 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining neural network predictions of material strength
Nov 05, 2021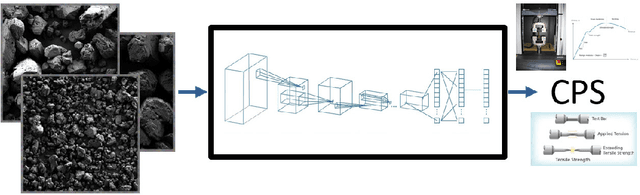
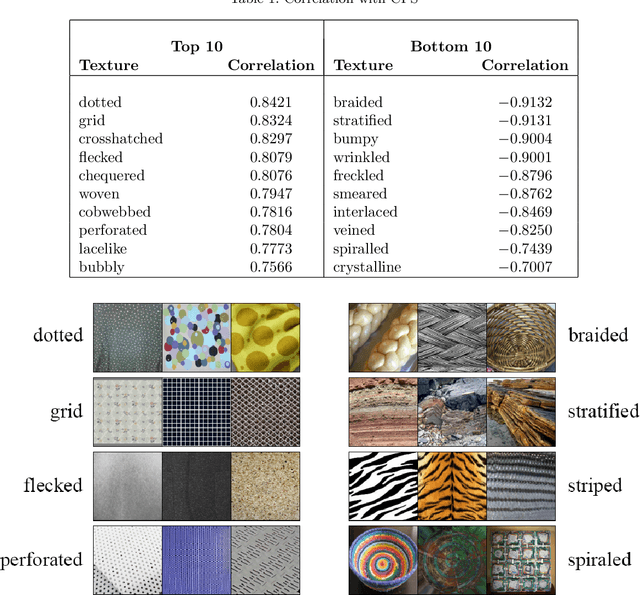


We recently developed a deep learning method that can determine the critical peak stress of a material by looking at scanning electron microscope (SEM) images of the material's crystals. However, it has been somewhat unclear what kind of image features the network is keying off of when it makes its prediction. It is common in computer vision to employ an explainable AI saliency map to tell one what parts of an image are important to the network's decision. One can usually deduce the important features by looking at these salient locations. However, SEM images of crystals are more abstract to the human observer than natural image photographs. As a result, it is not easy to tell what features are important at the locations which are most salient. To solve this, we developed a method that helps us map features from important locations in SEM images to non-abstract textures that are easier to interpret.
Reliable and Explainable Machine Learning Methods for Accelerated Material Discovery
Jan 05, 2019
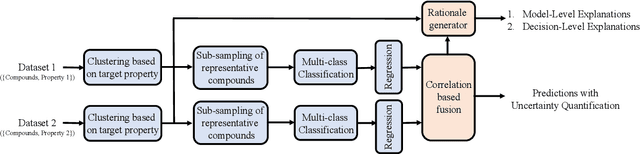
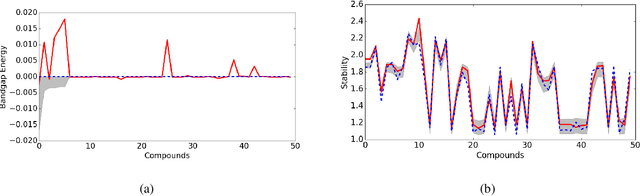
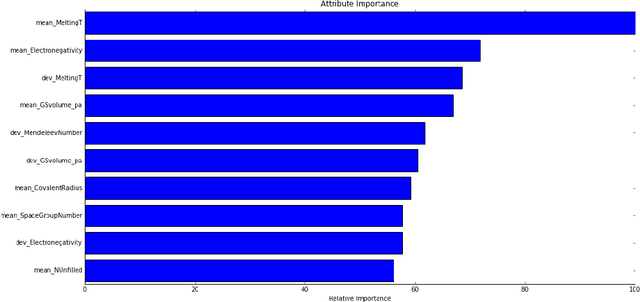
Material scientists are increasingly adopting the use of machine learning (ML) for making potentially important decisions, such as, discovery, development, optimization, synthesis and characterization of materials. However, despite ML's impressive performance in commercial applications, several unique challenges exist when applying ML in materials science applications. In such a context, the contributions of this work are twofold. First, we identify common pitfalls of existing ML techniques when learning from underrepresented/imbalanced material data. Specifically, we show that with imbalanced data, standard methods for assessing quality of ML models break down and lead to misleading conclusions. Furthermore, we found that the model's own confidence score cannot be trusted and model introspection methods (using simpler models) do not help as they result in loss of predictive performance (reliability-explainability trade-off). Second, to overcome these challenges, we propose a general-purpose explainable and reliable machine-learning framework. Specifically, we propose a novel pipeline that employs an ensemble of simpler models to reliably predict material properties. We also propose a transfer learning technique and show that the performance loss due to models' simplicity can be overcome by exploiting correlations among different material properties. A new evaluation metric and a trust score to better quantify the confidence in the predictions are also proposed. To improve the interpretability, we add a rationale generator component to our framework which provides both model-level and decision-level explanations. Finally, we demonstrate the versatility of our technique on two applications: 1) predicting properties of crystalline compounds, and 2) identifying novel potentially stable solar cell materials.
Network Structure Inference, A Survey: Motivations, Methods, and Applications
Jan 19, 2018

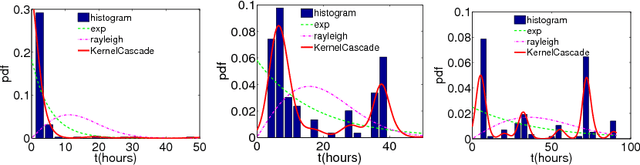

Networks represent relationships between entities in many complex systems, spanning from online social interactions to biological cell development and brain connectivity. In many cases, relationships between entities are unambiguously known: are two users 'friends' in a social network? Do two researchers collaborate on a published paper? Do two road segments in a transportation system intersect? These are directly observable in the system in question. In most cases, relationship between nodes are not directly observable and must be inferred: does one gene regulate the expression of another? Do two animals who physically co-locate have a social bond? Who infected whom in a disease outbreak in a population? Existing approaches for inferring networks from data are found across many application domains and use specialized knowledge to infer and measure the quality of inferred network for a specific task or hypothesis. However, current research lacks a rigorous methodology which employs standard statistical validation on inferred models. In this survey, we examine (1) how network representations are constructed from underlying data, (2) the variety of questions and tasks on these representations over several domains, and (3) validation strategies for measuring the inferred network's capability of answering questions on the system of interest.
Size-Consistent Statistics for Anomaly Detection in Dynamic Networks
Aug 02, 2016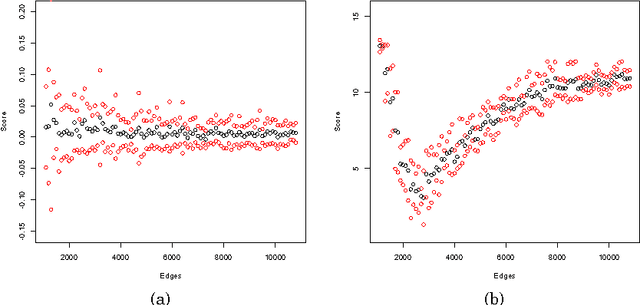
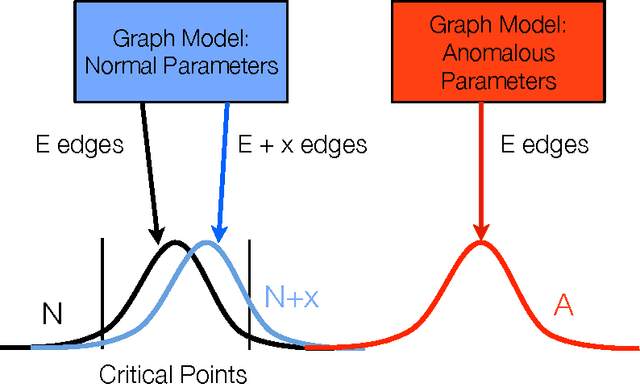

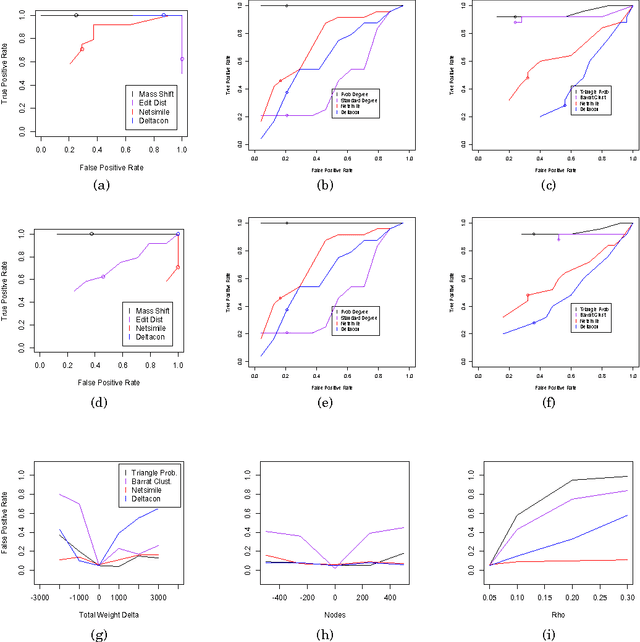
An important task in network analysis is the detection of anomalous events in a network time series. These events could merely be times of interest in the network timeline or they could be examples of malicious activity or network malfunction. Hypothesis testing using network statistics to summarize the behavior of the network provides a robust framework for the anomaly detection decision process. Unfortunately, choosing network statistics that are dependent on confounding factors like the total number of nodes or edges can lead to incorrect conclusions (e.g., false positives and false negatives). In this dissertation we describe the challenges that face anomaly detection in dynamic network streams regarding confounding factors. We also provide two solutions to avoiding error due to confounding factors: the first is a randomization testing method that controls for confounding factors, and the second is a set of size-consistent network statistics which avoid confounding due to the most common factors, edge count and node count.
Spotting Suspicious Link Behavior with fBox: An Adversarial Perspective
Oct 15, 2014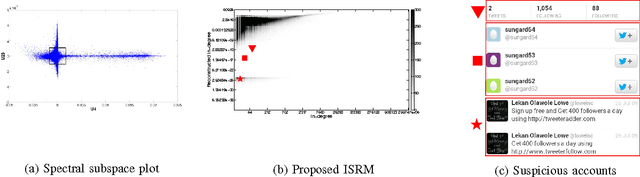
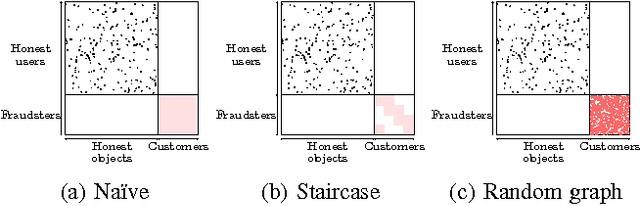

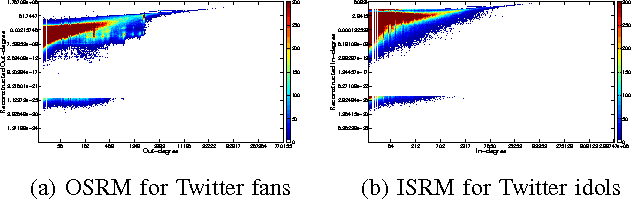
How can we detect suspicious users in large online networks? Online popularity of a user or product (via follows, page-likes, etc.) can be monetized on the premise of higher ad click-through rates or increased sales. Web services and social networks which incentivize popularity thus suffer from a major problem of fake connections from link fraudsters looking to make a quick buck. Typical methods of catching this suspicious behavior use spectral techniques to spot large groups of often blatantly fraudulent (but sometimes honest) users. However, small-scale, stealthy attacks may go unnoticed due to the nature of low-rank eigenanalysis used in practice. In this work, we take an adversarial approach to find and prove claims about the weaknesses of modern, state-of-the-art spectral methods and propose fBox, an algorithm designed to catch small-scale, stealth attacks that slip below the radar. Our algorithm has the following desirable properties: (a) it has theoretical underpinnings, (b) it is shown to be highly effective on real data and (c) it is scalable (linear on the input size). We evaluate fBox on a large, public 41.7 million node, 1.5 billion edge who-follows-whom social graph from Twitter in 2010 and with high precision identify many suspicious accounts which have persisted without suspension even to this day.
Dynamic Behavioral Mixed-Membership Model for Large Evolving Networks
May 09, 2012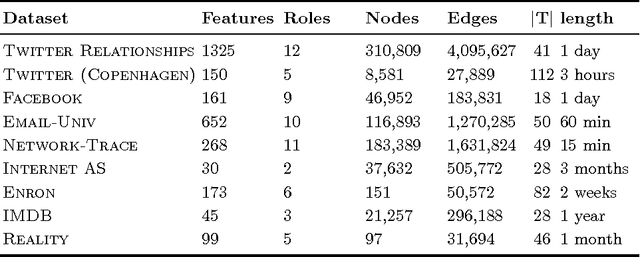
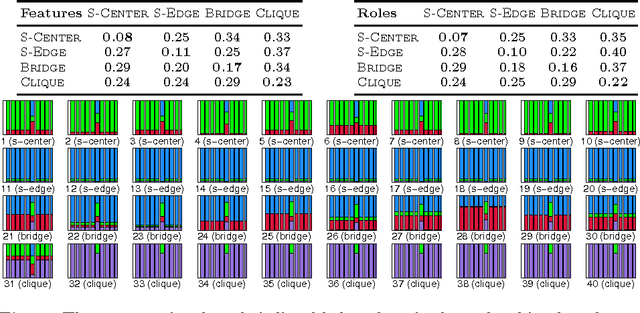
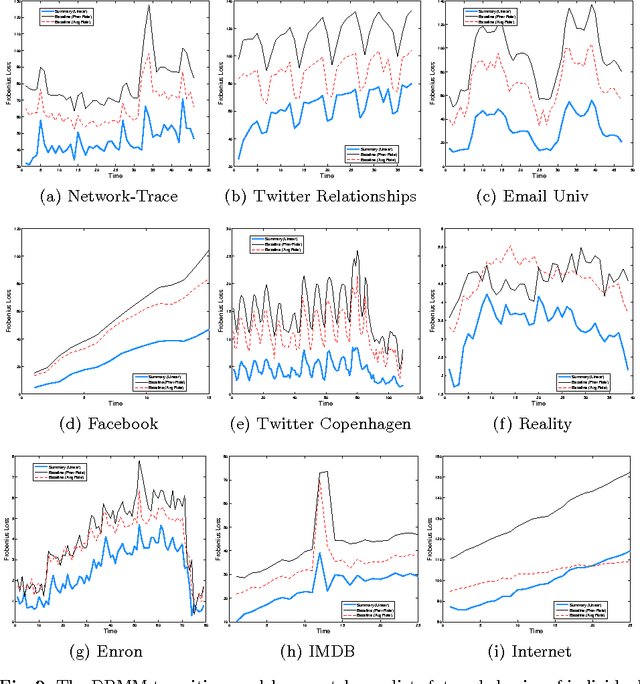
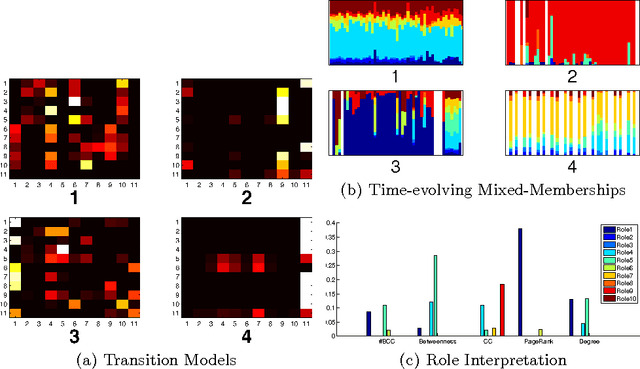
The majority of real-world networks are dynamic and extremely large (e.g., Internet Traffic, Twitter, Facebook, ...). To understand the structural behavior of nodes in these large dynamic networks, it may be necessary to model the dynamics of behavioral roles representing the main connectivity patterns over time. In this paper, we propose a dynamic behavioral mixed-membership model (DBMM) that captures the roles of nodes in the graph and how they evolve over time. Unlike other node-centric models, our model is scalable for analyzing large dynamic networks. In addition, DBMM is flexible, parameter-free, has no functional form or parameterization, and is interpretable (identifies explainable patterns). The performance results indicate our approach can be applied to very large networks while the experimental results show that our model uncovers interesting patterns underlying the dynamics of these networks.
Role-Dynamics: Fast Mining of Large Dynamic Networks
Mar 09, 2012
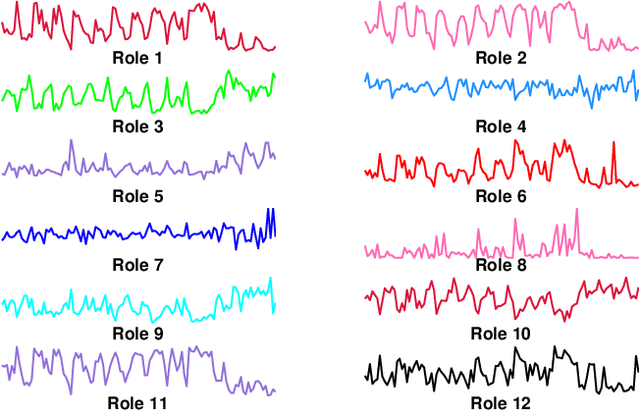
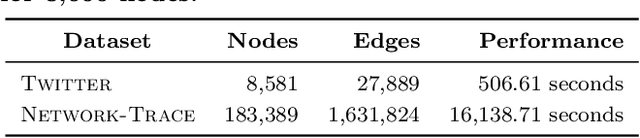

To understand the structural dynamics of a large-scale social, biological or technological network, it may be useful to discover behavioral roles representing the main connectivity patterns present over time. In this paper, we propose a scalable non-parametric approach to automatically learn the structural dynamics of the network and individual nodes. Roles may represent structural or behavioral patterns such as the center of a star, peripheral nodes, or bridge nodes that connect different communities. Our novel approach learns the appropriate structural role dynamics for any arbitrary network and tracks the changes over time. In particular, we uncover the specific global network dynamics and the local node dynamics of a technological, communication, and social network. We identify interesting node and network patterns such as stationary and non-stationary roles, spikes/steps in role-memberships (perhaps indicating anomalies), increasing/decreasing role trends, among many others. Our results indicate that the nodes in each of these networks have distinct connectivity patterns that are non-stationary and evolve considerably over time. Overall, the experiments demonstrate the effectiveness of our approach for fast mining and tracking of the dynamics in large networks. Furthermore, the dynamic structural representation provides a basis for building more sophisticated models and tools that are fast for exploring large dynamic networks.