on invariances that models should reliably uphold.
UmbraTTS: Adapting Text-to-Speech to Environmental Contexts with Flow Matching
Jun 11, 2025Recent advances in Text-to-Speech (TTS) have enabled highly natural speech synthesis, yet integrating speech with complex background environments remains challenging. We introduce UmbraTTS, a flow-matching based TTS model that jointly generates both speech and environmental audio, conditioned on text and acoustic context. Our model allows fine-grained control over background volume and produces diverse, coherent, and context-aware audio scenes. A key challenge is the lack of data with speech and background audio aligned in natural context. To overcome the lack of paired training data, we propose a self-supervised framework that extracts speech, background audio, and transcripts from unannotated recordings. Extensive evaluations demonstrate that UmbraTTS significantly outperformed existing baselines, producing natural, high-quality, environmentally aware audios.
Few-Shot Speech Deepfake Detection Adaptation with Gaussian Processes
May 29, 2025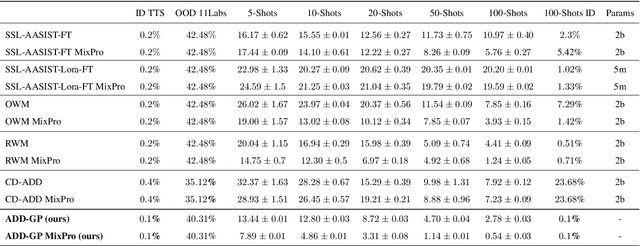

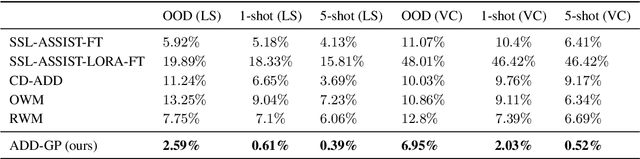
Recent advancements in Text-to-Speech (TTS) models, particularly in voice cloning, have intensified the demand for adaptable and efficient deepfake detection methods. As TTS systems continue to evolve, detection models must be able to efficiently adapt to previously unseen generation models with minimal data. This paper introduces ADD-GP, a few-shot adaptive framework based on a Gaussian Process (GP) classifier for Audio Deepfake Detection (ADD). We show how the combination of a powerful deep embedding model with the Gaussian processes flexibility can achieve strong performance and adaptability. Additionally, we show this approach can also be used for personalized detection, with greater robustness to new TTS models and one-shot adaptability. To support our evaluation, a benchmark dataset is constructed for this task using new state-of-the-art voice cloning models.
FlowTSE: Target Speaker Extraction with Flow Matching
May 20, 2025Target speaker extraction (TSE) aims to isolate a specific speaker's speech from a mixture using speaker enrollment as a reference. While most existing approaches are discriminative, recent generative methods for TSE achieve strong results. However, generative methods for TSE remain underexplored, with most existing approaches relying on complex pipelines and pretrained components, leading to computational overhead. In this work, we present FlowTSE, a simple yet effective TSE approach based on conditional flow matching. Our model receives an enrollment audio sample and a mixed speech signal, both represented as mel-spectrograms, with the objective of extracting the target speaker's clean speech. Furthermore, for tasks where phase reconstruction is crucial, we propose a novel vocoder conditioned on the complex STFT of the mixed signal, enabling improved phase estimation. Experimental results on standard TSE benchmarks show that FlowTSE matches or outperforms strong baselines.
Keyword-Guided Adaptation of Automatic Speech Recognition
Jun 04, 2024



Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
Multi Task Inverse Reinforcement Learning for Common Sense Reward
Feb 17, 2024One of the challenges in applying reinforcement learning in a complex real-world environment lies in providing the agent with a sufficiently detailed reward function. Any misalignment between the reward and the desired behavior can result in unwanted outcomes. This may lead to issues like "reward hacking" where the agent maximizes rewards by unintended behavior. In this work, we propose to disentangle the reward into two distinct parts. A simple task-specific reward, outlining the particulars of the task at hand, and an unknown common-sense reward, indicating the expected behavior of the agent within the environment. We then explore how this common-sense reward can be learned from expert demonstrations. We first show that inverse reinforcement learning, even when it succeeds in training an agent, does not learn a useful reward function. That is, training a new agent with the learned reward does not impair the desired behaviors. We then demonstrate that this problem can be solved by training simultaneously on multiple tasks. That is, multi-task inverse reinforcement learning can be applied to learn a useful reward function.
Combining Language Models For Specialized Domains: A Colorful Approach
Nov 01, 2023


General purpose language models (LMs) encounter difficulties when processing domain-specific jargon and terminology, which are frequently utilized in specialized fields such as medicine or industrial settings. Moreover, they often find it challenging to interpret mixed speech that blends general language with specialized jargon. This poses a challenge for automatic speech recognition systems operating within these specific domains. In this work, we introduce a novel approach that integrates domain-specific or secondary LM into general-purpose LM. This strategy involves labeling, or "coloring", each word to indicate its association with either the general or the domain-specific LM. We develop an optimized algorithm that enhances the beam search algorithm to effectively handle inferences involving colored words. Our evaluations indicate that this approach is highly effective in integrating jargon into language tasks. Notably, our method substantially lowers the error rate for domain-specific words without compromising performance in the general domain.
Open-vocabulary Keyword-spotting with Adaptive Instance Normalization
Sep 13, 2023



Open vocabulary keyword spotting is a crucial and challenging task in automatic speech recognition (ASR) that focuses on detecting user-defined keywords within a spoken utterance. Keyword spotting methods commonly map the audio utterance and keyword into a joint embedding space to obtain some affinity score. In this work, we propose AdaKWS, a novel method for keyword spotting in which a text encoder is trained to output keyword-conditioned normalization parameters. These parameters are used to process the auditory input. We provide an extensive evaluation using challenging and diverse multi-lingual benchmarks and show significant improvements over recent keyword spotting and ASR baselines. Furthermore, we study the effectiveness of our approach on low-resource languages that were unseen during the training. The results demonstrate a substantial performance improvement compared to baseline methods.
Auxiliary Learning as an Asymmetric Bargaining Game
Jan 31, 2023



Auxiliary learning is an effective method for enhancing the generalization capabilities of trained models, particularly when dealing with small datasets. However, this approach may present several difficulties: (i) optimizing multiple objectives can be more challenging, and (ii) how to balance the auxiliary tasks to best assist the main task is unclear. In this work, we propose a novel approach, named AuxiNash, for balancing tasks in auxiliary learning by formalizing the problem as generalized bargaining game with asymmetric task bargaining power. Furthermore, we describe an efficient procedure for learning the bargaining power of tasks based on their contribution to the performance of the main task and derive theoretical guarantees for its convergence. Finally, we evaluate AuxiNash on multiple multi-task benchmarks and find that it consistently outperforms competing methods.