 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Explainable Machine Learning Methods for Accelerated Material Discovery
Paper and Code
Jan 05, 2019
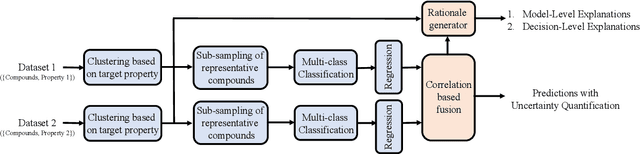
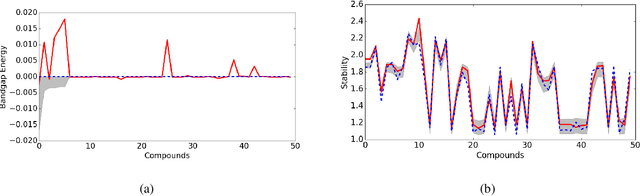
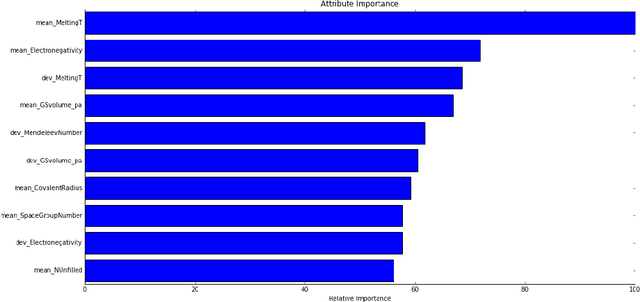
Material scientists are increasingly adopting the use of machine learning (ML) for making potentially important decisions, such as, discovery, development, optimization, synthesis and characterization of materials. However, despite ML's impressive performance in commercial applications, several unique challenges exist when applying ML in materials science applications. In such a context, the contributions of this work are twofold. First, we identify common pitfalls of existing ML techniques when learning from underrepresented/imbalanced material data. Specifically, we show that with imbalanced data, standard methods for assessing quality of ML models break down and lead to misleading conclusions. Furthermore, we found that the model's own confidence score cannot be trusted and model introspection methods (using simpler models) do not help as they result in loss of predictive performance (reliability-explainability trade-off). Second, to overcome these challenges, we propose a general-purpose explainable and reliable machine-learning framework. Specifically, we propose a novel pipeline that employs an ensemble of simpler models to reliably predict material properties. We also propose a transfer learning technique and show that the performance loss due to models' simplicity can be overcome by exploiting correlations among different material properties. A new evaluation metric and a trust score to better quantify the confidence in the predictions are also proposed. To improve the interpretability, we add a rationale generator component to our framework which provides both model-level and decision-level explanations. Finally, we demonstrate the versatility of our technique on two applications: 1) predicting properties of crystalline compounds, and 2) identifying novel potentially stable solar cell materials.