 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
Symbolic Regression via Neural-Guided Genetic Programming Population Seeding
Nov 17, 2021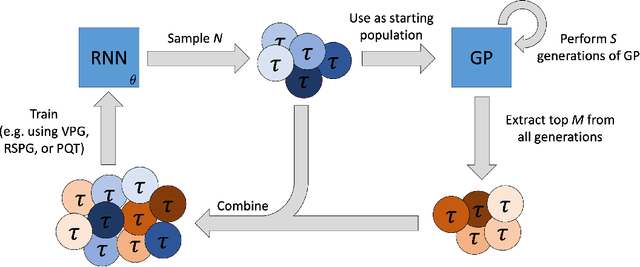

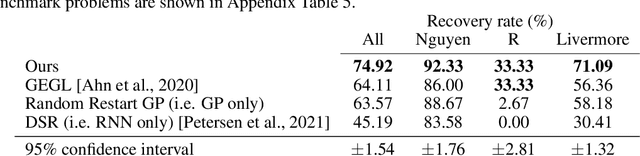
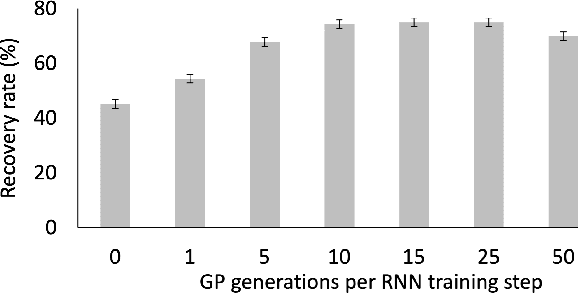
Symbolic regression is the process of identifying mathematical expressions that fit observed output from a black-box process. It is a discrete optimization problem generally believed to be NP-hard. Prior approaches to solving the problem include neural-guided search (e.g. using reinforcement learning) and genetic programming. In this work, we introduce a hybrid neural-guided/genetic programming approach to symbolic regression and other combinatorial optimization problems. We propose a neural-guided component used to seed the starting population of a random restart genetic programming component, gradually learning better starting populations. On a number of common benchmark tasks to recover underlying expressions from a dataset, our method recovers 65% more expressions than a recently published top-performing model using the same experimental setup. We demonstrate that running many genetic programming generations without interdependence on the neural-guided component performs better for symbolic regression than alternative formulations where the two are more strongly coupled. Finally, we introduce a new set of 22 symbolic regression benchmark problems with increased difficulty over existing benchmarks. Source code is provided at www.github.com/brendenpetersen/deep-symbolic-optimization.
Explaining neural network predictions of material strength
Nov 05, 2021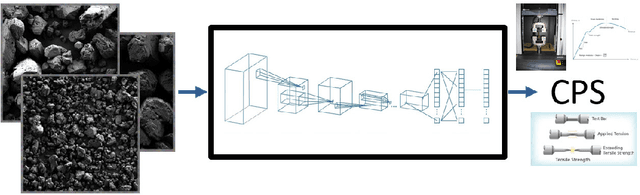
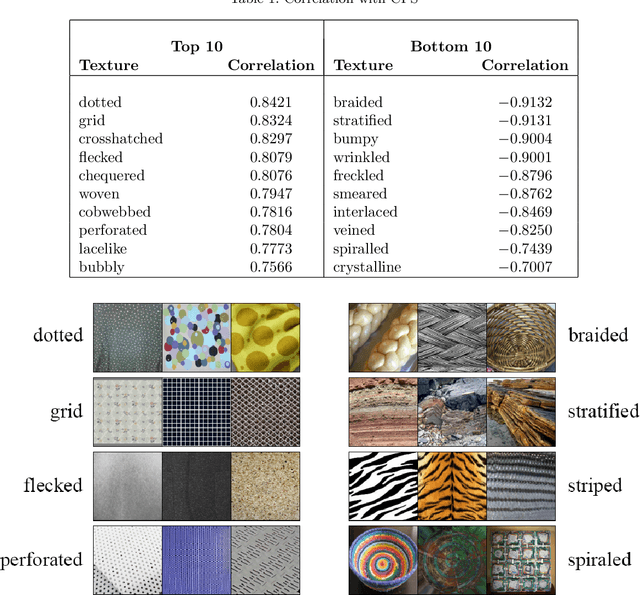


We recently developed a deep learning method that can determine the critical peak stress of a material by looking at scanning electron microscope (SEM) images of the material's crystals. However, it has been somewhat unclear what kind of image features the network is keying off of when it makes its prediction. It is common in computer vision to employ an explainable AI saliency map to tell one what parts of an image are important to the network's decision. One can usually deduce the important features by looking at these salient locations. However, SEM images of crystals are more abstract to the human observer than natural image photographs. As a result, it is not easy to tell what features are important at the locations which are most salient. To solve this, we developed a method that helps us map features from important locations in SEM images to non-abstract textures that are easier to interpret.
Improving exploration in policy gradient search: Application to symbolic optimization
Jul 19, 2021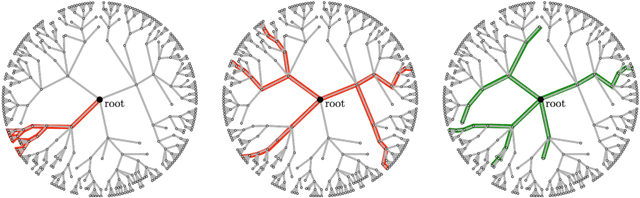
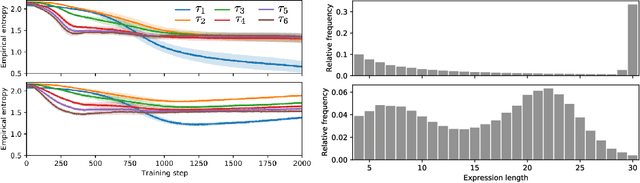
Many machine learning strategies designed to automate mathematical tasks leverage neural networks to search large combinatorial spaces of mathematical symbols. In contrast to traditional evolutionary approaches, using a neural network at the core of the search allows learning higher-level symbolic patterns, providing an informed direction to guide the search. When no labeled data is available, such networks can still be trained using reinforcement learning. However, we demonstrate that this approach can suffer from an early commitment phenomenon and from initialization bias, both of which limit exploration. We present two exploration methods to tackle these issues, building upon ideas of entropy regularization and distribution initialization. We show that these techniques can improve the performance, increase sample efficiency, and lower the complexity of solutions for the task of symbolic regression.
* Published in 1st Mathematical Reasoning in General Artificial Intelligence Workshop, ICLR 2021
Efficient Saliency Maps for Explainable AI
Nov 26, 2019
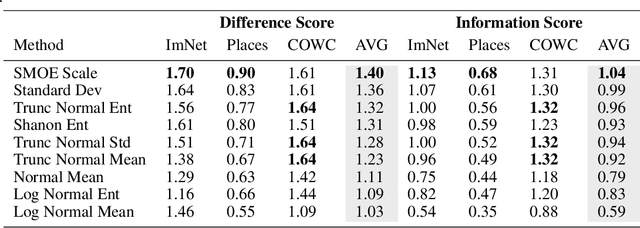

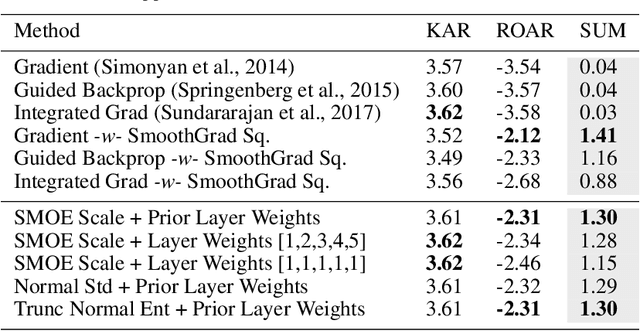
We describe an explainable AI saliency map method for use with deep convolutional neural networks (CNN) that is much more efficient than popular gradient methods. It is also quantitatively similar and better in accuracy. Our technique works by measuring information at the end of each network scale which is then combined into a single saliency map. We describe how saliency measures can be made more efficient by exploiting Saliency Map Order Equivalence. Finally, we visualize individual scale/layer contributions by using a Layer Ordered Visualization of Information. This provides an interesting comparison of scale information contributions within the network not provided by other saliency map methods. Since our method only requires a single forward pass through a few of the layers in a network, it is at least 97x faster than Guided Backprop and much more accurate. Using our method instead of Guided Backprop, class activation methods such as Grad-CAM, Grad-CAM++ and Smooth Grad-CAM++ will run several orders of magnitude faster, have a significantly smaller memory footprint and be more accurate. This will make such methods feasible on resource limited platforms such as robots, cell phones and low cost industrial devices. This will also significantly help them work in extremely data intensive applications such as satellite image processing. All without sacrificing accuracy. Our method is generally straight forward and should be applicable to the most commonly used CNNs. We also show examples of our method used to enhance Grad-CAM++.
Improvements to context based self-supervised learning
Mar 28, 2018
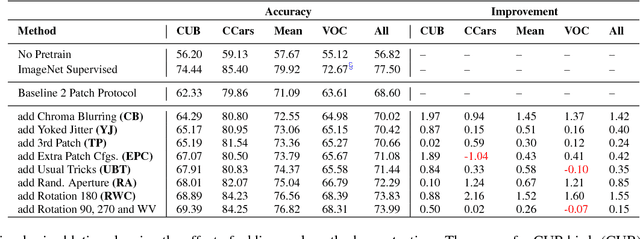

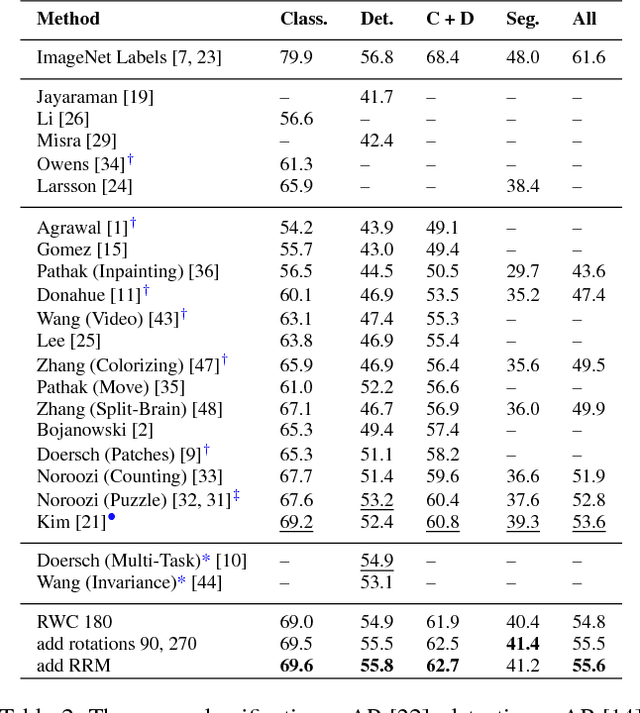
We develop a set of methods to improve on the results of self-supervised learning using context. We start with a baseline of patch based arrangement context learning and go from there. Our methods address some overt problems such as chromatic aberration as well as other potential problems such as spatial skew and mid-level feature neglect. We prevent problems with testing generalization on common self-supervised benchmark tests by using different datasets during our development. The results of our methods combined yield top scores on all standard self-supervised benchmarks, including classification and detection on PASCAL VOC 2007, segmentation on PASCAL VOC 2012, and "linear tests" on the ImageNet and CSAIL Places datasets. We obtain an improvement over our baseline method of between 4.0 to 7.1 percentage points on transfer learning classification tests. We also show results on different standard network architectures to demonstrate generalization as well as portability. All data, models and programs are available at: https://gdo-datasci.llnl.gov/selfsupervised/.
A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning
Sep 14, 2016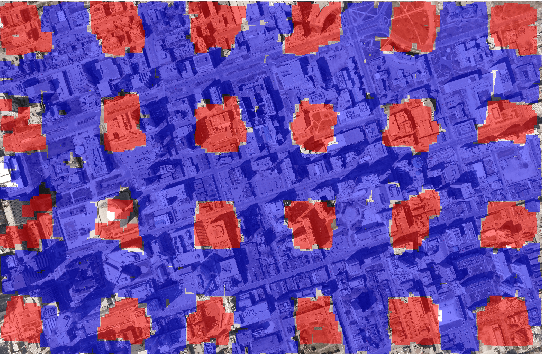



We have created a large diverse set of cars from overhead images, which are useful for training a deep learner to binary classify, detect and count them. The dataset and all related material will be made publically available. The set contains contextual matter to aid in identification of difficult targets. We demonstrate classification and detection on this dataset using a neural network we call ResCeption. This network combines residual learning with Inception-style layers and is used to count cars in one look. This is a new way to count objects rather than by localization or density estimation. It is fairly accurate, fast and easy to implement. Additionally, the counting method is not car or scene specific. It would be easy to train this method to count other kinds of objects and counting over new scenes requires no extra set up or assumptions about object locations.