 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Saliency Maps for Explainable AI
Nov 26, 2019
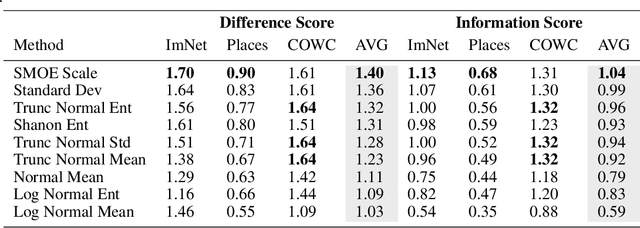

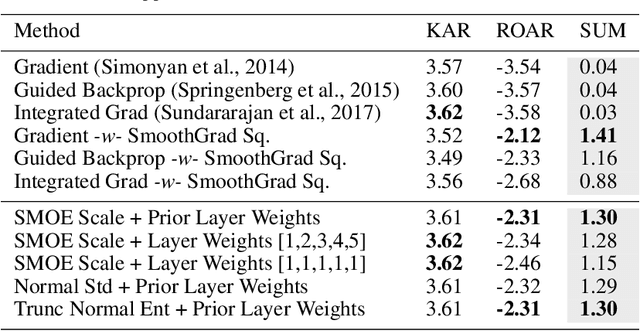
We describe an explainable AI saliency map method for use with deep convolutional neural networks (CNN) that is much more efficient than popular gradient methods. It is also quantitatively similar and better in accuracy. Our technique works by measuring information at the end of each network scale which is then combined into a single saliency map. We describe how saliency measures can be made more efficient by exploiting Saliency Map Order Equivalence. Finally, we visualize individual scale/layer contributions by using a Layer Ordered Visualization of Information. This provides an interesting comparison of scale information contributions within the network not provided by other saliency map methods. Since our method only requires a single forward pass through a few of the layers in a network, it is at least 97x faster than Guided Backprop and much more accurate. Using our method instead of Guided Backprop, class activation methods such as Grad-CAM, Grad-CAM++ and Smooth Grad-CAM++ will run several orders of magnitude faster, have a significantly smaller memory footprint and be more accurate. This will make such methods feasible on resource limited platforms such as robots, cell phones and low cost industrial devices. This will also significantly help them work in extremely data intensive applications such as satellite image processing. All without sacrificing accuracy. Our method is generally straight forward and should be applicable to the most commonly used CNNs. We also show examples of our method used to enhance Grad-CAM++.
Improvements to context based self-supervised learning
Mar 28, 2018
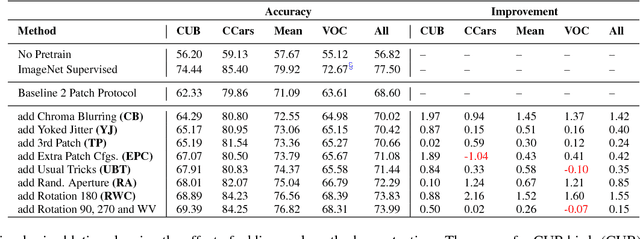

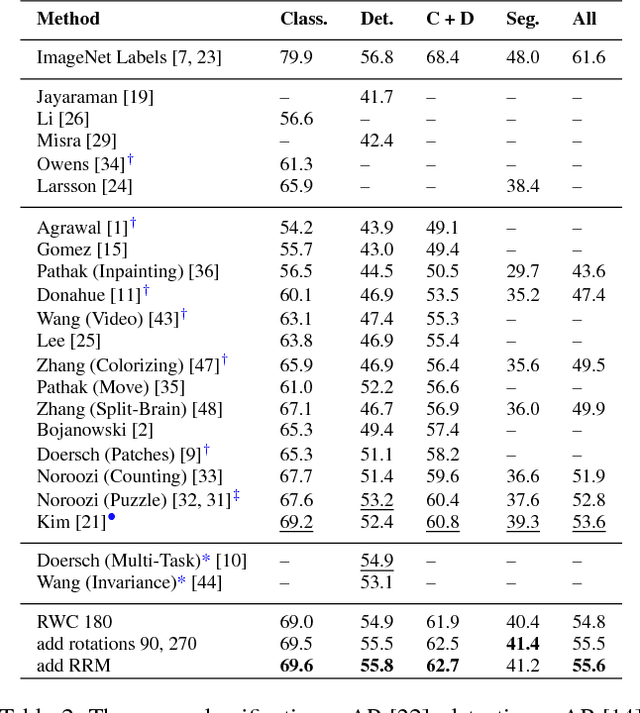
We develop a set of methods to improve on the results of self-supervised learning using context. We start with a baseline of patch based arrangement context learning and go from there. Our methods address some overt problems such as chromatic aberration as well as other potential problems such as spatial skew and mid-level feature neglect. We prevent problems with testing generalization on common self-supervised benchmark tests by using different datasets during our development. The results of our methods combined yield top scores on all standard self-supervised benchmarks, including classification and detection on PASCAL VOC 2007, segmentation on PASCAL VOC 2012, and "linear tests" on the ImageNet and CSAIL Places datasets. We obtain an improvement over our baseline method of between 4.0 to 7.1 percentage points on transfer learning classification tests. We also show results on different standard network architectures to demonstrate generalization as well as portability. All data, models and programs are available at: https://gdo-datasci.llnl.gov/selfsupervised/.