 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Classification with Secret Vector Machines
Jul 08, 2019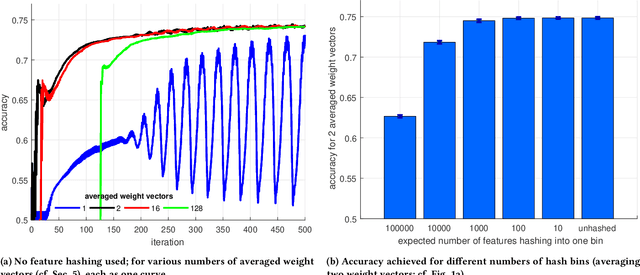


Today, large amounts of valuable data are distributed among millions of user-held devices, such as personal computers, phones, or Internet-of-things devices. Many companies collect such data with the goal of using it for training machine learning models allowing them to improve their services. However, user-held data is often sensitive, and collecting it is problematic in terms of privacy. We address this issue by proposing a novel way of training a supervised classifier in a distributed setting akin to the recently proposed federated learning paradigm (McMahan et al. 2017), but under the stricter privacy requirement that the server that trains the model is assumed to be untrusted and potentially malicious; we thus preserve user privacy by design, rather than by trust. In particular, our framework, called secret vector machine (SecVM), provides an algorithm for training linear support vector machines (SVM) in a setting in which data-holding clients communicate with an untrusted server by exchanging messages designed to not reveal any personally identifiable information. We evaluate our model in two ways. First, in an offline evaluation, we train SecVM to predict user gender from tweets, showing that we can preserve user privacy without sacrificing classification performance. Second, we implement SecVM's distributed framework for the Cliqz web browser and deploy it for predicting user gender in a large-scale online evaluation with thousands of clients, outperforming baselines by a large margin and thus showcasing that SecVM is practicable in production environments. Overall, this work demonstrates the feasibility of machine learning on data from thousands of users without collecting any personal data. We believe this is an innovative approach that will help reconcile machine learning with data privacy.
Divide and Conquer: Partitioning Online Social Networks
May 29, 2009



Online Social Networks (OSNs) have exploded in terms of scale and scope over the last few years. The unprecedented growth of these networks present challenges in terms of system design and maintenance. One way to cope with this is by partitioning such large networks and assigning these partitions to different machines. However, social networks possess unique properties that make the partitioning problem non-trivial. The main contribution of this paper is to understand different properties of social networks and how these properties can guide the choice of a partitioning algorithm. Using large scale measurements representing real OSNs, we first characterize different properties of social networks, and then we evaluate qualitatively different partitioning methods that cover the design space. We expose different trade-offs involved and understand them in light of properties of social networks. We show that a judicious choice of a partitioning scheme can help improve performance.