 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Word Segmentation Using Temporal Gradient Pseudo-Labels
Paper and Code



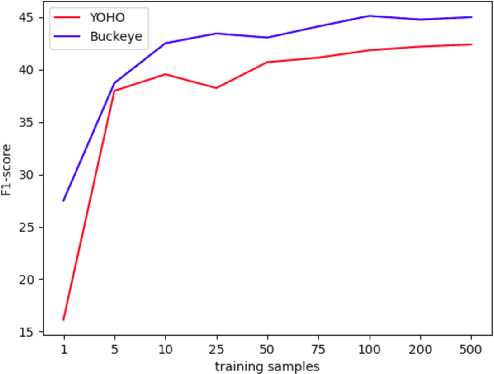
Unsupervised word segmentation in audio utterances is challenging as, in speech, there is typically no gap between words. In a preliminary experiment, we show that recent deep self-supervised features are very effective for word segmentation but require supervision for training the classification head. To extend their effectiveness to unsupervised word segmentation, we propose a pseudo-labeling strategy. Our approach relies on the observation that the temporal gradient magnitude of the embeddings (i.e. the distance between the embeddings of subsequent frames) is typically minimal far from the boundaries and higher nearer the boundaries. We use a thresholding function on the temporal gradient magnitude to define a psuedo-label for wordness. We train a linear classifier, mapping the embedding of a single frame to the pseudo-label. Finally, we use the classifier score to predict whether a frame is a word or a boundary. In an empirical investigation, our method, despite its simplicity and fast run time, is shown to significantly outperform all previous methods on two datasets.