 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Head Segmentation of MRI with Abnormal Brain Anatomy: Model and Data Release
Jan 30, 2025



The goal of this work was to develop a deep network for whole-head segmentation, including clinical MRIs with abnormal anatomy, and compile the first public benchmark dataset for this purpose. We collected 91 MRIs with volumetric segmentation labels for a diverse set of human subjects (4 normal, 32 traumatic brain injuries, and 57 strokes). These clinical cases are characterized by extended cerebrospinal fluid (CSF) in regions normally containing the brain. Training labels were generated by manually correcting initial automated segmentations for skin/scalp, skull, CSF, gray matter, white matter, air cavity, and extracephalic air. We developed a MultiAxial network consisting of three 2D U-Net models that operate independently in sagittal, axial, and coronal planes and are then combined to produce a single 3D segmentation. The MultiAxial network achieved test-set Dice scores of 0.88 (median plus-minus 0.04). For brain tissue, it significantly outperforms existing brain segmentation methods (MultiAxial: 0.898 plus-minus 0.041, SynthSeg: 0.758 plus-minus 0.054, BrainChop: 0.757 plus-minus 0.125). The MultiAxial network gains in robustness by avoiding the need for coregistration with an atlas. It performed well in regions with abnormal anatomy and on images that have been de-identified. It enables more robust current flow modeling when incorporated into ROAST, a widely-used modeling toolbox for transcranial electric stimulation. We are releasing a state-of-the-art model for whole-head MRI segmentation, along with a dataset of 61 clinical MRIs and training labels, including non-brain structures. Together, the model and data may serve as a benchmark for future efforts.
EEG-Based Analysis of Brain Responses in Multi-Modal Human-Robot Interaction: Modulating Engagement
Nov 27, 2024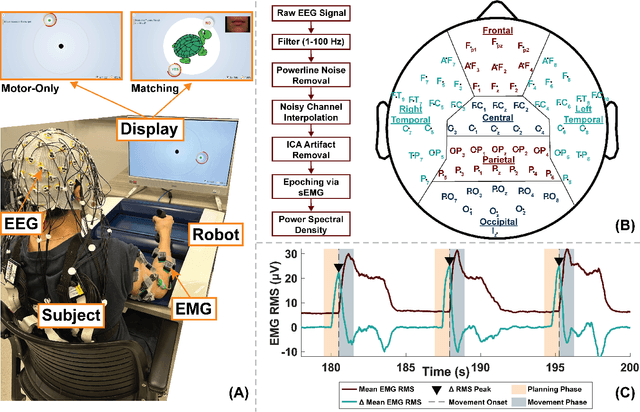
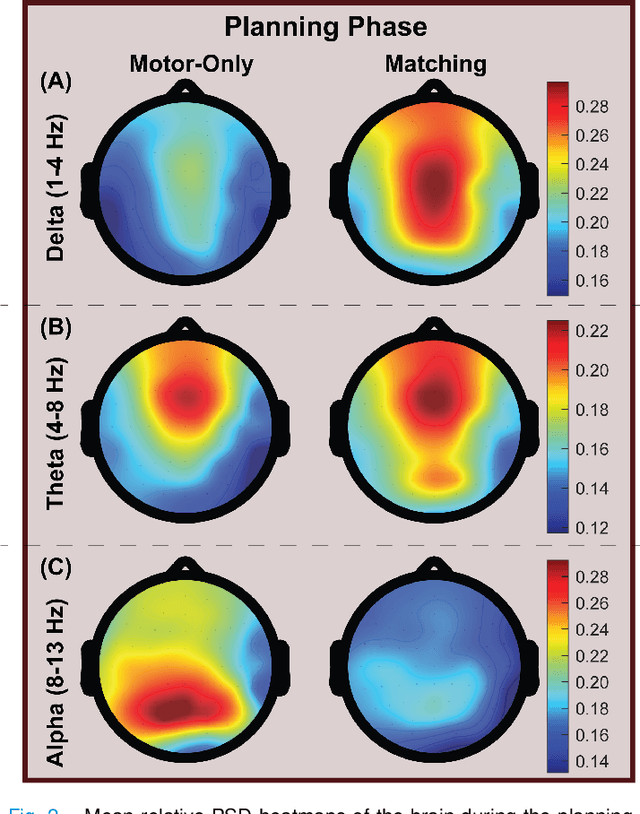
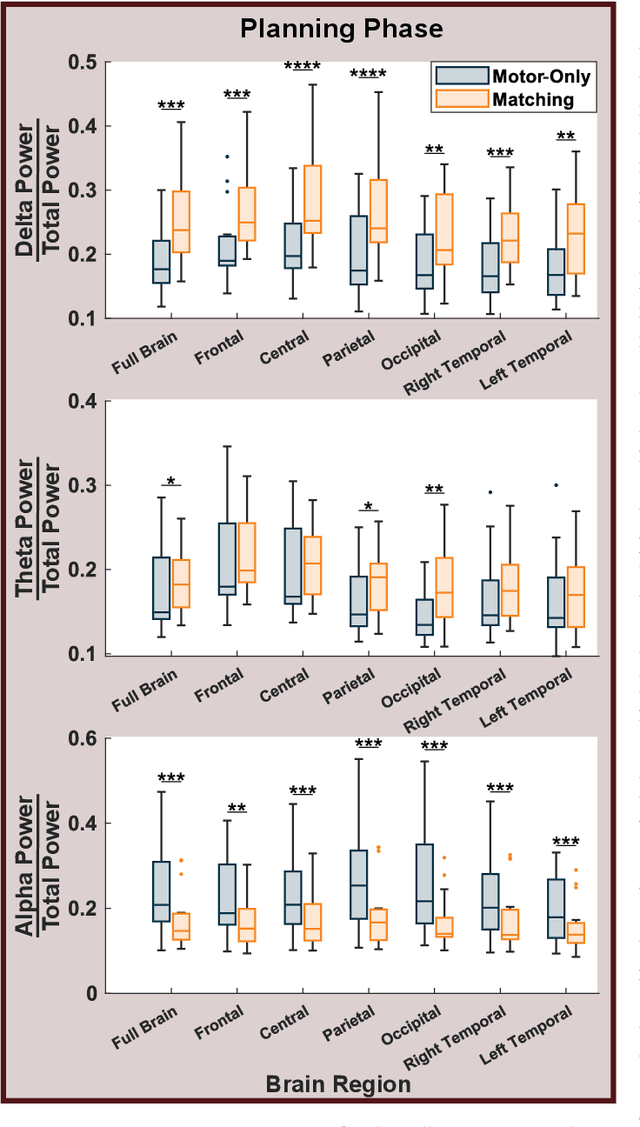
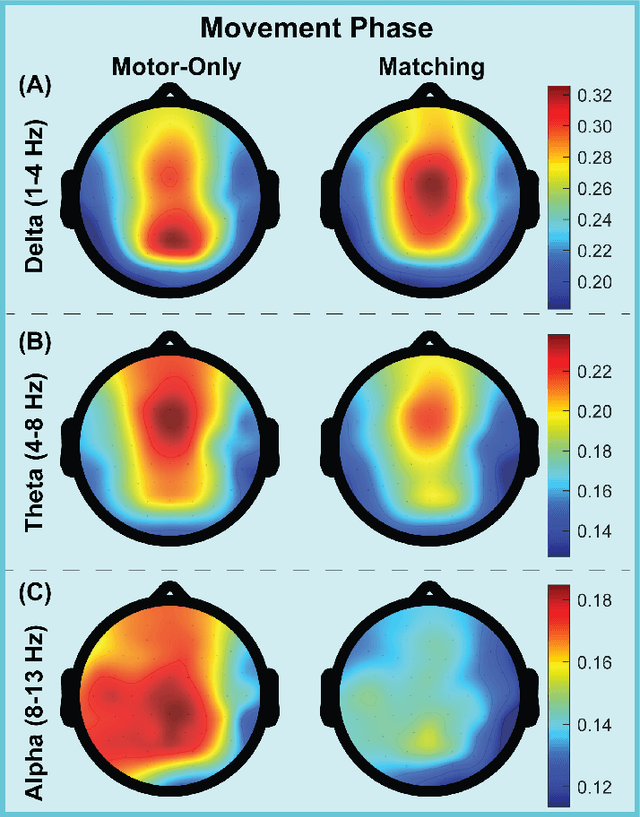
User engagement, cognitive participation, and motivation during task execution in physical human-robot interaction are crucial for motor learning. These factors are especially important in contexts like robotic rehabilitation, where neuroplasticity is targeted. However, traditional robotic rehabilitation systems often face challenges in maintaining user engagement, leading to unpredictable therapeutic outcomes. To address this issue, various techniques, such as assist-as-needed controllers, have been developed to prevent user slacking and encourage active participation. In this paper, we introduce a new direction through a novel multi-modal robotic interaction designed to enhance user engagement by synergistically integrating visual, motor, cognitive, and auditory (speech recognition) tasks into a single, comprehensive activity. To assess engagement quantitatively, we compared multiple electroencephalography (EEG) biomarkers between this multi-modal protocol and a traditional motor-only protocol. Fifteen healthy adult participants completed 100 trials of each task type. Our findings revealed that EEG biomarkers, particularly relative alpha power, showed statistically significant improvements in engagement during the multi-modal task compared to the motor-only task. Moreover, while engagement decreased over time in the motor-only task, the multi-modal protocol maintained consistent engagement, suggesting that users could remain engaged for longer therapy sessions. Our observations on neural responses during interaction indicate that the proposed multi-modal approach can effectively enhance user engagement, which is critical for improving outcomes. This is the first time that objective neural response highlights the benefit of a comprehensive robotic intervention combining motor, cognitive, and auditory functions in healthy subjects.
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022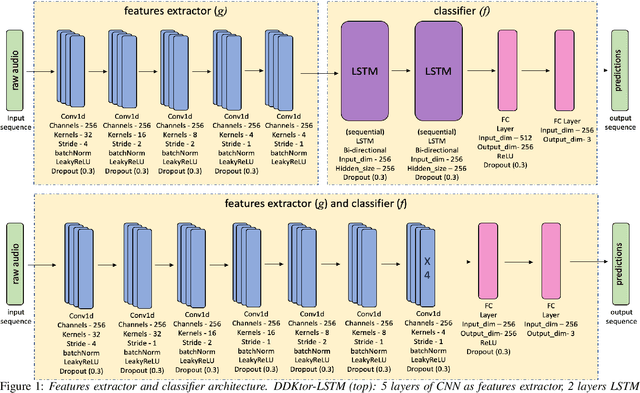
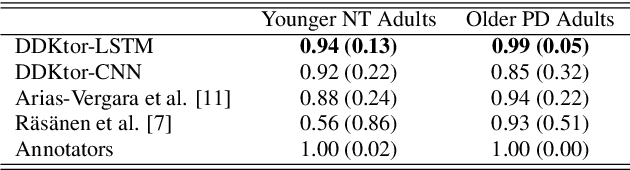
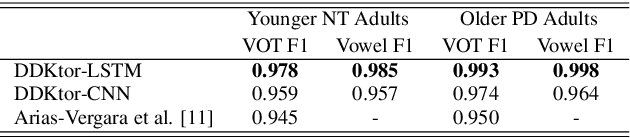
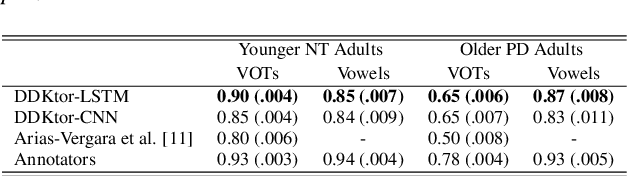
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.