 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHotSpotter - Patterned Species Instance Recognition
Aug 25, 2025



We present HotSpotter, a fast, accurate algorithm for identifying individual animals against a labeled database. It is not species specific and has been applied to Grevy's and plains zebras, giraffes, leopards, and lionfish. We describe two approaches, both based on extracting and matching keypoints or "hotspots". The first tests each new query image sequentially against each database image, generating a score for each database image in isolation, and ranking the results. The second, building on recent techniques for instance recognition, matches the query image against the database using a fast nearest neighbor search. It uses a competitive scoring mechanism derived from the Local Naive Bayes Nearest Neighbor algorithm recently proposed for category recognition. We demonstrate results on databases of more than 1000 images, producing more accurate matches than published methods and matching each query image in just a few seconds.
* Original matlab code: https://github.com/Erotemic/hotspotter-matlab-2013, Python port: https://github.com/Erotemic/hotspotter
Adapting the re-ID challenge for static sensors
Nov 30, 2024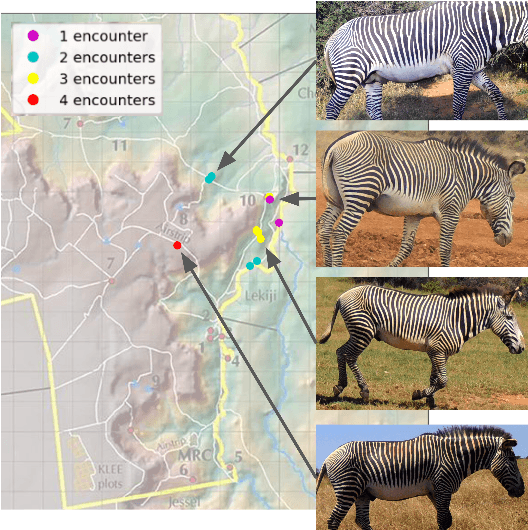
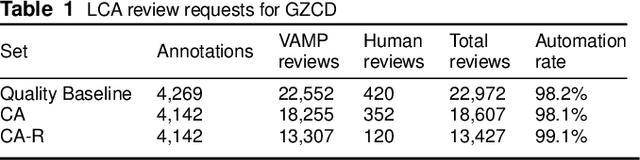
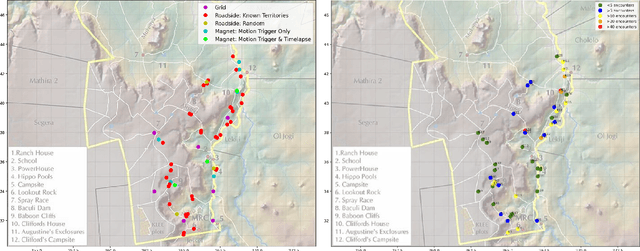
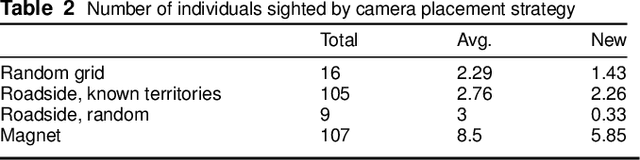
In both 2016 and 2018, a census of the highly-endangered Grevy's zebra population was enabled by the Great Grevy's Rally (GGR), a citizen science event that produces population estimates via expert and algorithmic curation of volunteer-captured images. A complementary, scalable, and long-term Grevy's population monitoring approach involves deploying camera trap networks. However, in both scenarios, a substantial majority of zebra images are not usable for individual identification due to poor in-the-wild imaging conditions; camera trap images in particular present high rates of occlusion and high spatio-temporal similarity within image bursts. Our proposed filtering pipeline incorporates animal detection, species identification, viewpoint estimation, quality evaluation, and temporal subsampling to obtain individual crops suitable for re-ID, which are subsequently curated by the LCA decision management algorithm. Our method processed images taken during GGR-16 and GGR-18 in Meru County, Kenya, into 4,142 highly-comparable annotations, requiring only 120 contrastive human decisions to produce a population estimate within 4.6% of the ground-truth count. Our method also efficiently processed 8.9M unlabeled camera trap images from 70 cameras at the Mpala Research Centre in Laikipia County, Kenya over two years into 685 encounters of 173 individuals, requiring only 331 contrastive human decisions.
The Animal ID Problem: Continual Curation
Jun 18, 2021
Hoping to stimulate new research in individual animal identification from images, we propose to formulate the problem as the human-machine Continual Curation of images and animal identities. This is an open world recognition problem, where most new animals enter the system after its algorithms are initially trained and deployed. Continual Curation, as defined here, requires (1) an improvement in the effectiveness of current recognition methods, (2) a pairwise verification algorithm that allows the possibility of no decision, and (3) an algorithmic decision mechanism that seeks human input to guide the curation process. Error metrics must evaluate the ability of recognition algorithms to identify not only animals that have been seen just once or twice but also recognize new animals not in the database. An important measure of overall system performance is accuracy as a function of the amount of human input required.
Mining and modeling complex leadership-followership dynamics of movement data
Oct 04, 2020
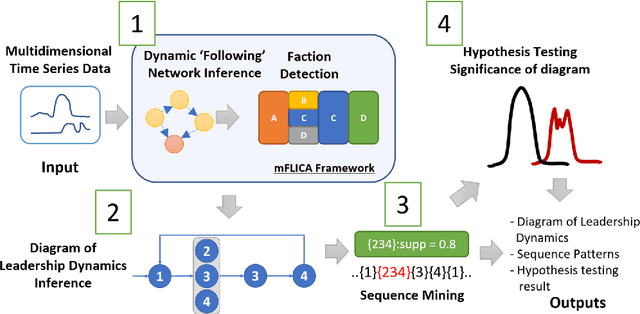

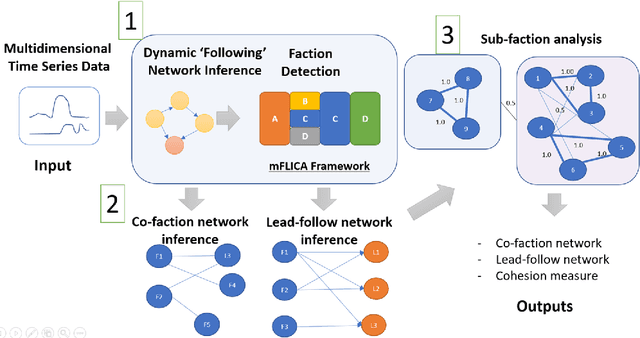
Leadership and followership are essential parts of collective decision and organization in social animals, including humans. In nature, relationships of leaders and followers are dynamic and vary with context or temporal factors. Understanding dynamics of leadership and followership, such as how leaders and followers change, emerge, or converge, allows scientists to gain more insight into group decision-making and collective behavior in general. However, given only data of individual activities, it is challenging to infer the dynamics of leaders and followers. In this paper, we focus on mining and modeling frequent patterns of leading and following. We formalize new computational problems and propose a framework that can be used to address several questions regarding group movement. We use the leadership inference framework, mFLICA, to infer the time series of leaders and their factions from movement datasets and then propose an approach to mine and model frequent patterns of both leadership and followership dynamics. We evaluate our framework performance by using several simulated datasets, as well as the real-world dataset of baboon movement to demonstrate the applications of our framework. These are novel computational problems and, to the best of our knowledge, there are no existing comparable methods to address them. Thus, we modify and extend an existing leadership inference framework to provide a non-trivial baseline for comparison. Our framework performs better than this baseline in all datasets. Our framework opens the opportunities for scientists to generate testable scientific hypotheses about the dynamics of leadership in movement data.
* This accepted manuscript is made publicly available 12 months after official publication, which is complied with the publisher policy. The final publication is available at link.springer.com
Inferring Network Structure From Data
Apr 04, 2020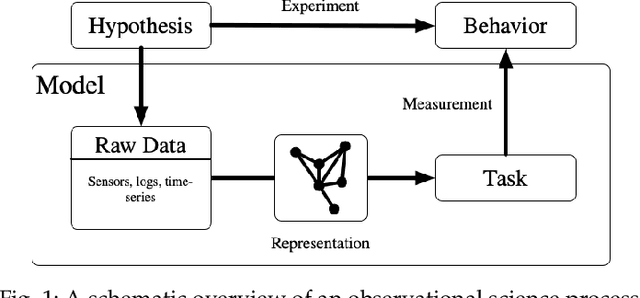
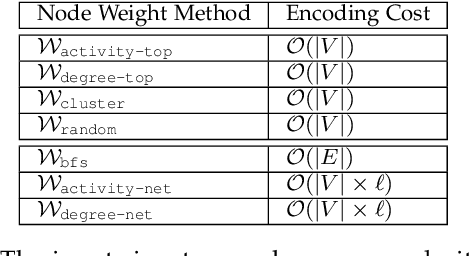
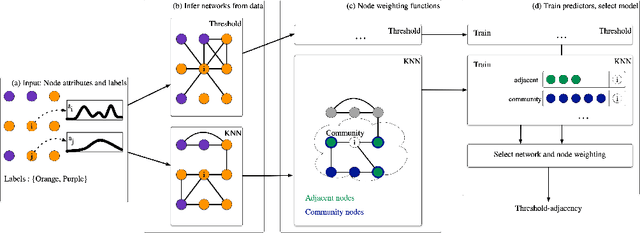
Networks are complex models for underlying data in many application domains. In most instances, raw data is not natively in the form of a network, but derived from sensors, logs, images, or other data. Yet, the impact of the various choices in translating this data to a network have been largely unexamined. In this work, we propose a network model selection methodology that focuses on evaluating a network's utility for varying tasks, together with an efficiency measure which selects the most parsimonious model. We demonstrate that this network definition matters in several ways for modeling the behavior of the underlying system.
Variable-lag Granger Causality for Time Series Analysis
Dec 18, 2019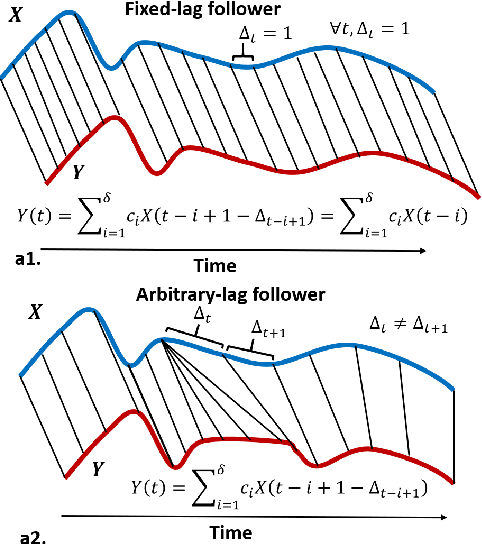
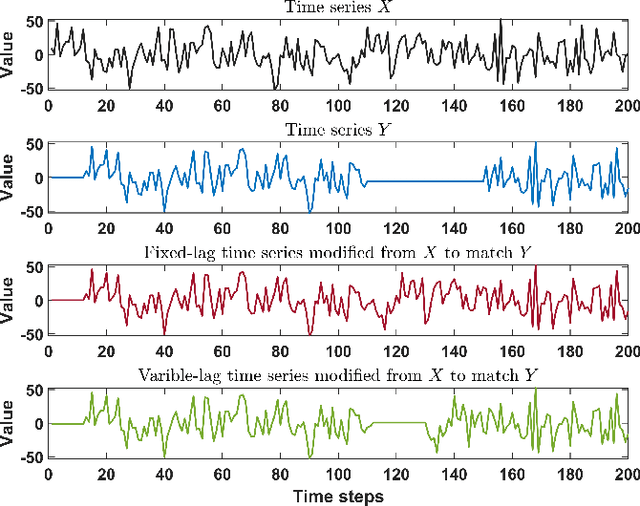

Granger causality is a fundamental technique for causal inference in time series data, commonly used in the social and biological sciences. Typical operationalizations of Granger causality make a strong assumption that every time point of the effect time series is influenced by a combination of other time series with a fixed time delay. However, the assumption of the fixed time delay does not hold in many applications, such as collective behavior, financial markets, and many natural phenomena. To address this issue, we develop variable-lag Granger causality, a generalization of Granger causality that relaxes the assumption of the fixed time delay and allows causes to influence effects with arbitrary time delays. In addition, we propose a method for inferring variable-lag Granger causality relations. We demonstrate our approach on an application for studying coordinated collective behavior and show that it performs better than several existing methods in both simulated and real-world datasets. Our approach can be applied in any domain of time series analysis.
Network Structure Inference, A Survey: Motivations, Methods, and Applications
Jan 19, 2018

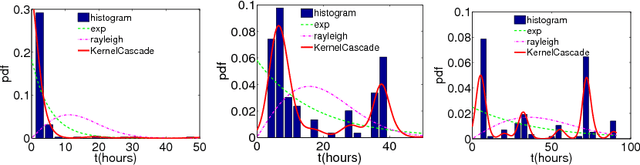

Networks represent relationships between entities in many complex systems, spanning from online social interactions to biological cell development and brain connectivity. In many cases, relationships between entities are unambiguously known: are two users 'friends' in a social network? Do two researchers collaborate on a published paper? Do two road segments in a transportation system intersect? These are directly observable in the system in question. In most cases, relationship between nodes are not directly observable and must be inferred: does one gene regulate the expression of another? Do two animals who physically co-locate have a social bond? Who infected whom in a disease outbreak in a population? Existing approaches for inferring networks from data are found across many application domains and use specialized knowledge to infer and measure the quality of inferred network for a specific task or hypothesis. However, current research lacks a rigorous methodology which employs standard statistical validation on inferred models. In this survey, we examine (1) how network representations are constructed from underlying data, (2) the variety of questions and tasks on these representations over several domains, and (3) validation strategies for measuring the inferred network's capability of answering questions on the system of interest.
Network Model Selection Using Task-Focused Minimum Description Length
Jan 11, 2018
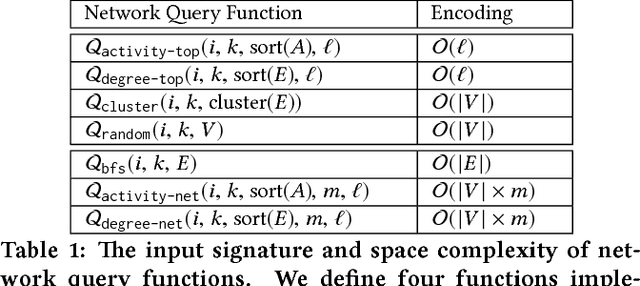


Networks are fundamental models for data used in practically every application domain. In most instances, several implicit or explicit choices about the network definition impact the translation of underlying data to a network representation, and the subsequent question(s) about the underlying system being represented. Users of downstream network data may not even be aware of these choices or their impacts. We propose a task-focused network model selection methodology which addresses several key challenges. Our approach constructs network models from underlying data and uses minimum description length (MDL) criteria for selection. Our methodology measures efficiency, a general and comparable measure of the network's performance of a local (i.e. node-level) predictive task of interest. Selection on efficiency favors parsimonious (e.g. sparse) models to avoid overfitting and can be applied across arbitrary tasks and representations. We show stability, sensitivity, and significance testing in our methodology.
Network Model Selection for Task-Focused Attributed Network Inference
Sep 16, 2017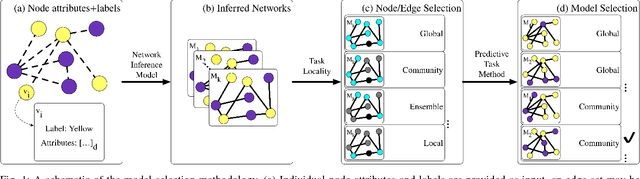
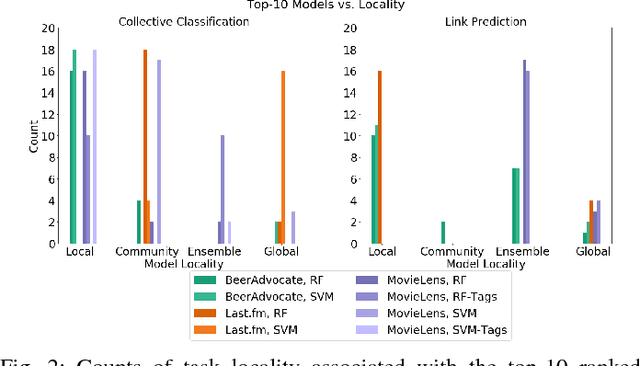
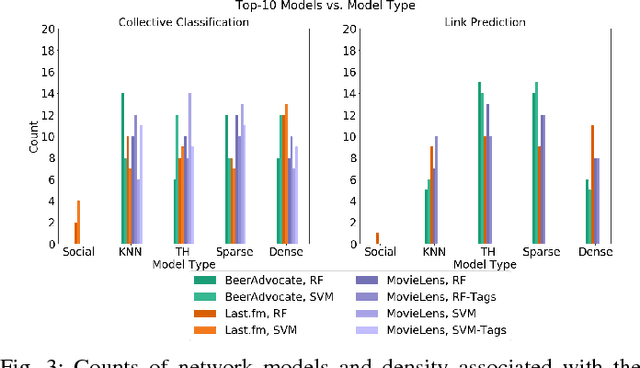
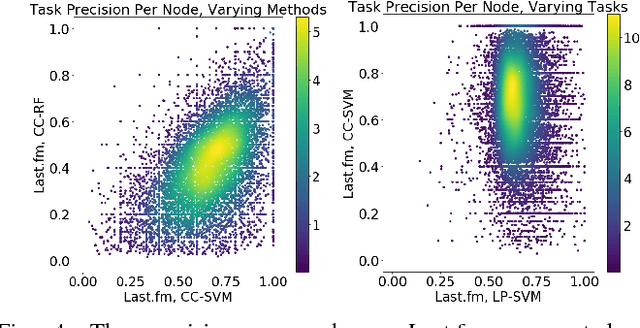
Networks are models representing relationships between entities. Often these relationships are explicitly given, or we must learn a representation which generalizes and predicts observed behavior in underlying individual data (e.g. attributes or labels). Whether given or inferred, choosing the best representation affects subsequent tasks and questions on the network. This work focuses on model selection to evaluate network representations from data, focusing on fundamental predictive tasks on networks. We present a modular methodology using general, interpretable network models, task neighborhood functions found across domains, and several criteria for robust model selection. We demonstrate our methodology on three online user activity datasets and show that network model selection for the appropriate network task vs. an alternate task increases performance by an order of magnitude in our experiments.
Evaluating Social Networks Using Task-Focused Network Inference
Jul 08, 2017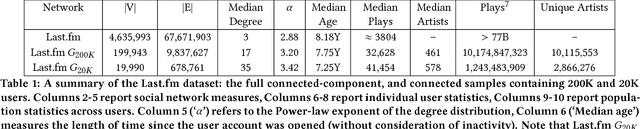
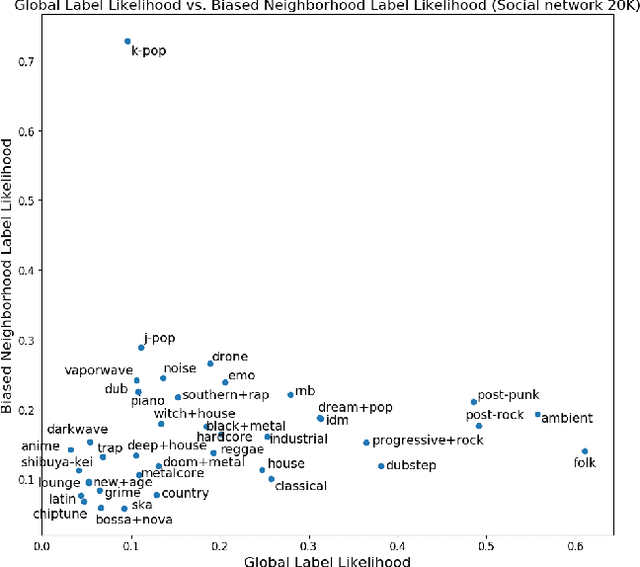
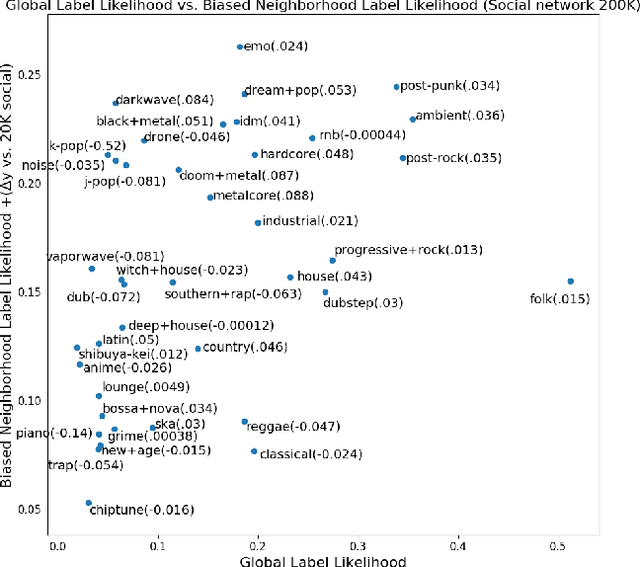
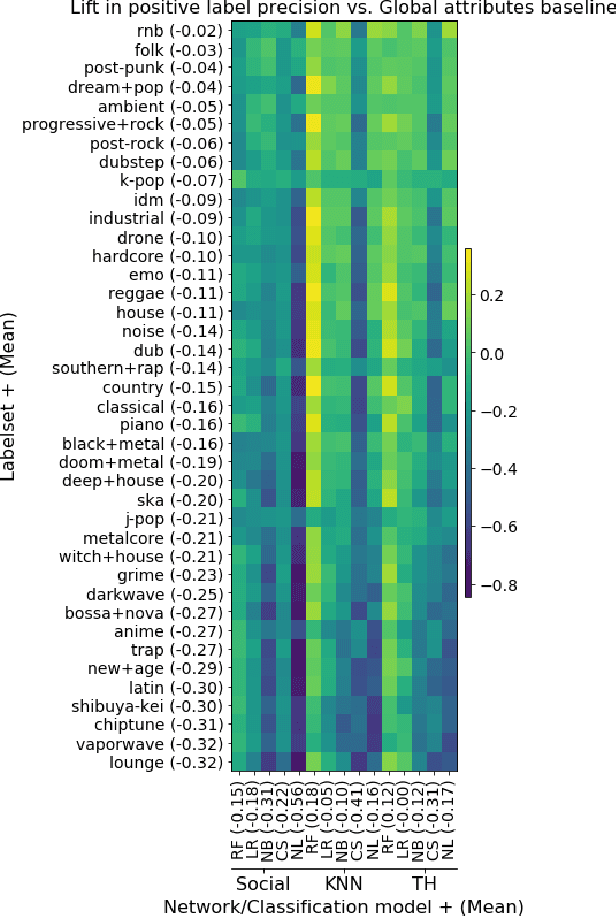
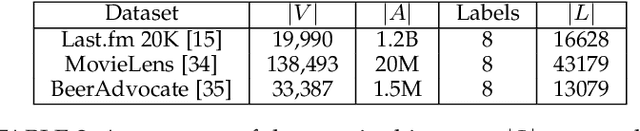
Networks are representations of complex underlying social processes. However, the same given network may be more suitable to model one behavior of individuals than another. In many cases, aggregate population models may be more effective than modeling on the network. We present a general framework for evaluating the suitability of given networks for a set of predictive tasks of interest, compared against alternative, networks inferred from data. We present several interpretable network models and measures for our comparison. We apply this general framework to the case study on collective classification of music preferences in a newly available dataset of the Last.fm social network.