 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUmbraTTS: Adapting Text-to-Speech to Environmental Contexts with Flow Matching
Jun 11, 2025Recent advances in Text-to-Speech (TTS) have enabled highly natural speech synthesis, yet integrating speech with complex background environments remains challenging. We introduce UmbraTTS, a flow-matching based TTS model that jointly generates both speech and environmental audio, conditioned on text and acoustic context. Our model allows fine-grained control over background volume and produces diverse, coherent, and context-aware audio scenes. A key challenge is the lack of data with speech and background audio aligned in natural context. To overcome the lack of paired training data, we propose a self-supervised framework that extracts speech, background audio, and transcripts from unannotated recordings. Extensive evaluations demonstrate that UmbraTTS significantly outperformed existing baselines, producing natural, high-quality, environmentally aware audios.
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022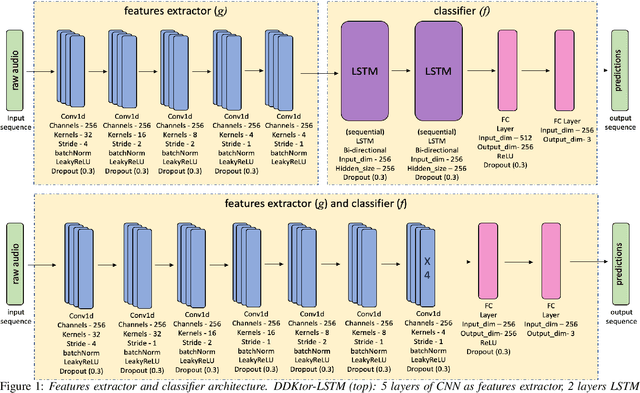
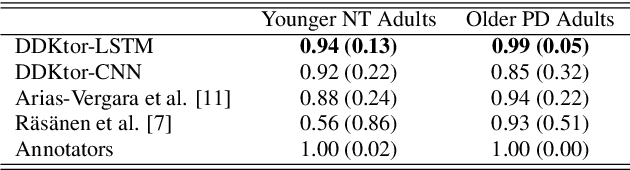
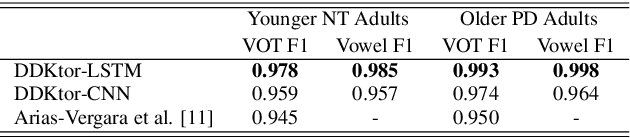
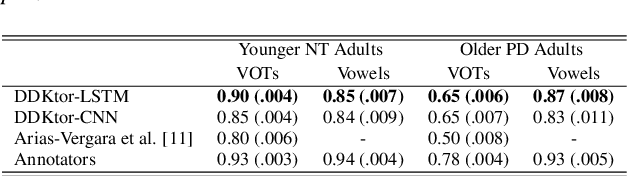
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.
DeepFry: Identifying Vocal Fry Using Deep Neural Networks
Mar 31, 2022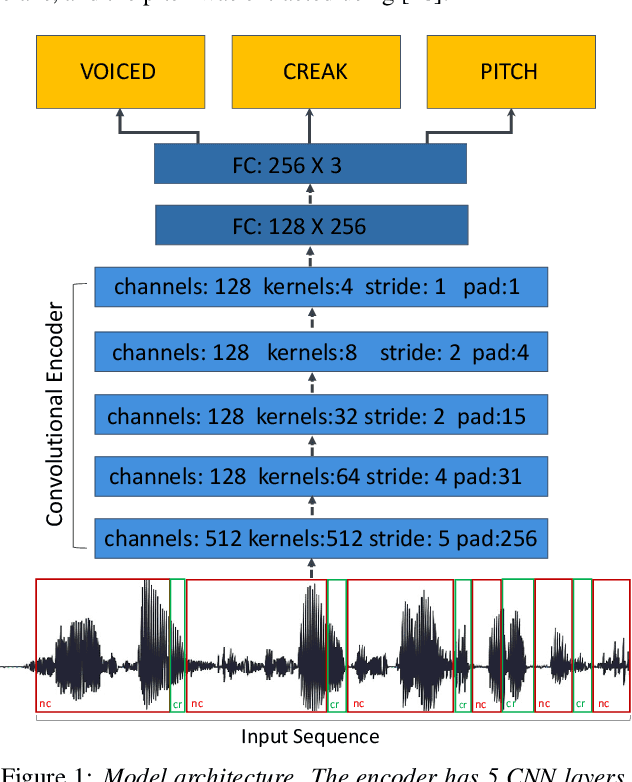
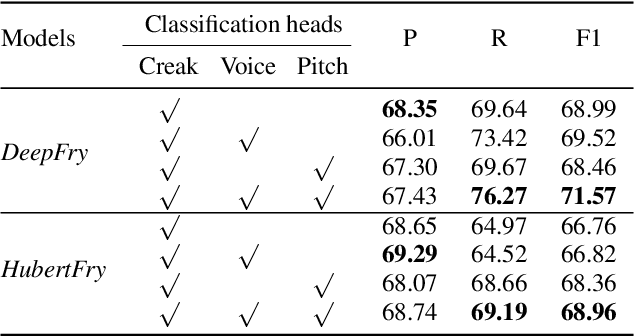

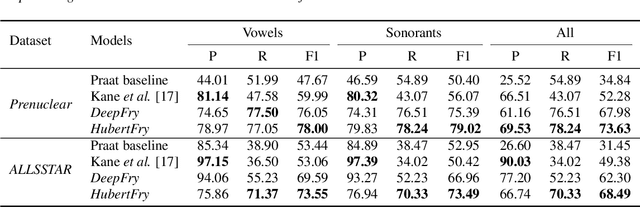
Vocal fry or creaky voice refers to a voice quality characterized by irregular glottal opening and low pitch. It occurs in diverse languages and is prevalent in American English, where it is used not only to mark phrase finality, but also sociolinguistic factors and affect. Due to its irregular periodicity, creaky voice challenges automatic speech processing and recognition systems, particularly for languages where creak is frequently used. This paper proposes a deep learning model to detect creaky voice in fluent speech. The model is composed of an encoder and a classifier trained together. The encoder takes the raw waveform and learns a representation using a convolutional neural network. The classifier is implemented as a multi-headed fully-connected network trained to detect creaky voice, voicing, and pitch, where the last two are used to refine creak prediction. The model is trained and tested on speech of American English speakers, annotated for creak by trained phoneticians. We evaluated the performance of our system using two encoders: one is tailored for the task, and the other is based on a state-of-the-art unsupervised representation. Results suggest our best-performing system has improved recall and F1 scores compared to previous methods on unseen data.
CNN-based Spoken Term Detection and Localization without Dynamic Programming
Mar 07, 2021

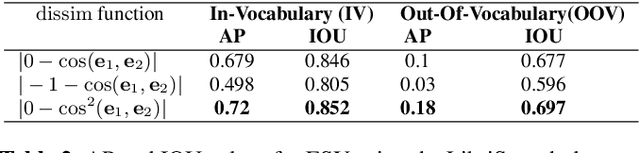

In this paper, we propose a spoken term detection algorithm for simultaneous prediction and localization of in-vocabulary and out-of-vocabulary terms within an audio segment. The proposed algorithm infers whether a term was uttered within a given speech signal or not by predicting the word embeddings of various parts of the speech signal and comparing them to the word embedding of the desired term. The algorithm utilizes an existing embedding space for this task and does not need to train a task-specific embedding space. At inference the algorithm simultaneously predicts all possible locations of the target term and does not need dynamic programming for optimal search. We evaluate our system on several spoken term detection tasks on read speech corpora.
SpeechYOLO: Detection and Localization of Speech Objects
Apr 14, 2019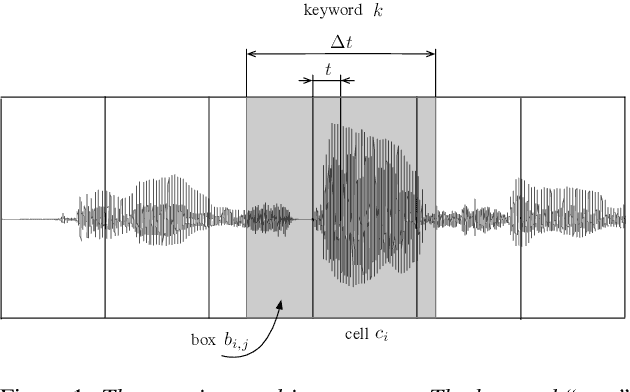
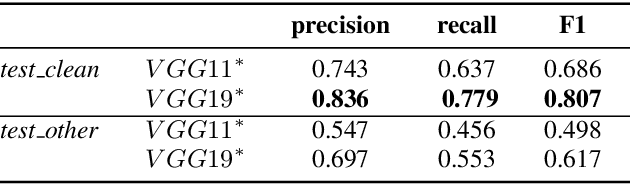

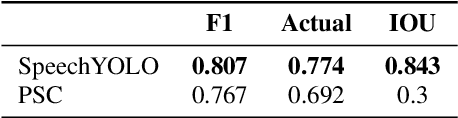
In this paper, we propose to apply object detection methods from the vision domain on the speech recognition domain, by treating audio fragments as objects. More specifically, we present SpeechYOLO, which is inspired by the YOLO algorithm for object detection in images. The goal of SpeechYOLO is to localize boundaries of utterances within the input signal, and to correctly classify them. Our system is composed of a convolutional neural network, with a simple least-mean-squares loss function. We evaluated the system on several keyword spotting tasks, that include corpora of read speech and spontaneous speech. Our system compares favorably with other algorithms trained for both localization and classification.