 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Images to Sentiment Adjective Noun Pairs with Factorized Neural Nets
Paper and Code
Nov 21, 2015
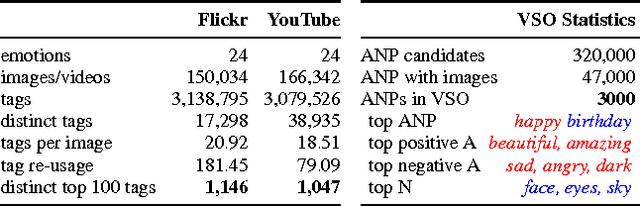

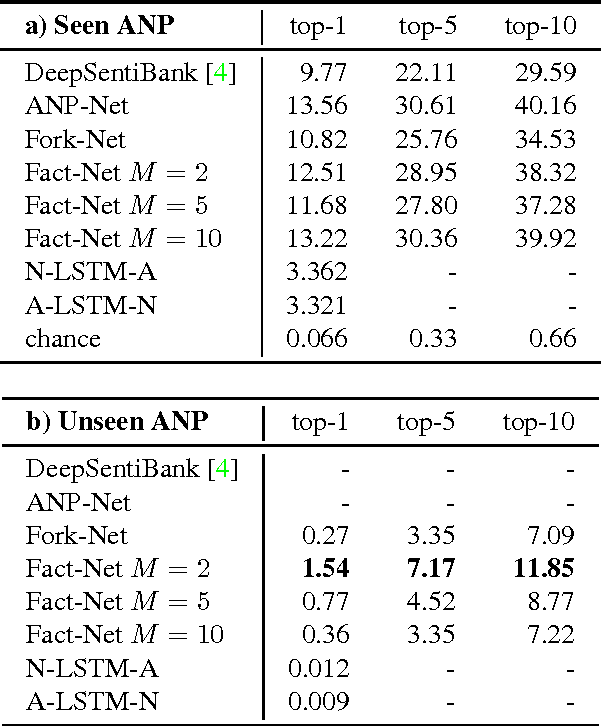
We consider the visual sentiment task of mapping an image to an adjective noun pair (ANP) such as "cute baby". To capture the two-factor structure of our ANP semantics as well as to overcome annotation noise and ambiguity, we propose a novel factorized CNN model which learns separate representations for adjectives and nouns but optimizes the classification performance over their product. Our experiments on the publicly available SentiBank dataset show that our model significantly outperforms not only independent ANP classifiers on unseen ANPs and on retrieving images of novel ANPs, but also image captioning models which capture word semantics from co-occurrence of natural text; the latter turn out to be surprisingly poor at capturing the sentiment evoked by pure visual experience. That is, our factorized ANP CNN not only trains better from noisy labels, generalizes better to new images, but can also expands the ANP vocabulary on its own.