 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Word Segmentation Using Temporal Gradient Pseudo-Labels
Mar 30, 2023


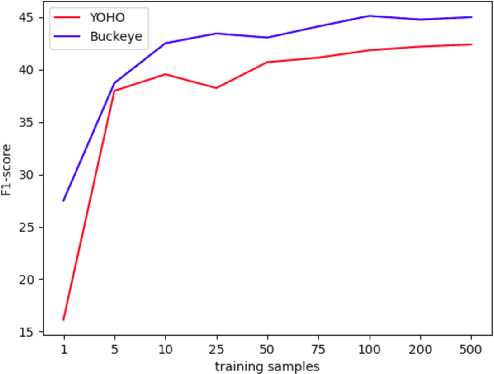
Unsupervised word segmentation in audio utterances is challenging as, in speech, there is typically no gap between words. In a preliminary experiment, we show that recent deep self-supervised features are very effective for word segmentation but require supervision for training the classification head. To extend their effectiveness to unsupervised word segmentation, we propose a pseudo-labeling strategy. Our approach relies on the observation that the temporal gradient magnitude of the embeddings (i.e. the distance between the embeddings of subsequent frames) is typically minimal far from the boundaries and higher nearer the boundaries. We use a thresholding function on the temporal gradient magnitude to define a psuedo-label for wordness. We train a linear classifier, mapping the embedding of a single frame to the pseudo-label. Finally, we use the classifier score to predict whether a frame is a word or a boundary. In an empirical investigation, our method, despite its simplicity and fast run time, is shown to significantly outperform all previous methods on two datasets.
THOR: Threshold-Based Ranking Loss for Ordinal Regression
May 10, 2022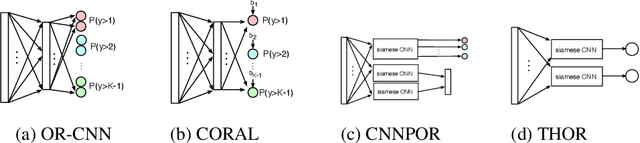
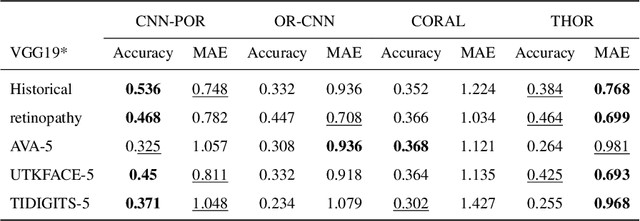

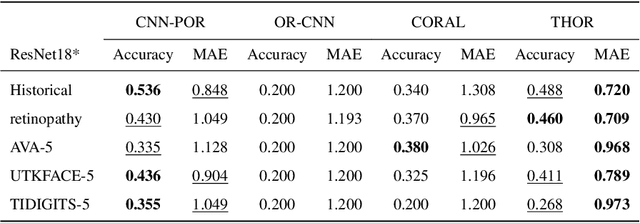
In this work, we present a regression-based ordinal regression algorithm for supervised classification of instances into ordinal categories. In contrast to previous methods, in this work the decision boundaries between categories are predefined, and the algorithm learns to project the input examples onto their appropriate scores according to these predefined boundaries. This is achieved by adding a novel threshold-based pairwise loss function that aims at minimizing the regression error, which in turn minimizes the Mean Absolute Error (MAE) measure. We implemented our proposed architecture-agnostic method using the CNN-framework for feature extraction. Experimental results on five real-world benchmarks demonstrate that the proposed algorithm achieves the best MAE results compared to state-of-the-art ordinal regression algorithms.
Unsupervised Word Segmentation using K Nearest Neighbors
Apr 27, 2022
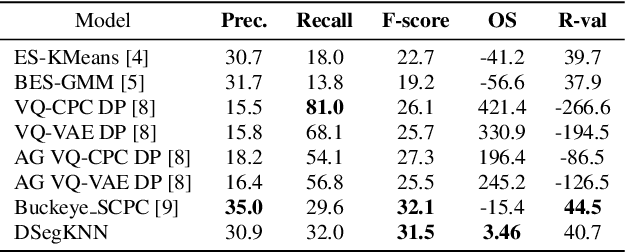
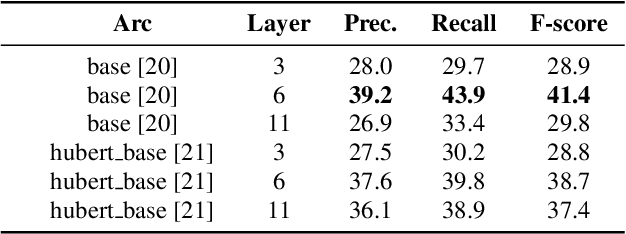

In this paper, we propose an unsupervised kNN-based approach for word segmentation in speech utterances. Our method relies on self-supervised pre-trained speech representations, and compares each audio segment of a given utterance to its K nearest neighbors within the training set. Our main assumption is that a segment containing more than one word would occur less often than a segment containing a single word. Our method does not require phoneme discovery and is able to operate directly on pre-trained audio representations. This is in contrast to current methods that use a two-stage approach; first detecting the phonemes in the utterance and then detecting word-boundaries according to statistics calculated on phoneme patterns. Experiments on two datasets demonstrate improved results over previous single-stage methods and competitive results on state-of-the-art two-stage methods.
CNN-based Spoken Term Detection and Localization without Dynamic Programming
Mar 07, 2021

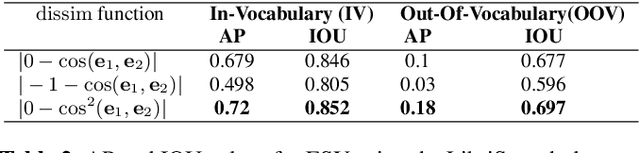

In this paper, we propose a spoken term detection algorithm for simultaneous prediction and localization of in-vocabulary and out-of-vocabulary terms within an audio segment. The proposed algorithm infers whether a term was uttered within a given speech signal or not by predicting the word embeddings of various parts of the speech signal and comparing them to the word embedding of the desired term. The algorithm utilizes an existing embedding space for this task and does not need to train a task-specific embedding space. At inference the algorithm simultaneously predicts all possible locations of the target term and does not need dynamic programming for optimal search. We evaluate our system on several spoken term detection tasks on read speech corpora.
SpeechYOLO: Detection and Localization of Speech Objects
Apr 14, 2019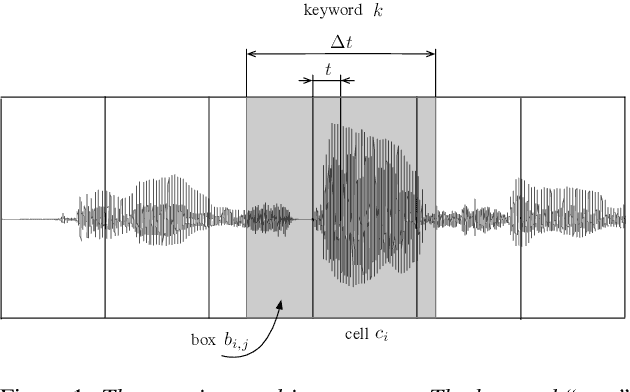
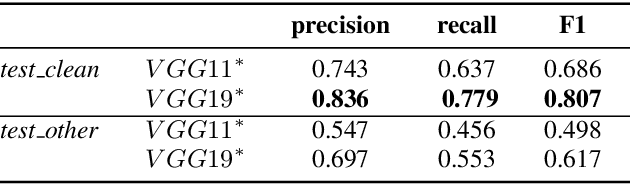

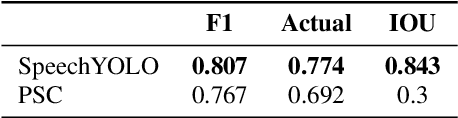
In this paper, we propose to apply object detection methods from the vision domain on the speech recognition domain, by treating audio fragments as objects. More specifically, we present SpeechYOLO, which is inspired by the YOLO algorithm for object detection in images. The goal of SpeechYOLO is to localize boundaries of utterances within the input signal, and to correctly classify them. Our system is composed of a convolutional neural network, with a simple least-mean-squares loss function. We evaluated the system on several keyword spotting tasks, that include corpora of read speech and spontaneous speech. Our system compares favorably with other algorithms trained for both localization and classification.